Druid query view: An elegant SQL interface for a more civilized age
Oct 16, 2019
Margaret Brewster
History is littered with examples of tools that open the door to new innovations. Fire allowed us to harvest more nutrients from food, the assembly line gave us cheap affordable goods and the internet gave us the ability to stay up until 4am looking at memes. While it isn’t fire and it certainly isn’t an otter eating watermelon (look at it, it’s hilarious). I believe that this summer during my internship at Imply I got an opportunity to work on a tool that in its own right has opened the door to more innovative and accessible data querying web applications.
As part of my internship, I got to work on Apache Druid, an open-source data store designed to manage large collections of data. Specifically, Apache Druid is used for low-latency near real-time data ingestion, data and metadata exploration as well as data aggregation on realtime and historical data sets. Users have three choices to leverage the functionality of druid: command line, 3rd party applications, and the included web console application. This web console is primarily what I got to work on. It is designed to provide a more streamlined, visual and user-friendly way to use Apache Druid.
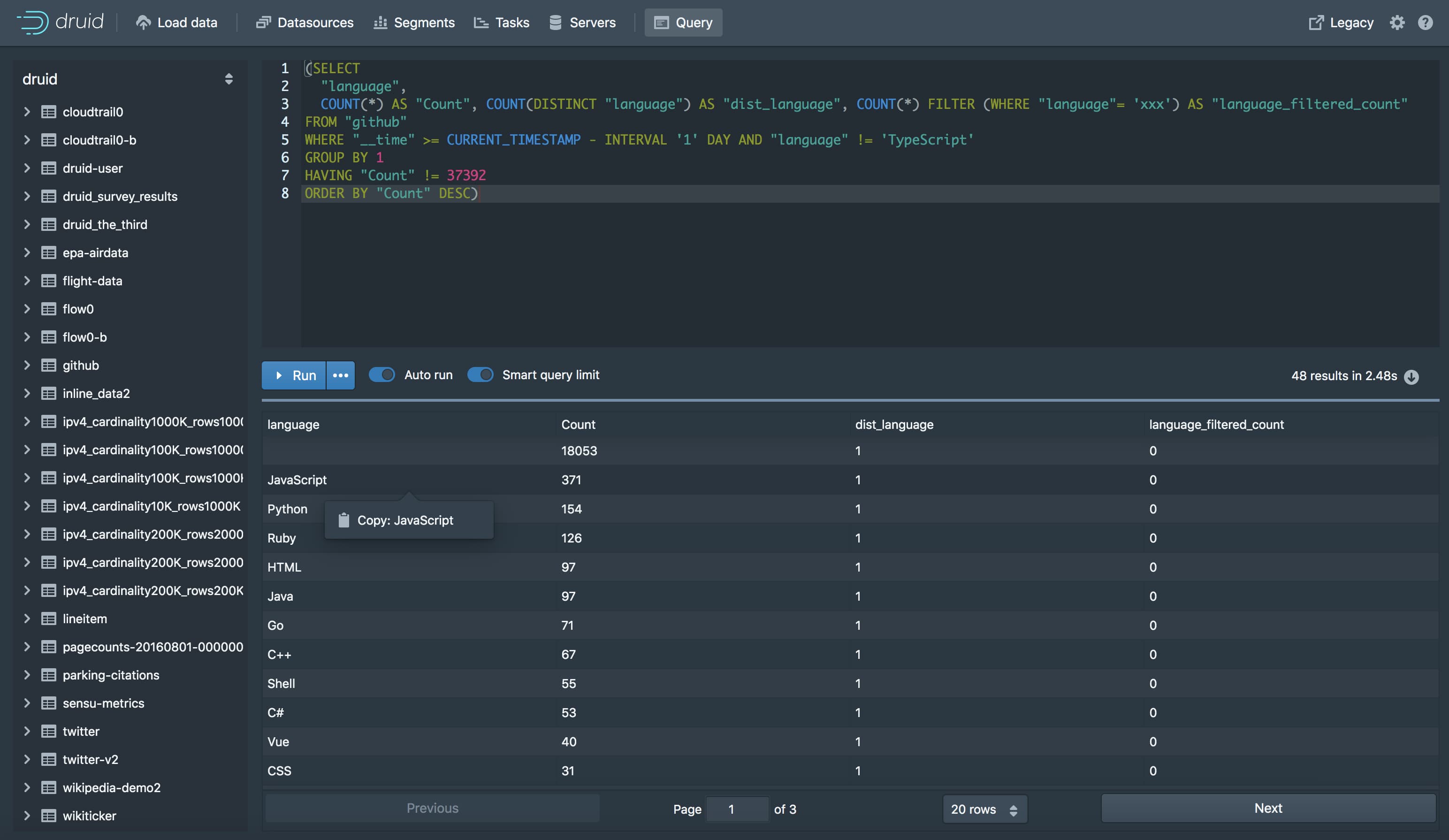
The web console includes a query view where the user can query their data using DruidSQL. In the 0.14 release of Apache Druid, the only interactions available to the user were to write a query or run it. In 0.15 an auto-completer was added. Now in 0.16, we have added a new layer of SQL awareness to help move the view away from its roots as a text-only interface, to a point-and-click one. The query view now highlights aggregate columns and underlines the sort direction. Additionally, contextual modifications are suggested to people using the view that help them modify the query. Users now have the option to change sort direction, filter on current results or select an operation from a dynamically generated menu for each of the columns in their data sources. They will be offered different operations based on the shape of the query and content of the column, such as adding to the group by clause, aggregating with a relevant function or applying and removing specific filters. The auto-completer also uses the new SQL awareness to know what tables and columns it should suggest based on the current schema and data source of the query.
The motivation for implementing this feature was fairly simple: writing SQL is tedious. Most SQL environments rely on the users to be able to translate what they want to do into code. They must also interpret and refine their results based on their own knowledge of the language. This burden was placed on the user because the query view had no way of understanding peoples intentions. The parser makes the query view SQL aware and so it can now do some of that understanding and creation of the query, removing that burden. For novices, using the menus to add a filter or group by a column can help them avoid simple mistakes as well as potentially help them learn SQL syntax. For more experienced people using a point-and-click interaction is much faster and less tedious than having to type out a query in SQL. Hopefully, this feature will make using SQL in the Druid web-console simple and pleasant.
Learning SQL can be difficult and may require many resources.
How it works
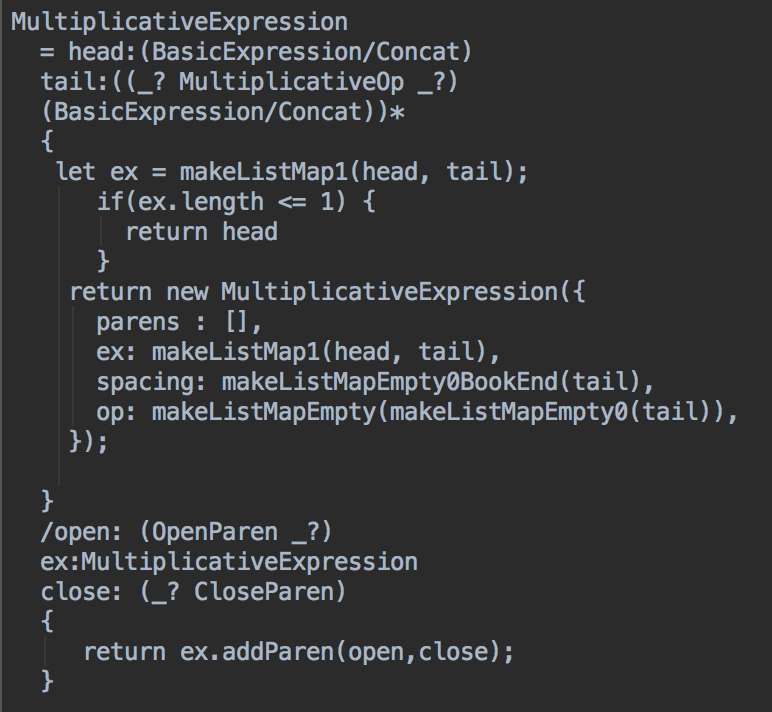
Essentially, what we created is just souped up parser. The end goal is to take the input and create an abstract syntax tree, however, some transformation of the input is required to make the output meaningful. The parser works by matching the SQL against a series of rules called a grammar. When a part of the SQL matches against a rule an object of that class is generated. This object stores the information from the query as well as the formatting which will allow it to be “stringified” in the future. All of these objects are recursively assembled into an abstract syntax tree. This abstraction of the SQL is what allows the query view to understand the current query. When the you first navigate to the view, the saved query is parsed and used to generate the defaults that dictate the available menus. As the you type or click to change the query the parsed text input is stored on the state of the application and updated as it changes.
It would be impossible for the compiler to handle every possible input, because of this we made sure to create a robust fallback state. However, should the parser not be able to parse the input, we didn’t want to just revert back to the old functionality of the view. While usable, it would ruin the flow of the view and could be confusing. As an effort to preserve some of the new features, a safe failure state was implemented that allows the you to copy column names, values or certain specific pieces of SQL. Even though you still need to paste the new piece of code yourself, it is still faster than typing it out and is guaranteed to be syntax error-free.
How we built it
The process of building the parser was iterative and test-driven. This project was ideal for test-driven development, because you know what the input will be and exactly what you should be outputting. Each view in the Druid console has a query associated with it, and so I used these as my initial test cases. I needed to make sure each query could be converted to an AST but also returned to the original text while preserving its spacing. I used Jest to generate tests and check my code throughout the development process.
The tool itself was written using PegJs, TypeScript, and JavaScript. It has been published as an npm package and the code is available on Github.
The first step in the build process was really just to prove to myself that I could build a working parser. In this version, I wrote a PegJs grammar that returned the whole tree as a JSON object with each branch of the tree capturing its type as text. Each rule would match on the space immediately in front of it so it could be returned to text in one big recursive switch statement. This was a low fidelity prototype that had many opportunities for improvement. One such opportunity we found was that even though capturing the spacing in front of every rule made re-stringing the query simple it meant the parser had to go through every rule before it could match, which was not efficient.
It was at this point that we decided we needed to use classes. Making each rule create a class would allow for it to have its own instance variables and methods which could be leveraged to solve some of the problems we were seeing. Each object could now preserve the spacing inside of a rule and reapply it in a custom function. This allows the parser to work faster as every rule has a unique beginning which means quicker rejection of rules. Additionally, adding parentheses became simpler as you could call a function to add them to an object instead of capturing them before the object was created.
Once we were happy with how it was parsing the SQL, we began to add various functions to the library to help manipulate the query. We started with a few simple functions like sorting and adding a filter to the WHERE clause. Helper functions were also included to more easily create objects to pass in as arguments to these various functions. Once we had a few basic functions working, it became easier to add more to the project as ideas were suggested.
What’s next
I don’t think that we have fully exhausted functionality of this feature yet. As someone who struggles with formatting I think it would be really cool to also hard code the spacing, to allow the opportunity to fix your spacing automatically like prettier does. This wouldn’t be hard to implement as only a few lines of code would need to change and it could be a nice quality of life addition. Another feature I would be interested in adding is support for JOIN’s. Of course, more support for joins in Druid SQL would be necessary before this would be useful. From a design stand-point I think that implementing drag-and-drop could be a in interesting challenge and might feel more natural as the view would better map to the thought process of the user. Lastly, I think it could be interesting to add a highlight feature where instead of filtering on a certain value it would be highlighted in the results table. This could be useful if you are trying to understand the frequency of a result in a data set without removing the other results.
Some final thoughts
The goal when creating an interface is to create the most seamless and comfortable experience for the user. This is done by building an environment that matches the thought process of the user as closely as possible. In order to to this though, the view needs to understand the users intentions, which requires information. Most people don’t think in SQL syntax, they think about a column and what action they want to preform, the parser allows us to match this pattern of thought by giving us information about the users intentions. It is our hope that with this new tool we are pushing the boundary of what an SQL environment can be. The current implementation removes some of the burdens on the person to know exactly what they want to do, and to do it perfectly. Novices no longer need to explicitly know how to manipulate and query their data, and more experienced people can craft a query more quickly and effortlessly than ever before. Of course, there is still room for many more edge cases and features, but even so, I am confident that because of our work the Apache Druid web-console is one of the most innovative and user-friendly query environments available.
If you are interested in seeing the new features in action, check out the 0.16 release
Other blogs you might find interesting
No records found...
Mar 31, 2025
5 Reasons to Use Imply Polaris over Apache Druid for Real-Time Analytics
Introduction Real-time analytics is a game-changer for businesses that need to make fast, data-driven decisions. Whether you’re analyzing user activity, monitoring applications and infrastructure, detecting...
We are excited to announce the release of Apache Druid 32.0. This release contains over 341 commits from 52 contributors. It’s exciting to see a 30% increase in our contributors!
Druid 32.0 is a significant...
We’ve made a lot of progress over the past decade. As we reflect upon the past year, we’re proud to share a summary of the top 2024 product updates across both Druid and Imply.
2024 was a banner year,...