Imply Lumi Loglake vs Splunk Federated Search for S3
Jun 04, 2026
David Gee
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies have several notable differences.
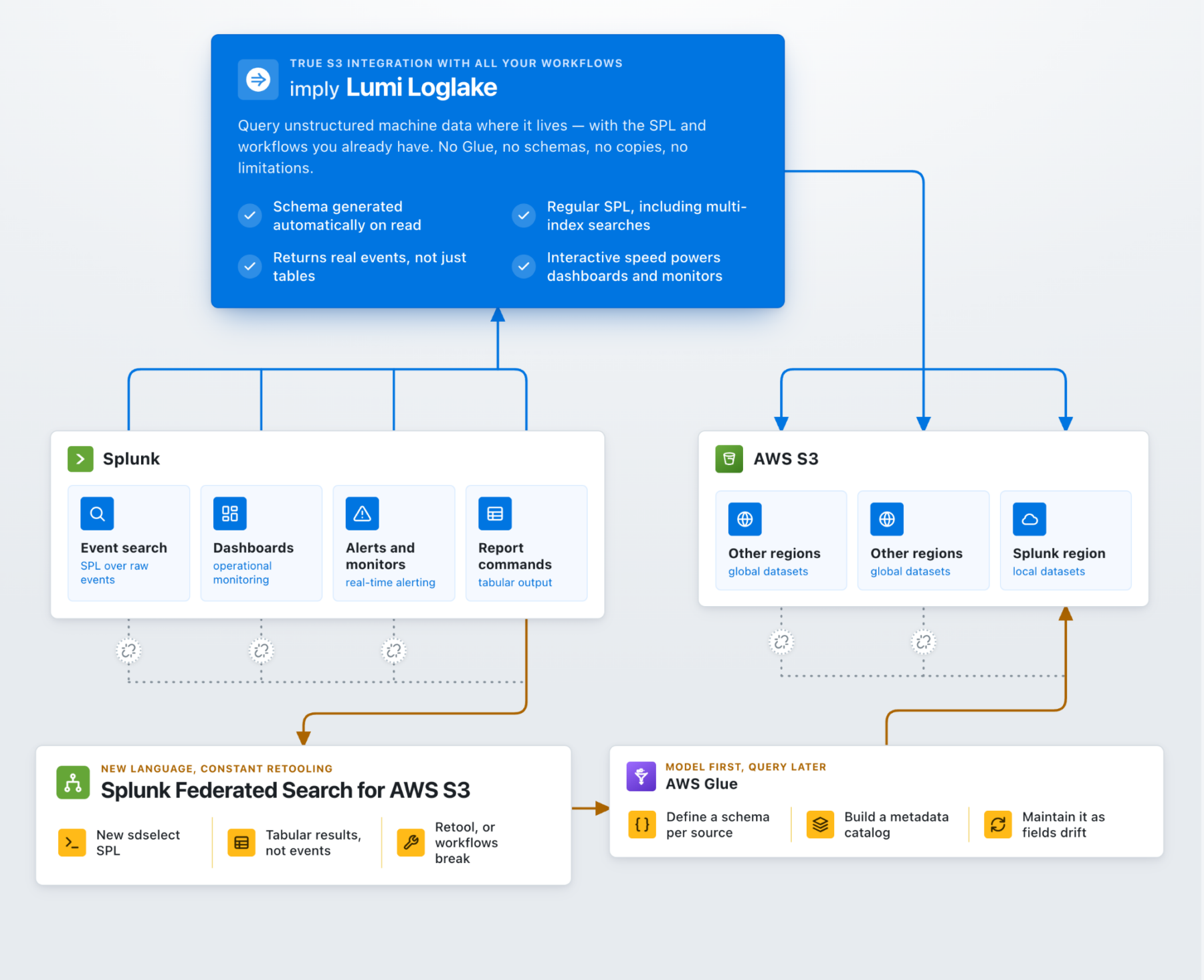
With Loglake, teams can query logs stored in S3 using standard SPL and receive native Splunk events that work with existing dashboards, alerts, and Splunk applications. As far as analysts are concerned, the data behaves as if it’s already in Splunk.
Splunk Federated Search for S3 addresses the same problem from a different direction. It allows teams to access S3-resident data from Splunk, but through a separate query model built around the sdselect command and table-based results.
Furthermore, the two technologies differ on how much initial preparation is required for queries to run.
Side-by-side comparison
Splunk Federated Search for S3
Lumi Loglake
Query language
sdselect
SPL and SQL
Results
Tables
Native Splunk events
Existing Splunk workflows
Separate experience
Existing experience
AWS Region Support
Same region only
Any region
Dashboards
Limited compatibility
Native support
Alerts
Limited compatibility
Native support
Schema Management
Required
Not required
AWS Glue Catalog
Required
Not required
No New Commands. No Retooling.
With Loglake, teams query logs stored in S3 using standard SPL. Searches return native Splunk events that work with existing dashboards, alerts, and investigative workflows.
Here’s what that looks like in practice.
Querying with Loglake:
index=vpc_flow_logs action=REJECT earliest=-24h
| stats count
Results come back as native Splunk events. Dashboards, alerts, and downstream workflows function exactly as expected.
Querying with Splunk Federated Search for S3:
| sdselect count(*)
FROM federated:vpc_flow_logs
WHERE action='REJECT'
Results are returned as tables rather than native Splunk events. As a result, teams often need to adapt dashboards, alerts, and workflows when working with federated data.
There are also limitations on how federated data can be used. For example, workflows such as multi-index searches are supported in Lumi Loglake but not in Splunk Federated Search for S3.
Splunk Federated Search lets you reach into S3. Loglake makes S3 feel like it’s already in Splunk.
Lumi is a single pane of glass to query logs indexed in Lumi and logs in object storage. This differs from Splunk, which requires two separate workflows to interact with logs indexed in Splunk and logs in object store.
Built for Unstructured Logs
The second major difference is how each platform handles data preparation.
Before Splunk Federated Search can query data stored in S3, that data must be represented through an AWS Glue Data Catalog. The catalog provides the schema and metadata required for queries.
This approach is similar to ones used for structured business data, where schemas are stable and query patterns are predictable.
Logs are different.
New telemetry sources appear continuously. Fields evolve. Formats change. Investigations often begin before teams know which fields will matter.
Loglake was built around a different assumption: logs should be searchable before they are modeled.
Instead of requiring schema definitions, catalogs, or metadata maintenance, Loglake allows teams to query unstructured logs directly in S3.
Teams simply point Loglake at their data and begin searching.
Loglake enables your Splunk UI and apps such as Enterprise Security to directly query logs in object storage (such as AWS S3).
Loglake takes the original schema-on-read popularized by Splunk and extends it to unstructured logs in object storage. Query first, optimize later.
Come See it at Databricks + AI Summit
We’ll be demonstrating Lumi Loglake at Databricks Data + AI Summit. Stop by the Imply booth to see how teams can query unstructured logs directly from S3 using SPL, without schema definitions, without catalog maintenance, and without changing existing Splunk workflows. Request a demo if you’d like to see it before then.
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
A First Look at Lumi Loglake: Query Logs Where They Live
TL;DR: Imply Lumi Loglake is a lakehouse (separated compute/storage) architecture for unstructured logs that reduces costs from 40% up to orders of magnitude on your hardware/AWS/Azure bill used to run your...