If this is your first time working with or building out a distributed system the fact that everything is going to fail may seem like an extremely scary concept, but it is one you will always have to keep in mind.Modern distributed systems routinely scale to thousands or even tens of thousands of nodes, and operate on petabytes of data. When operating at such scale, failures are a norm, not an anomaly, and your system must be able to overcome a wide variety of different failures. In this post, I will briefly cover some of my experiences building Druid, an open source distributed data store, and the various design decisions that were made on the project to survive all types of outages. Druid was initially designed to power a SaaS application with 24x7x365 availability guarantees in AWS.
The Bad
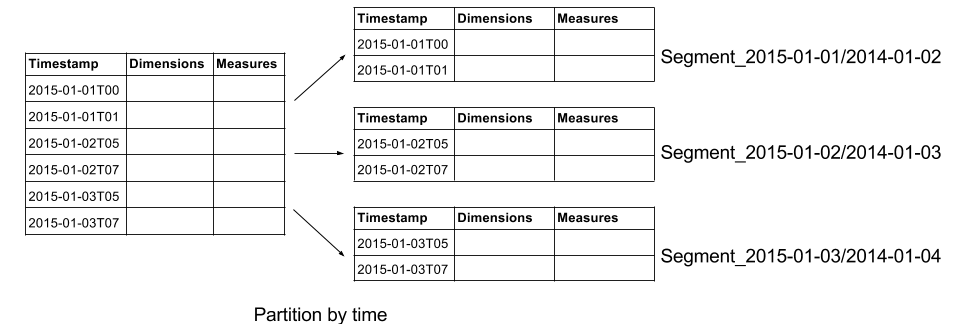
Let’s first examine the most common type of failure that can occur: single server failures. Servers may fail for a variety of different reasons such as hardware malfunction, random kernel panics, network outages, or just about every other imaginable and unimaginable reason. Single server failures occur frequently, especially as your cluster grows in size, but thankfully, single server failures generally have minimal impact on data availability and system performance. The standard approach to ensure data remains available and performance remains consistent during single server failures is to replicate data. Using Druid as an example, replication is supported by first partitioning data by time into immutable shards known as segments.
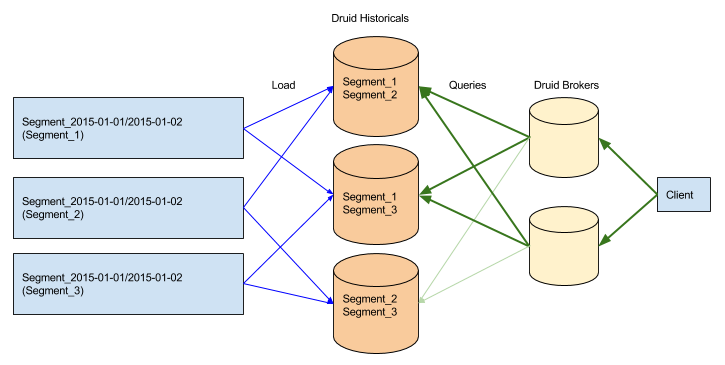
These segments are downloaded by nodes known as historical nodes and multiple historical nodes may download the same copy of a segment. Historical nodes are very simple – they follow a shared nothing architecture and only know how to scan segments. In front of the historical nodes, we have a layer of broker nodes that know which historical nodes are serving which segments.
Clients interact with the broker nodes and brokers will forward queries to the appropriate historicals. Queries can be routed to any replica of a segment with equal probability.
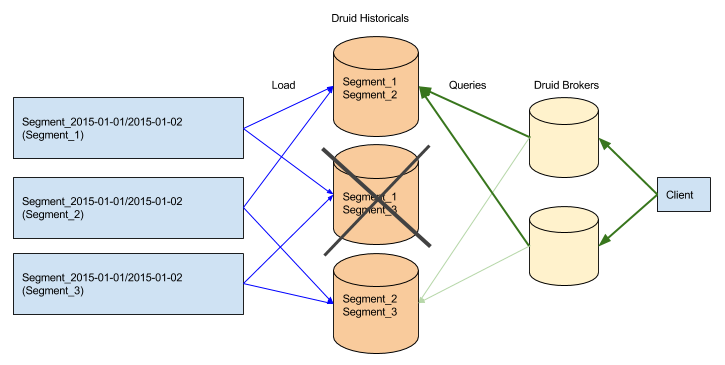
When one copy of a segment disappears, the broker will respond by forwarding queries to any existing copies of the segment.
The Really Bad
While single server failures are fairly common, multi-server failures are not. Nevertheless, your distributed system must persevere. Multi-server failures occur because of data center issues such as rack failures and any number of nodes can be lost at once, including the entire data center.
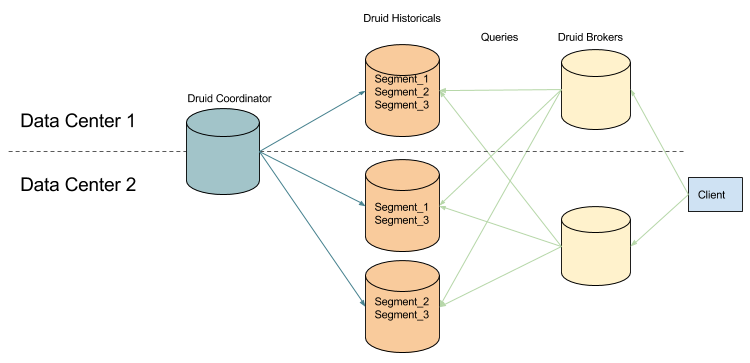
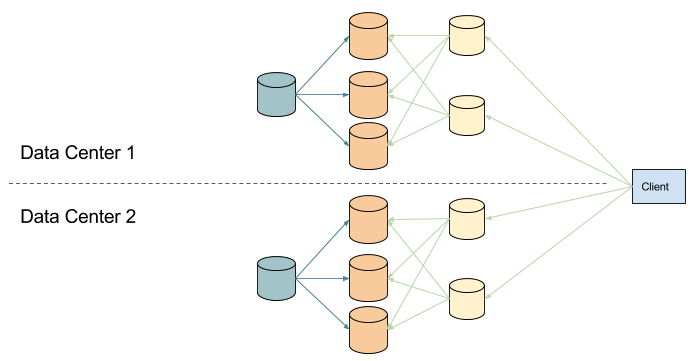
While multi-datacenter replication seems like a very straightforward approach, there are many pitfalls to avoid. The simplest setup to replicating data in multiple data centers is to distribute the nodes of a single cluster across the data centers.
This setup works reasonably well if you run in a cloud setup such as AWS, where availability zones may be geographically situated very close to each other (i.e. across the street from each other, with fiber wires connecting the zones). In such setups, there is minimal network time as nodes communicate to one another. This setup works less well if you have data centers spread across the world.
Most modern distributed systems require some piece for cluster coordination. Zookeeper remains an extremely popular option and Raft has been gaining more traction. Distributed coordination tools rely on consensus to make decisions around writes, consistent reads, failovers, or leader election, and consensus requires communication among nodes. If the coordination piece is distributed across multiple data centers, the network time involved in consensus agreements can be significant. Depending on how much your system relies coordination in its operations, this overhead can have significant performance and stability impacts. Given most distributed systems are quite reliant on the coordination piece, an alternative setup of running in multiple data centers is like so:
In this setup, you run an independent cluster per data center. The clusters do not know anything about each other, and it is up to your ingestion/ETL piece to ensure the same data is delivered to all the different clusters.
The Catastrophic
Catastrophic failures arise when your distributed system experiences performance issues, but there is nothing obviously failing. It can be tremendously difficult to find a root cause of a problem during these slowdowns. The source of slowness can come from a variety of causes, for example, if too many users are using your system at the same time.
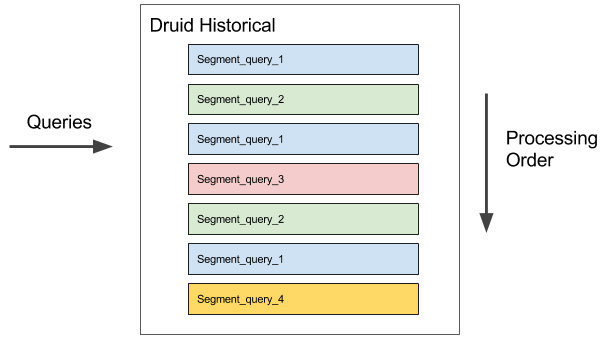
There are two primary strategies Druid employs for multi-tenancy. The first is to keep the unit of computation small. Druid queries involve scanning one or more segments, and each segment is sized such that any computation over the segment can complete in at most a few hundred milliseconds. Druid can scan a segment pertaining to a query, release resources, scan a segment pertaining to another query, release resources, and constantly move every query forward. This architecture ensures that no one query, no matter how expensive, starves out the cluster.
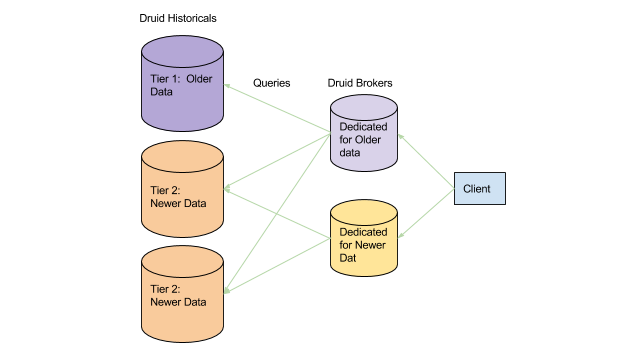
The second way Druid deals with multi-tenancy is to separate and isolate resources. For example, when dealing with event data, recent data is queried far more often than older data. Druid can distribute segments such that segments for more recent data is loaded on more powerful hardware, and segments from older data is loaded on less powerful hardware. This creates different query paths where slow queries for older data will not impact fast queries for recent data.
A second cause of slowness (where nothing is obviously failing) is due to hot spots in the cluster. In this case, one or more nodes are not down, but are operating significantly slower than their peers. Variability between nodes is very common in distributed systems, especially in environments such as AWS. Thankfully, there has been great literature written about minimizing variability.
At the end of the day, diagnosing problems where there is no clear failure requires proper monitoring and metrics, and the ability to do exploratory analytics on the state of the cluster. If you are interested in learning more about using exploratory analytics to diagnose issues, I invite you to read my previous post on the subject.
Other blogs you might find interesting
No records found...
Jun 16, 2026
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....
Imply Lumi Loglake vs Splunk Federated Search for S3
Teams are increasingly moving log data into AWS S3 to reduce costs and extend retention. Both Lumi Loglake and Splunk Federated Search to S3 help you query data in AWS S3 to lower costs, however the two technologies...