Price-performance benchmark Apache Druid and Google BigQuery
Jun 25, 2020
Rick Bilodeau
Summary
To fully capitalize on the troves of data made available through digital transformation efforts, businesses need to provide self-service analytics to hundreds or thousands of front-line decision makers. Understandably, many would like to use their cloud data warehouse for this type of use case, which we call “hot analytics“. While data warehouses are excellent at many things, they are not architected for hot analytics use cases, which are characterized by iterative, ad hoc queries against large data sets at high query concurrency.
Imply was purpose-built for this type of workload. To assess its performance, we recently benchmarked the performance and cost of Google BigQuery, a popular cloud data warehouse, against that of Apache Druid, the real-time analytics database at the core of Imply.
The test indicates that Apache Druid delivers 3 times the speed and 12 times the price-performance of Google BigQuery. Druid responds to queries 3.1 times faster than BigQuery on average and performs faster for every query tested; up to 14.3 times faster. If you normalize the cluster size to provide the same performance, Druid costs 8% as much as BigQuery. This leads to substantial dollar savings. For 128 concurrent queries running continually, the monthly estimated costs are $212,500 for BigQuery compared to $17,900 for Druid.
The test used the star schema benchmark (SSB) and a 100GB data set. We believe that this advantage would grow using Imply Pivot as the visual UI for Druid vs. a popular BI interface such as Looker or Tableau as the front-end for BigQuery. Pivot was purpose-built for ad hoc queries; the others are designed to deliver recurring queries that populate dashboards and static reports.
The results can be explained by comparing the architectures of the two systems. BigQuery separates storage and compute to allow for instant elasticity; Druid combines them to improve speed. BigQuery has no secondary indexes or data tiering so as to simplify management, Druid provides both, allowing the customer to optimize performance.
Based on these results, customers should consider offloading self-service analytics use cases from BigQuery to a Druid-based system such as Imply, which uses Druid as a processing engine to deliver a real-time data platform for self-service analytics.
We expect Druid’s performance advantage would hold against other cloud data warehouses, such as AWS Redshift, Azure Synapse Analytics or Snowflake, as they are all similarly architected and have shown similar performance to one another in previous benchmarks.
Rationale and test method
Cloud data warehouses have become a popular replacement for enterprise data warehouses due to their management simplicity, elasticity, and cost advantages. Examples include offerings from the top 3 cloud platforms – AWS Redshift, Azure Synapse Analytics, Google BigQuery – plus Snowflake Data Warehouse. Google BigQuery has received a lot of market attention lately, so we thought it would be informative to see how its performance and cost compares to Apache Druid.
For the test we used the Star Schema Benchmark (SSB), which is a dataset and query set designed to evaluate performance of data warehouses over the past decade. The performance results of 13 standard SQL queries allows for comparison across products and configurations.
For this benchmark, 600 million rows (approximately 100GB) of test data were generated, using SSB’s dbgen, and executed locally. Dbgen was executed with a Scale Factor of 1 (SF=1) to generate a lineorder table with 6,000,000 rows.
Each of the 13 queries were run 10 times in each test flight, and there were 5 flight runs. Results were averaged per flight run, then per standard benchmark practices, the fastest and slowest results were considered outliers and discarded before analyzing the results. The remaining results were averaged to provide a final result.
To compare infrastructure costs, Druid was run using Imply Cloud with JMeter servers running on AWS instances, while BigQuery was tested with JMeter running on Google Cloud Platform.
Findings
Performance
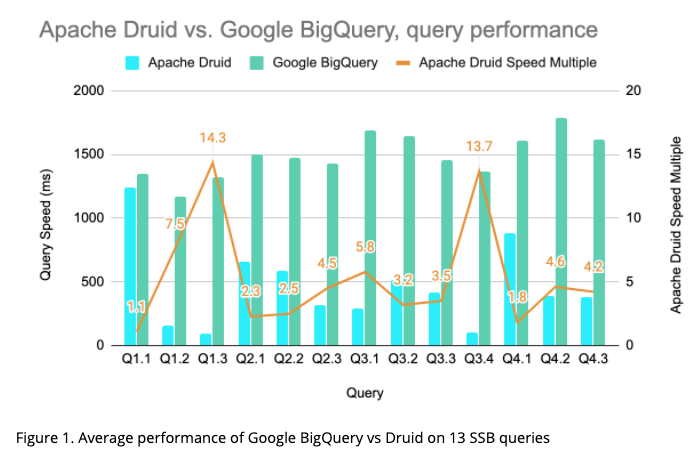
The overall SSB test results for Druid and BigQuery, shown below, indicate that Druid performed faster on all 13 queries. The performance advantage ranged from 1.1x faster for query 1.1 to 14.3x faster for query 1.3. For the aggregate flight time on average, Druid was 3.1x faster; Druid took 6.0 seconds to run the query set while BigQuery took 19.4 seconds. Druid averaged 0.5 seconds per query and BigQuery averaged 1.5 seconds.
Query response is not the same as user response. A single request from a user, such as loading a dashboard or initiating a drag-and-drop operation in a visual UI, often requires several SQL queries to execute. Thus, an average query response of a second can easily grow to a 5-10 second wait time for the user, and a 2 second average query response might become unusable for interactive analytics.
Also, this benchmark was conducted on a relatively small data set (100MB) executed by a single user. Increases in data set size and query concurrency negatively impact query speed, given the same computing resources.
Lastly, there is reason to believe that BigQuery was at its performance floor in this benchmark, whereas Druid still had room to further reduce response times. For the test run, BigQuery, which dynamically allocates resources, chose to allocate far less than the full allotment of slots available. This may indicate that applying additional capacity was not expected to improve performance. Druid normally hits a performance floor at about 5 million rows per core, and in this test ran at about 50 million rows per core, meaning the core count could have increased 10x and still delivered performance gains.
Price-performance
Costs for Druid on AWS and Big Query were compared. Two price plans are offered for Google BigQuery: an on-demand price plan based on data scanned, and a flat rate fixed-slot price plan where a customer reserves the right to use a maximum amount of compute capacity. For Druid, the infrastructure costs are the costs of the AWS instances required to run the cluster.
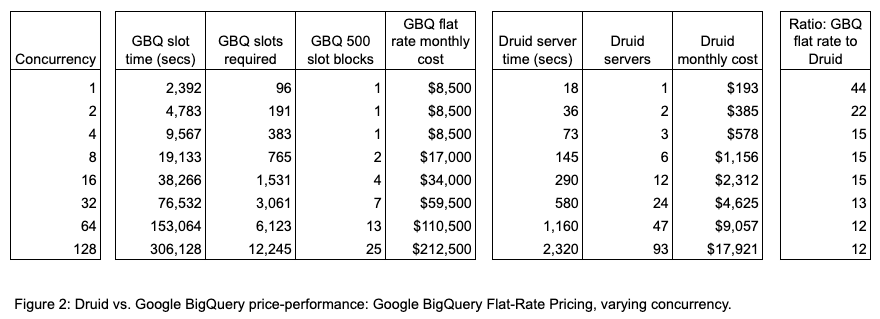
To compare pricing we normalized the Druid cluster to a size where it would run the query flight at the same speed as BigQuery and then compared those infrastructure costs to the slot costs of BigQuery. In both cases we took advantage of the longest available contractual commit to obtain the lowest cost.
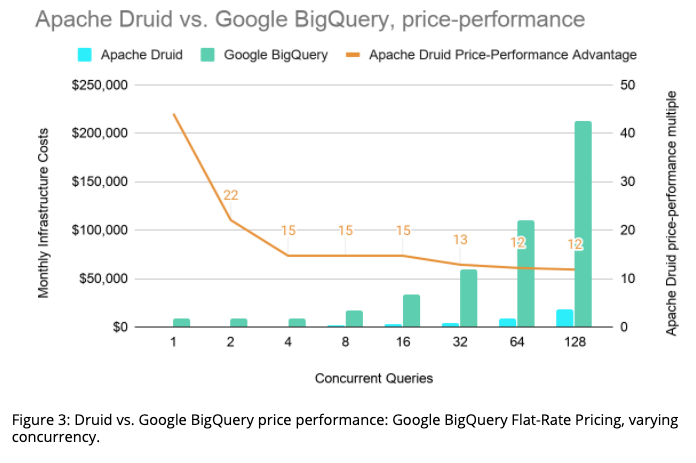
Druid exhibited a minimum 12x price-performance advantage over BigQuery based on the flat-rate fixed-slot plan that most large enterprises would choose.
In terms of dollars spent, there is an order-of-magnitude difference between Druid and BigQuery. This advantage grows from roughly $8,000 a month at lower concurrency to $195,000 a month for capacity to execute 128 simultaneous queries ($212,500 vs. $17,900).
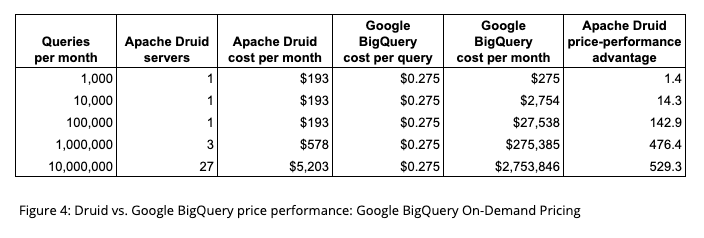
We also looked at price-performance using the BigQuery On-Demand pricing structure which charges $5 per TB scanned. This price plan is only economical for BigQuery users at relatively low queries volumes (under 10,000 queries per month). Above this level the BigQuery Flat Rate price plan becomes dominant.
As the chart shows, the Druid holds the advantage at 1,000 queries per month and this advantage grows quickly with scale. This is not surprising given that a single Druid server was shown to scale up to roughly 400,000 SSB queries per month.
Explaining what we found
There are some key differences between Druid and BigQuery that drive Druid’s advantage as shown in this benchmark.
Remote vs. local storage: cloud data warehouses like Snowflake & BigQuery need to retrieve data from remote storage during query execution, which slows them down. Druid prefetches data before it is queried, eliminating this source of slowdown.
Secondary indexes: cloud data warehouses do not index the data beyond the partition key. Instead, they rely on adding compute capacity to scale performance through brute-force. Of course, the customer has to reserve and pay for this capacity. Druid maintains space-efficient secondary indexes to minimize needless data scanning and processing.
Data tiering: cloud data warehouses give you “one size fits all” when it comes to performance and cost. Druid lets you control which data gets “hot” vs. “warm” vs. “cold” performance.
Implications for the enterprise
The move to cloud data warehouses has been driven by a desire to take advantage of the benefits of cloud computing and offload or eliminate expensive and difficult-to-maintain legacy data warehouses. This primary “EDW replacement” goal is why cloud data warehouses are optimized for complex analytics run by a relatively small number of individuals, namely trained analysts and data scientists.
A new world of self-service analytics is arising as companies harness the data unlocked by their digital transformation efforts over the past decade. This requires making new big data and streaming data sets available for exploration by hundreds or thousands of front-line business people in marketing, product, operations, sales, finance and other functions. Since data exploration is driven by interactive and iterative ad hoc queries, it requires extremely fast response under conditions of high query concurrency.
Use cases that involve broad self-service analytics exist across all organizations and industries. They include analytics for:
Marketing / advertising campaigns and audience segmentation
Digital product, service, website and app user behavior
Network and service performance
Supply chain operations
Fraud, compliance and risk
Given the price-performance advantage Druid demonstrated in this benchmark, it would be wise to evaluate Druid to address these high concurrency, real-time self-service analytics needs.
Resources
If you need more details or need to run your own benchmarks you can find more details in the full benchmark report.
If you want to get started with Druid, Imply features the market’s most advanced Druid distribution and Druid-based cloud service. You can:
If you have any questions or need more information please contact us anytime.
About Imply
Imply transforms how businesses run by integrating real-time analytics into their operations. Founded by the authors of the Apache Druid database, Imply provides a cloud-native real-time data platform that delivers real-time ingestion, interactive ad-hoc queries, and intuitive visualizations for many types of event-driven and streaming data flows. Imply Cloud has operations in North America, Europe, and Asia Pacific and is backed by Andreesen Horowitz, Khosla Ventures, and Geodesic Capital. For more information, please visit imply.io.
Other blogs you might find interesting
No records found...
Jun 16, 2026
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...