Zscaler (herein referred to as ZS) is a global cloud-based information security company. While traditional security products focus on securing two highway lanes of traffic (east-west and north-south), these classic hub-spoke models do not align well with modern cloud centric, mobile workforces where clients and services are dynamic and unanchored.
ZS has two main product lines: ZIA (Zscaler Internet Access) and ZPA (Zscaler Private Access), modern cloud-based security products designed to secure different lanes of traffic. ZIA protects end clients from threats from the internet (multi-dimensional traffic flow), while ZPA protects north-south traffic. Both products differ architecturally and have to support different scales of traffic, performance, and SLAs.
To learn more about Zscsaler’s products, please visit:
This document outlines the journey we made in building ZPA and focuses on the analytics component of our solution. We will discuss some of our early requirements, why we picked certain technologies, and how we run things today.
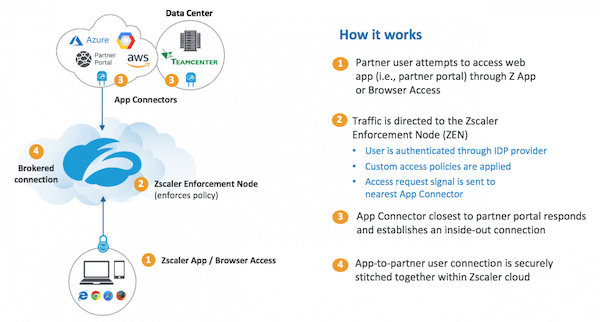
ZPA architecture
The diagram below depicts a high level overview of ZPA solution:
Some of the architectural principles of ZPA platform are outlined below:
Secure – security always comes first (and with appropriate SLA levels).
Scalable – ZPA is a SAAS platform that linearly scales with increased usage.
Margin aware – we are building a sustainable and profitable business.
Customizable – ZPA enables customers to build core competency and buy context.
Real-time – ZPA provides customers with a real time view of data transiting in ZS cloud environments.
Simple – less complexity means a better user experience.
Transparent – deep visibility into cloud usage for customers.
Flexible – powerful dev/ops capabilities with extreme flexible configuration.
ZPA analytics
Analytics is an important part of the overall ZPA platform. Our customers demand a rich set of analytical tools that provides insight into their day to day use of ZS products. To satisfy our customer requirements, we collect a variety of logs from our products for operational purposes. Some information about our logs include:
Logs come in a wide range of flavors: authentication logs, transactional logs, system logs, and other event logs.
Logs are in a semi-structured JSON format.
Logs are subject to various regulations like GDPR, SOX etc.
We ensure geographic data isolation, so that logs and queries do not move any data across defined boundaries.
No PII information ever stored.
Cost of operations is a tiny fraction of the product price point.
Requirements
ZPA analytics had a complex set of requirements we had to meet for our customers. As we evaluated an engine to power our product, we had to consider support for the following:
Periodic pre-defined queries: The analytics engine must have the ability to run predefined queries periodically either through a scheduler or on demand from consoles/API.
Ad-hoc queries: The analytics engine must have the ability to run ad-hoc queries around defined dimensions in the data set.
Concurrent queries of historical and live data: Queries should be able to operate on historical data as well as live data from a single query and should be able to operate on those data sets simultaneously.
Seamless schema evolution: The underlying data will evolve over time and analytics engine should be able to support the same.
Aggregations: Aggregations on data is used to feed a wide variety of dashboards, some of them are counts, topN/groupBy aggregations of multiple dimensions of the data set. The system should be able to aggregate for different time ranges.
Dealing with delayed logs: Logs can arrive delayed due to unforeseen reasons, and the system should be able to process delayed events and still aggregate to specific time windows.
User-defined functions: The engine must have an ability to maintain a library of user defined functions which can be integrated into different query languages.
Cloud Neutral: All ZPA infrastructure must be able to run in all popular public cloud environments.
Building the analytics engine
The team tasked with ZPA Analytics had worked on a different product line that had similar requirements and experimented with products such as Apache Cassandra, Apache Drill, Elasticsearch. Thus, in the initial phase of development, we first went with Cassandra and Elasticsearch and launched the beta version of the product. While functionally the systems performed well, we quickly realized that it would be cost prohibitive to scale the systems linearly. Furthermore, we faced other important obstacles during the RAS testing effort (broadly around reliability, availability and serviceability):
It was difficult to containerize some services, and expensive to scale linearly.
The cost of hot/cold nodes for query purposes was prohibitive.
A high number of concurrent queries would thrash the system.
There were many issues around compaction of data stored, which caused ad-hoc spikes in performance.
At this time, we started on a prototype for an in-house tool to do fast aggregations for us, but then we realized that there was an open source tool called Druid that was offering out-of-the-box functionality that met our needs. We reached to Fangjin Yang, who was one of the early innovators of that product, to come down to our development center at San Jose and provide a walk through of the product with us.
We quickly realized that the system could meet both the functional and cost effectiveness requirements of the product and decided to shelve our plans of building an inhouse product. Druid was able to satisfy all the needs that were outlined in the sections above.
We have been using Druid for the last 4 years at ZS and our deployment primarily runs in AWS. Our cluster has continued to grow as our user base has continued to increase. We have been partnering with Imply, the commercial entity behind Druid, as well.
Salient features
Some of the salient features of Druid that most align to our needs include:
A pure microservices-oriented architecture, with the ability to scale various components independent of each other.
The ability to inject JSON and define dimensions/metrics around those fields.
A lambda architecture for real/batch processing.
Near painless upgrade to newer versions.
Flexible query engine with ability to add custom UDFs.
Useful performance monitoring tools (from Imply) to see exactly what the core engine is doing.
Druid deployment architecture
Today, we use Docker and ECS to deploy and run Druid. A traditional Druid deployment is used, and includes:
2 x Overlord
2 x Coordinator
n x Broker (scales as load increases)
n x Tranquility (scales as load increases)
n x MiddleManager (depending on # of concurrent tasks)
n x Historical (depending on how much segment data we want to load)
Druid in Docker
A base Docker image is built using Imply’s distribution of Druid. This image is used for all containers (Druid + Tranquility). Each component is deployed as its own stand-alone container. A Dockerfile is used to define which version of Java and Imply are used, as well as other pieces, such as GoSu, FIPS libraries/config, etc.
Container runtime ENV vars declare which Druid process needs to run (e.g. Broker, Coordinator, Tranquility, etc). This simplifies the build infrastructure and reduces management of Docker images. Since the containers all share the same base image, configuration is downloaded dynamically at runtime. This is based on a bootstrapping script we wrote which pulls down the proper config from the proper component (comes from S3).
New versions can be built/tested and deployed in the same manner, by swapping out the Docker image tag.
ECS for scheduling
Amazon’s Elastic Container Service (ECS) is used for Docker scheduling. A Druid ECS cluster is deployed, and several EC2 hosts are joined to it. These hosts are spawned as part of an EC2 Auto-Scaling Group (ASG) and share the resources as a pool for all of the containers for the cluster. New containers will be deployed to a host as needed to meet our desired ECS service count.
The biggest benefit of ECS is the monitoring/restart capability. If a container dies, it is restarted (and in some cases, automatically re-attached to the Load Balancer). AWS CloudWatch Rules are used to trigger ECS Container state change notifications, which are then sent to Slack.
Containers with fixed listeners (e.g. Broker, Tranquility) are run in ECS Host Mode, whereby the container binds to the IP:Port on the EC2 host machine, and not proxied using Docker-Proxy (“ECS Bridged Mode”).
ECS Task Definitions are used to version Docker Image tags, and also to point Container logs to AWSLogs (CloudWatch Logs). This makes log review accessible and easy.
Terraform + Ansible for bootstrapping
Terraform is used to bootstrap most of the AWS infrastructure, including the Druid ECS, RDS, ALB, S3, and CloudWatch components.
New environments are built in the same manner, as this allows us to spin up new Druid clusters very quickly. Most environments have 1-2 Druid clusters.
CentOS RAW ISO-based AMIs are created for use by the ECS clustered hosts. Most of the hosts are m4.2xlarge, and can service about 4-6 containers each without being overloaded. Ansible is used to manage the underlying EC2 hosts for ECS. Very little configuration is pushed to these hosts – it is mostly just SSH config for Ops access.
RDS for Druid Metadata Storage
RDS (PostgreSQL) is used for Metadata storage. This is natively supported in Druid and requires little management overhead. In some cases, direct PGDB access is required (via SSH tunnels) to manually manage the data (e.g. to trigger re-ingestion or for some other reason).
S3 for Deep Storage
S3 is used for Druid’s deep storage of segment data. ECS Tasks (Containers) have IAM Roles assigned to them, so they can seamlessly read/write data from/to S3. Encryption is enabled on S3, as well as a Lifecycle time, so as to prevent unnecessary long-term storage of data. Recently FIPS was added into the configuration for S3, and enabled on the Druid containers. This was done by modifying the Java JRE security policies and configuration.
Additional Druid configuration was required to point to the S3-FIPS endpoints. AWS v4 HMAC signing (jets3t.properties) is also enabled for some S3 regions.
ALBs for load balancing
AWS Application Load Balancers (ALBs) are utilized in front of Druid Brokers and Tranquility. This provides scaling, and works together with ECS to dynamically re-assign containers as they move around during restarts. Basic HTTP health-checking is utilized here to ensure the containers are healthy, otherwise they are restarted automatically.
Data ingestion
We have written a custom ingester that reads from Kafka and sends to Tranquility, this is needed since we need to flatten nested JSON and also detect duplicate logs that end up in the system.
Summary
We have been very happy with using Druid for all our aggregation/analytics portion of ZPA analytics and we are sure to expand the Druid footprint to other product lines in the future. We’ve had great success working with Imply and wish them success in their journey both as a company and with Druid.
Other blogs you might find interesting
No records found...
May 07, 2025
Real-Time Observability Without Operational Overhead: What’s Next?
Observability is meant to provide clarity, speed, and confidence in modern systems. Yet for many organizations, it has become a source of complexity, cost, and operational drag. Managing pipelines, tuning...
It’s Time to Rethink Observability: The Event-Driven Future
Observability has evolved. Forward-looking teams are already moving beyond static dashboards and fragmented telemetry—treating all observability data as events and unlocking real-time insights across their...
5 Reasons to Use Imply Polaris over Apache Druid for Real-Time Analytics
Introduction Real-time analytics is a game-changer for businesses that need to make fast, data-driven decisions. Whether you’re analyzing user activity, monitoring applications and infrastructure, detecting...