Results of the first Apache Druid (incubating) community survey
Jun 25, 2019
Gian Merlino
We recently conducted our first Druid community survey. Every so often we’ll be asking our community a short set of questions to understand how they use the Druid database, and how they would like to see it improved. Thank you to everyone that participated in the survey. The responses are extremely helpful as we think about the Druid roadmap and the future of the project.
Here’s a summary of the survey results:
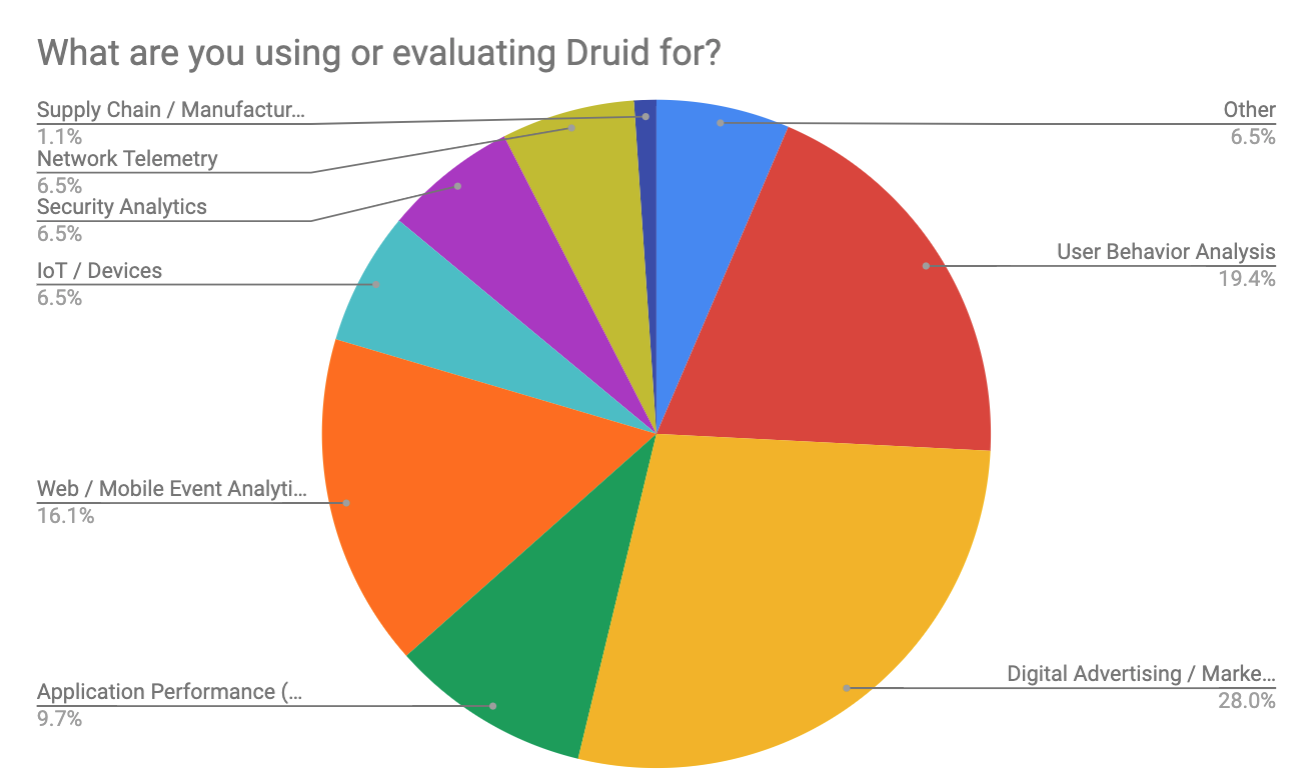
Use Cases
Over half of respondents indicated use cases that broadly fall into the realm of business and clickstream analytics. The top use cases for Druid include digital advertising/marketing analytics, user behavior analytics, and web/mobile event analytics. There was also a breadth of use cases with all different forms of event data, including application performance monitoring (APM), network telemetry, manufacturing analytics, security analytics, and IoT. It will be interesting to see how the mix of use cases evolves over time.
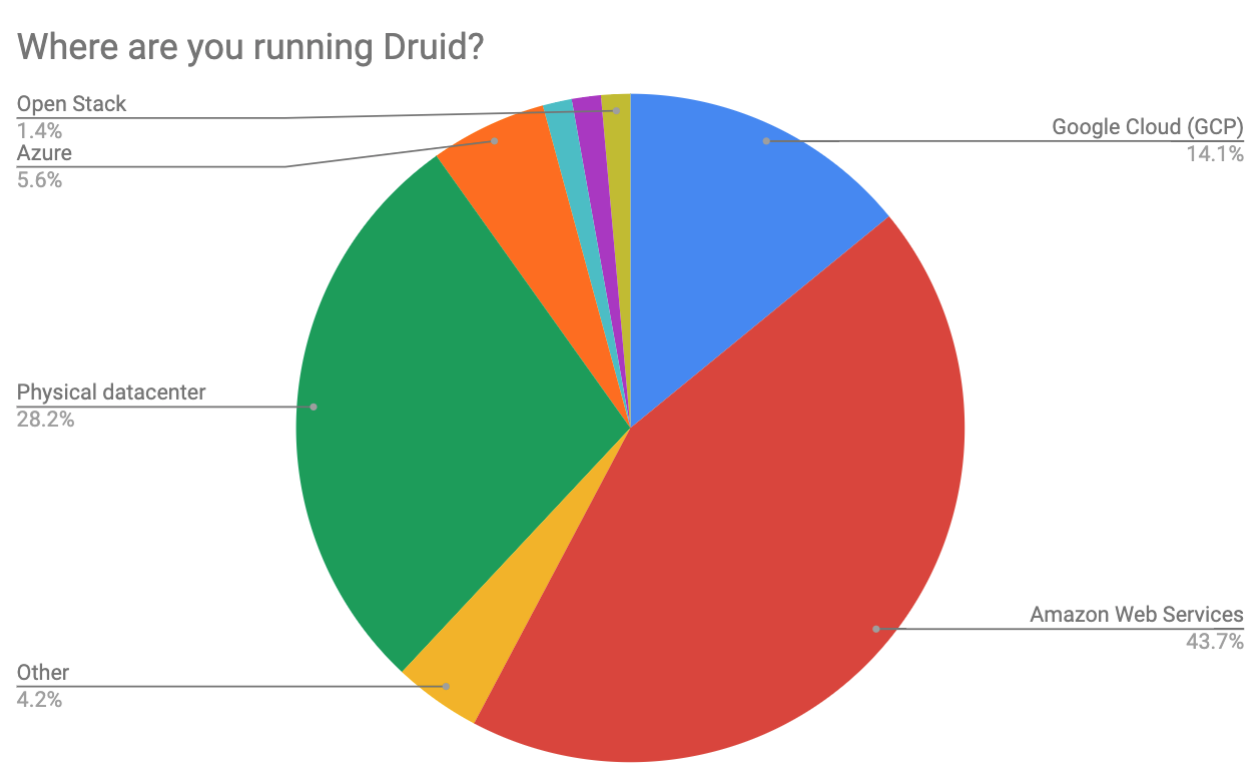
Environment
The large majority (72%) of respondents were running their Druid cluster in the cloud. Not surprisingly, AWS led (44%) the pack, followed by Google Cloud Platform (14%), Azure (6%) and OpenStack deployments (1%). Fewer than a third of respondents are running Druid in their own data center.
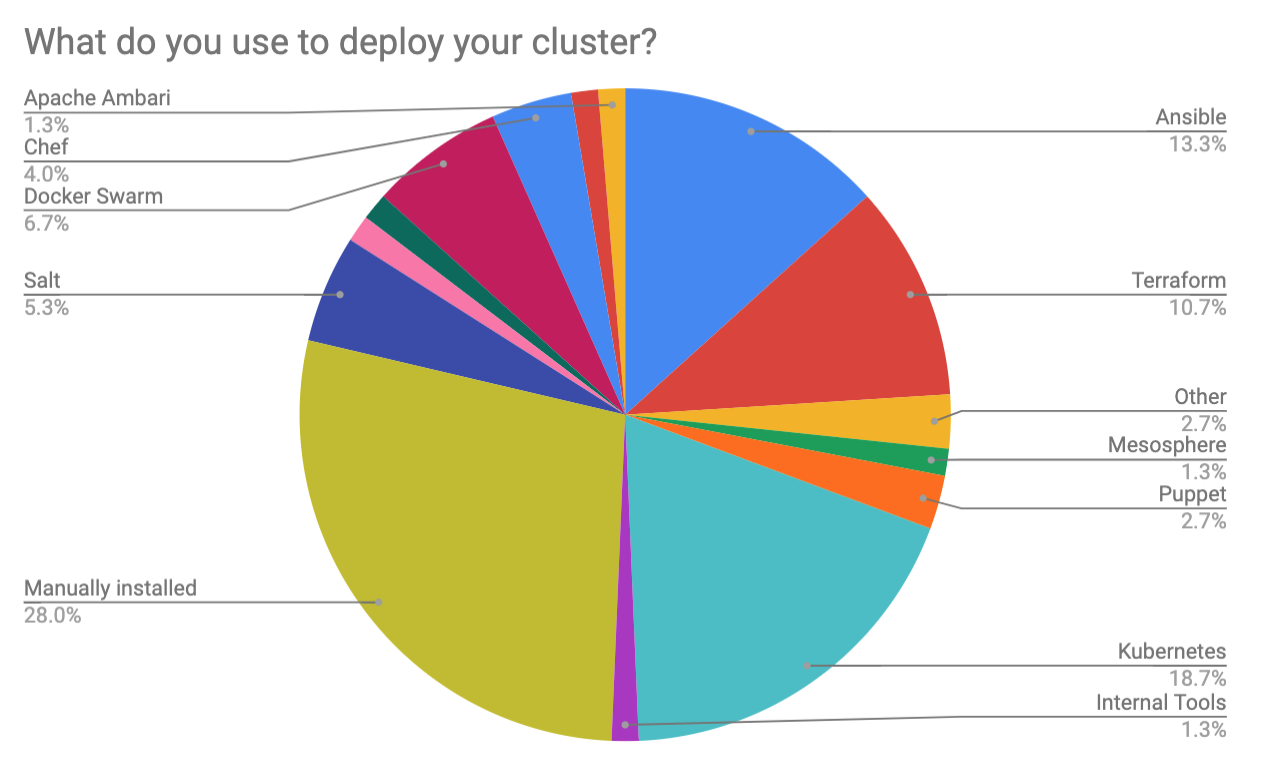
Deployment
Manual cluster deployment was the most popular method (28%), but the answers were somewhat fragmented beyond that, led by Kubernetes (19%), and followed by Ansible (13%), Terraform (11%), and Docker Swarm (7%).
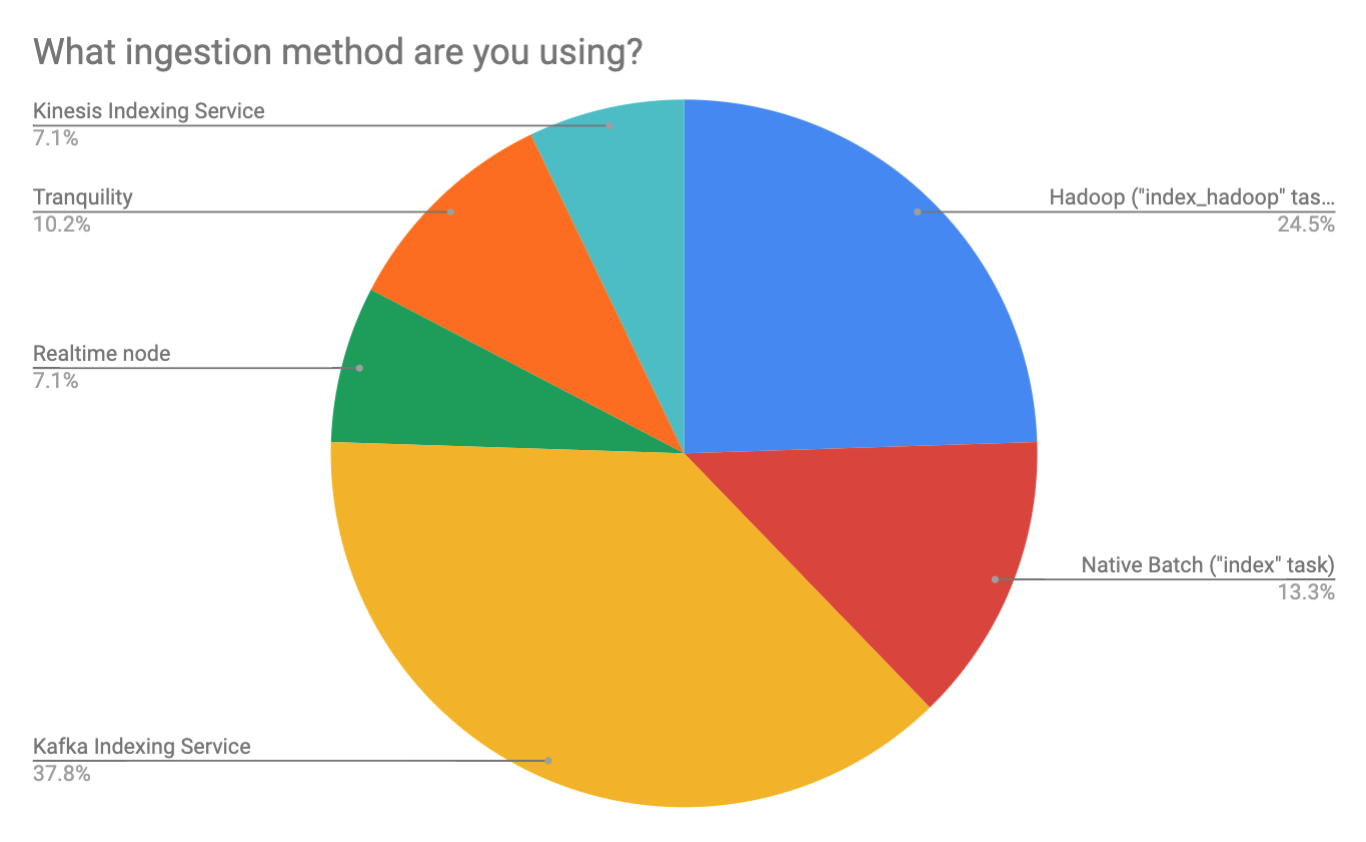
Ingestion
For data ingestion, Kafka (38%) and Hadoop (25%) ingestion methods accounted for nearly two thirds of the responses, with Tranquility, Kinesis, native batch and legacy real-time nodes rounding out the methods used. Sixty-five percent of respondents were using some form of streaming ingestion to load data into Druid. We anticipate this percentage to grow with time as streaming becoming more widespread.
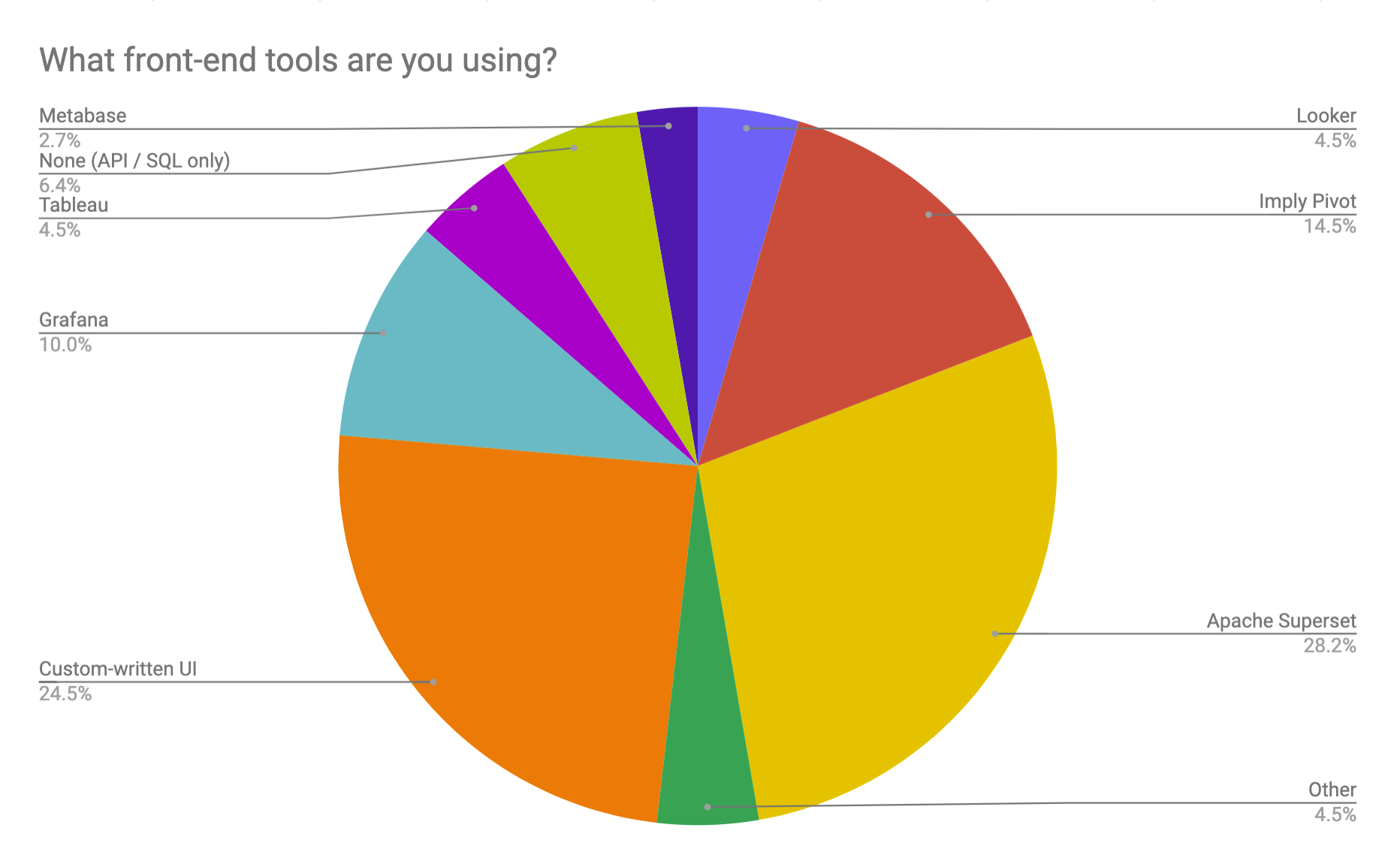
Visualization
There are a variety of front-end tools being used to query and visualize Druid data, led by Apache Superset (28%), followed by Imply Pivot and others such as Tableau, Looker, Metabase and Grafana. Roughly a quarter of the respondents have created their own custom UI. We should note that the majority of people were running more than one UI, with some running almost every option.
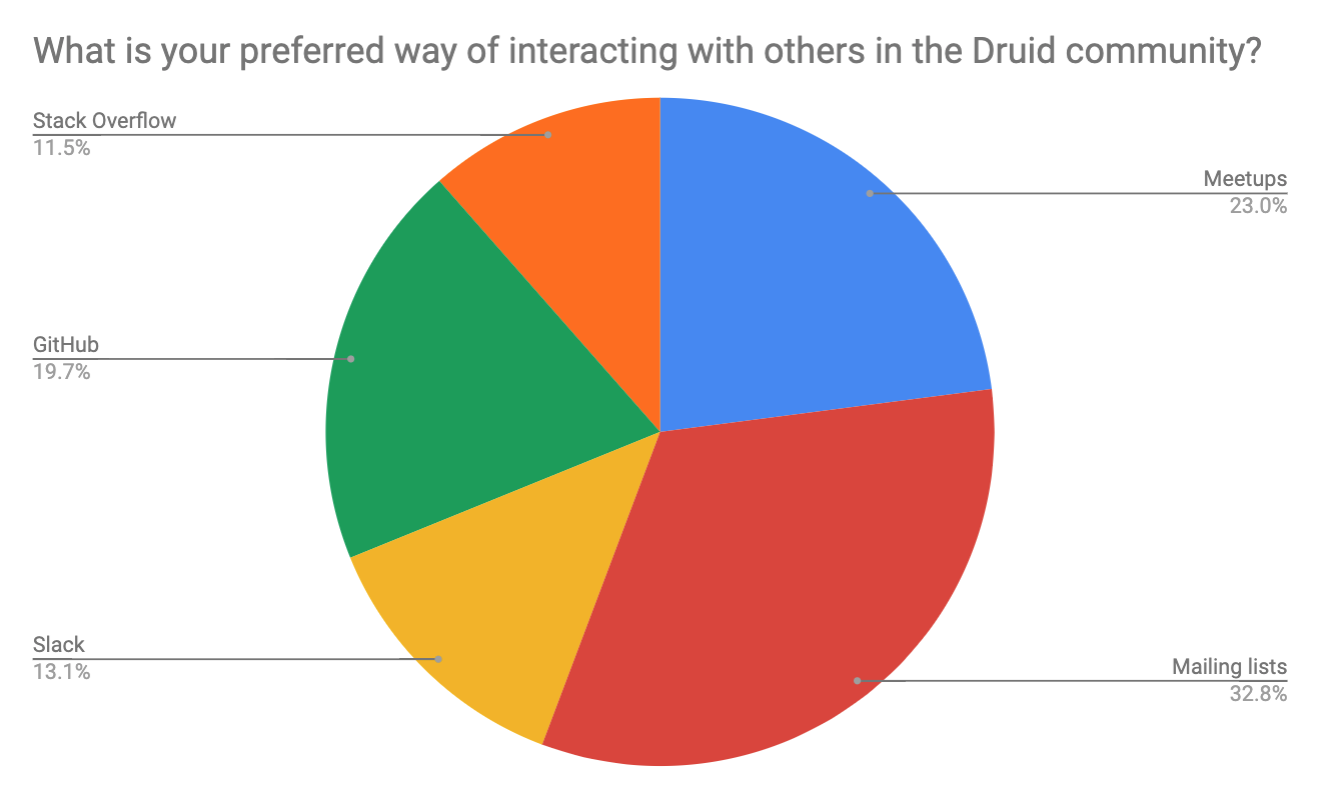
Community
Lastly, we asked about preferred methods of community interaction. The tried and true channels of meetups (23%) and mailing lists (33%) were the majority, with Github and Slack following.
Feedback
Our final question was a request for general feedback. Although there was a wide variety of things people wanted to see on the Druid roadmap, the most requested features were:
Joins
Better Kubernetes support
Simpler configuration
The good news is that we’ve been actively thinking about and working on these features and much more. Stay tuned over the next few weeks as we present more information on Imply is thinking about the Druid roadmap.
Other blogs you might find interesting
No records found...
May 07, 2025
Real-Time Observability Without Operational Overhead: What’s Next?
Observability is meant to provide clarity, speed, and confidence in modern systems. Yet for many organizations, it has become a source of complexity, cost, and operational drag. Managing pipelines, tuning...
It’s Time to Rethink Observability: The Event-Driven Future
Observability has evolved. Forward-looking teams are already moving beyond static dashboards and fragmented telemetry—treating all observability data as events and unlocking real-time insights across their...
5 Reasons to Use Imply Polaris over Apache Druid for Real-Time Analytics
Introduction Real-time analytics is a game-changer for businesses that need to make fast, data-driven decisions. Whether you’re analyzing user activity, monitoring applications and infrastructure, detecting...