In the database world, performance is what everyone competes on. It’s easy to find new database vendors that claim to have higher performance than what existed before. What isn’t easy to find is any discussion on how to operate at scale, because it takes a lot of effort to ensure high availability and performance with rapid data growth. Druid is not only highly performant but also designed to operate easily at scale. Druid does this by using native cloud technology and automation. In this article, I’ll show you how.
Databases have 3 main responsibilities: data ingestion, storage, and serving.
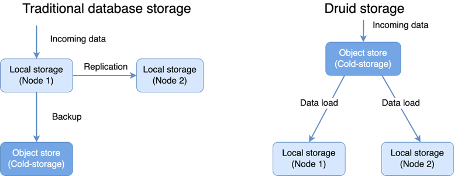
Once the database engine receives data, it’ll convert the data into an optimized format for serving. Then the database engine will need a way to store this optimized data until needed. Traditionally, databases store data on local storage. This means it’s the database engine’s responsibility to ensure the data is safely stored.
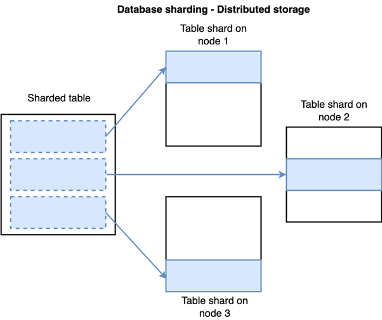
When data can no longer fit onto a single large node (or server) the database needs to scale out (adding more servers or nodes). To do this, databases use techniques such as sharding to distribute the data across multiple nodes. Like the name implies, a shard is a fragment of the overall data.
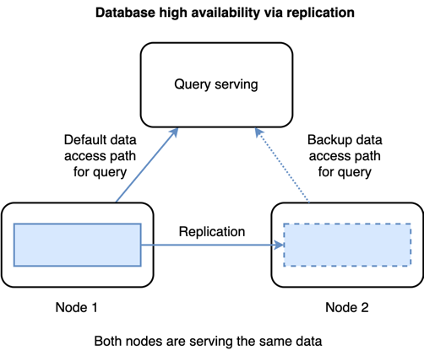
To ensure high availability, databases use techniques such as replication to provide redundancy when serving the data.
When something is the responsibility of the database engine, it also becomes the responsibility of the database administrator (DBA). DBAs are already overworked, so we need to reduce the workload of operating a database at scale.
Druid achieves this by inverting the storage architecture and delegating some of the responsibility to other systems while automating others.
Druid uses cloud-native object stores, such as Amazon S3, as its primary data storage. This is attractive in terms of cost and scaling because object stores are highly elastic, you only pay for what you are using. It has built-in redundancy and is distributed by nature. This also means getting data in and keeping data safe will not affect the performance of getting data out.
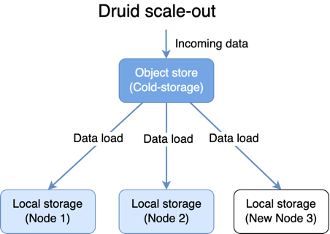
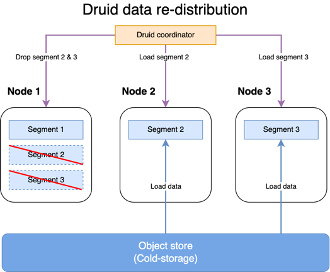
At the same time, Druid automates the process of data re-distribution and replication by running the “coordinator” process. The coordinator process monitors for the health of current nodes as well as new nodes in the data serving layer. It instructs nodes in the data serving layer to fetch data from deep storage to serve.
Databases that are similar to Druid, such as ClickHouse, require manual operations for scaling. To scale out ClickHouse, users must create a placeholder table on new nodes, manually copy data files to new nodes, and then attach those data files to the placeholder tables. Administrators then must monitor for uneven storage utilization across the nodes and manually move data around to accommodate. Doing this in a large cluster with many tables requires a significant amount of manual effort and automation outside of the cluster.
In the Druid world, the coordinator process makes this automatic. It accounts for storage utilization and the number of replicas you need when redistributing data.
Consider the effort to re-balance a cluster after adding nodes:
ClickHouse
Druid
Add a node to the cluster.
Add a node to the cluster. Druid takes care of the rest.
Rename existing tables, then create new tables with the old names (ReplicatedMergeTree).
Move the data from the old table to the detached subdirectory inside the directory with the new table data.
Re-attach the data to the table by running ALTER TABLE ATTACH PARTITION on all newly added nodes.
Summary
By leveraging cloud-native object stores as well as automating the data distribution task, Druid reduces the operational burden on administrators. This allows the team using Druid to focus on building products and experiences that matter for their business, instead of time-consuming data copying tasks.
At the same time, Imply’s product offering simplifies Druid’s operation even further. Our offerings take care of provisioning, patching, and securing a Druid cluster with an easy-to-use UI. And Imply Polaris further simplifies this by integrating streaming infrastructure into a fully managed, SaaS solution.
For those who are looking for a better performing database for their next analytics application without a lot or any operational burdens, come checkout Imply Polaris or Enterprise Hybrid.
Other blogs you might find interesting
No records found...
Jun 16, 2026
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...