Apache Druid® is an open-source distributed database designed for real-time analytics at scale.
We are excited to announce the release of Apache Druid 31.0. This release contains over 525 commits from 45 contributors.
Druid 31.0 is a transformative release, moving the Druid database into a multi-profile era where performance and cost can be easily adjusted to meet the demands of even more use cases.
Druid 31 introduces a new profile for the query engine that enables highly complex queries to operate at interactive speed, including high-cardinality GROUP BY.
At the same time, Druid adds enhanced capabilities across the board, including SQL window functions and an enhanced Data Explorer in the Druid console.
Brand new engine
Druid 24.0 introduced a new multi-stage query engine, also known as MSQ, capable of executing complex queries directly from deep storage. This profile is invaluable for offline query workloads where low latency, sub-second query results is not a requirement.
As the number of use cases for Druid continued to expand in 2024, it became clear that a single mode of operation for MSQ only solved part of the problem.
Some developers wanted to run queries through MSQ concurrently. Others wanted to be able to run even more complex queries. Something needed to change to allow developers to take full advantage of as many resources as needed, allowing for an increase in concurrency and in performance. It was time for Druid to introduce the concept of query profiles.
In addition to the established Druid interactive query profile and the MSQ profile from Druid 24, Druid 31 adds a new experimental profile – Dart. Dart opens up Druid to support a wider range of workloads, often alleviating the need for additional infrastructure.
Dart is designed to support highly-complex queries, such as large joins, high-cardinality GROUP BY, sub-queries and CTEs. These are the types of query commonly found in ad-hoc, data warehouses, and they will be familiar to developers using Apache Spark and Presto.
The Dart profile is powered by a new query engine that is fully compatible with current Druid query shapes and the Druid storage format. The Dart query engine is a revolution in query engine design: it uses multi-threaded workers, conducts in-memory shuffles, and accesses locally cached data directly, rather than reading from deep storage.
Follow this guide to enable the Dart profile and try it for yourself! Once enabled, you’ll find a new option in the web console – “SQL (Dart)”. Use POST to /druid/v2/sql/dart/ with the same JSON payload that you would use on /druid/v2/sql/. The result format is the same as the result from /druid/v2/sql/.
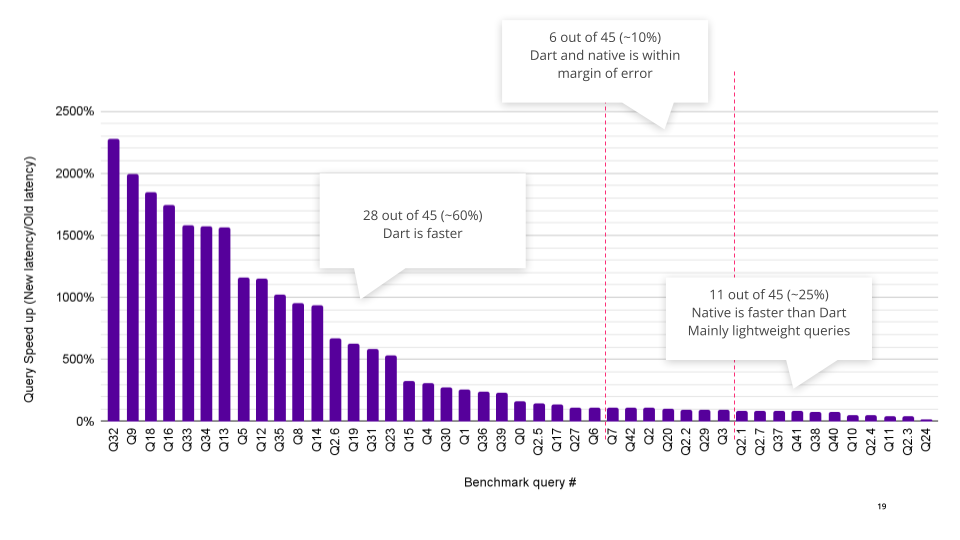
As you can see, the performance of the new Dart engine is quite impressive. We’d love you to give it a shot and give us feedback in the community.
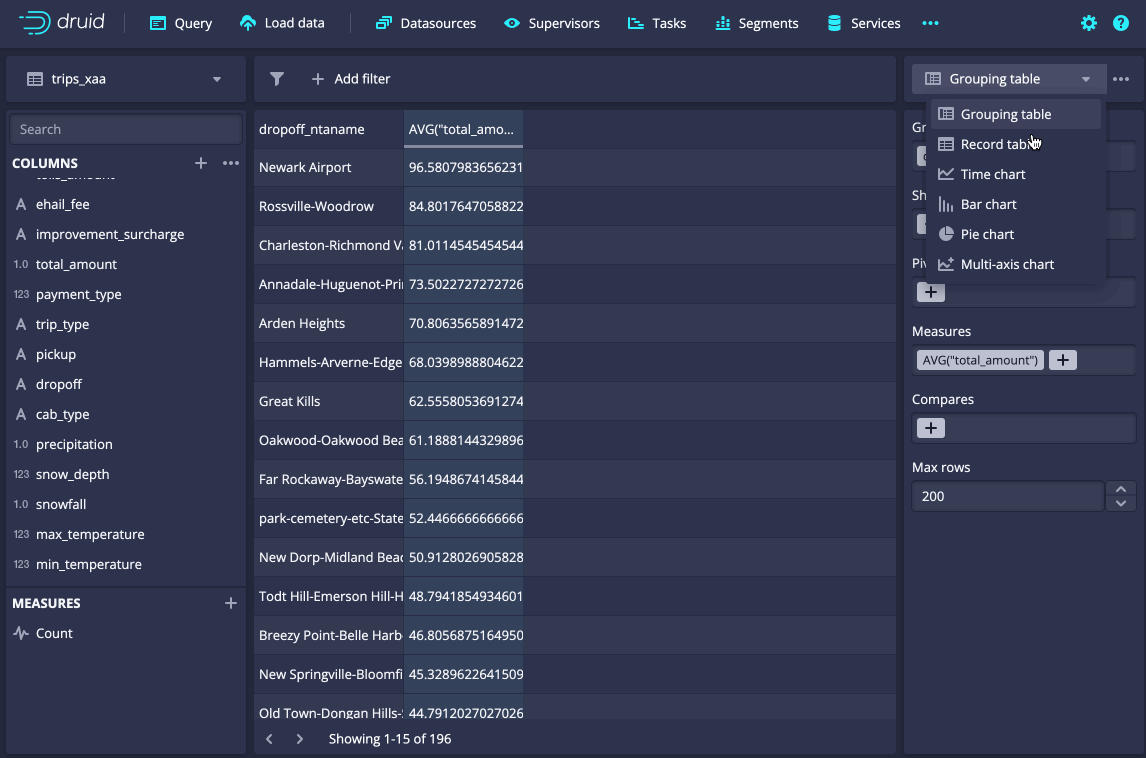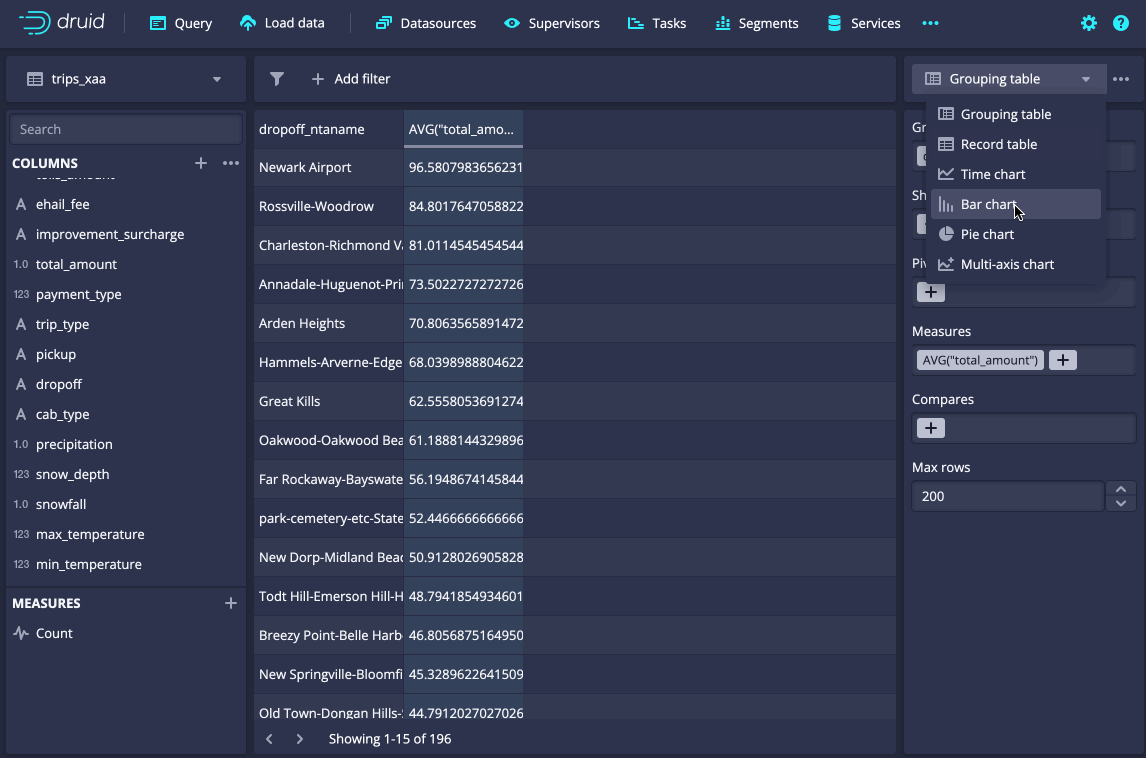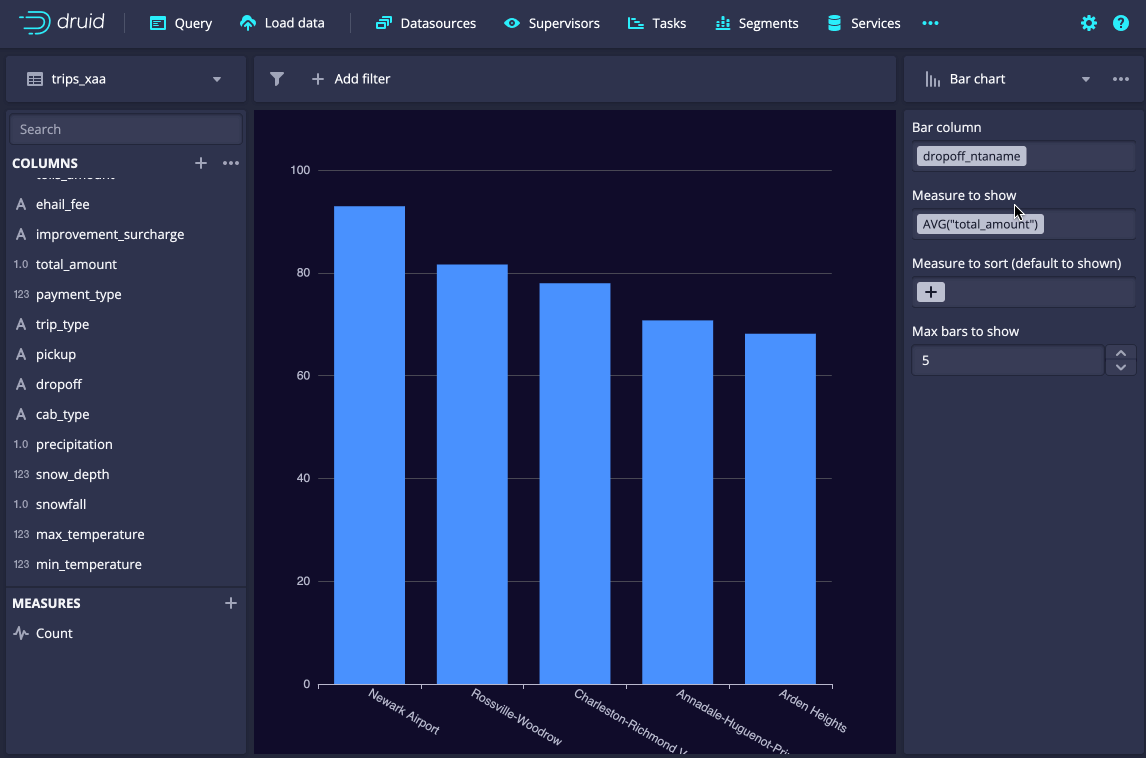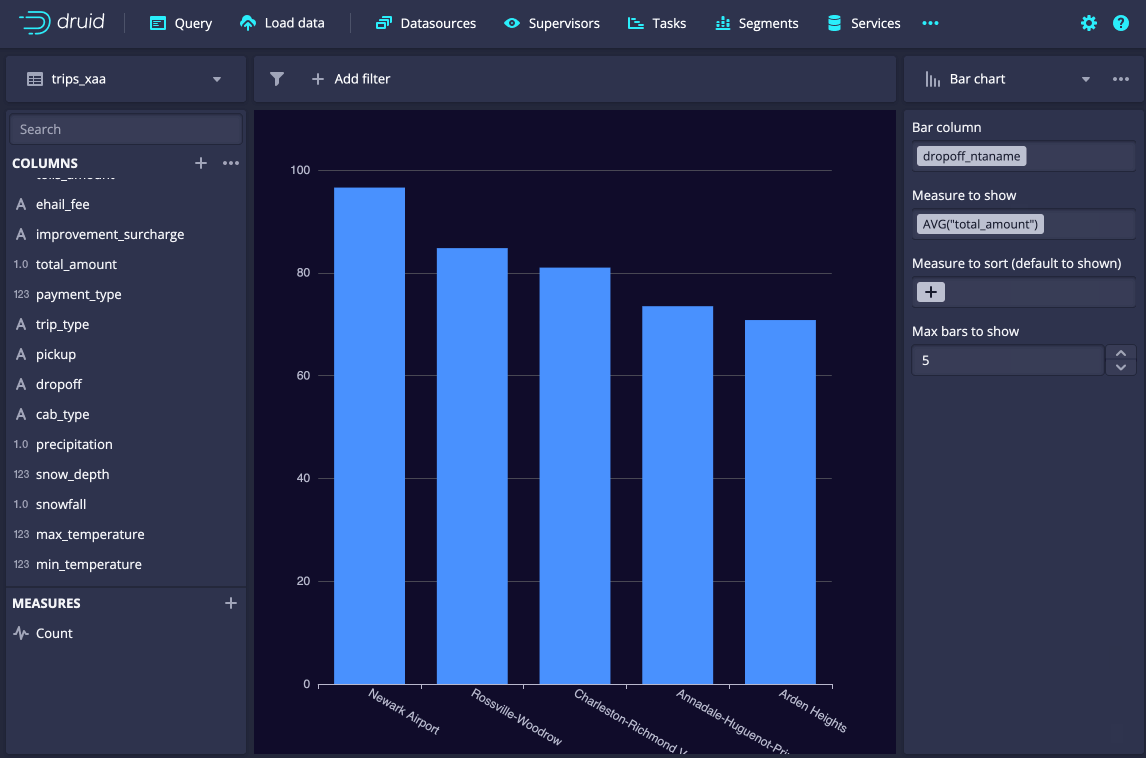
Explore view
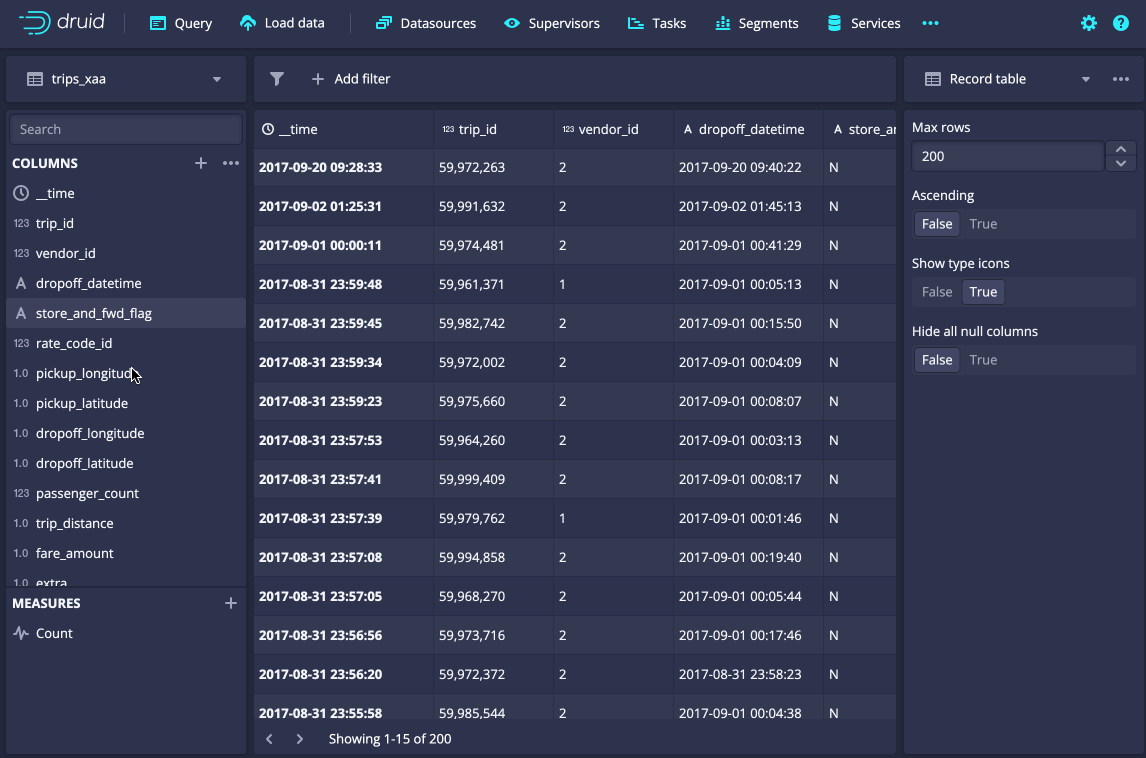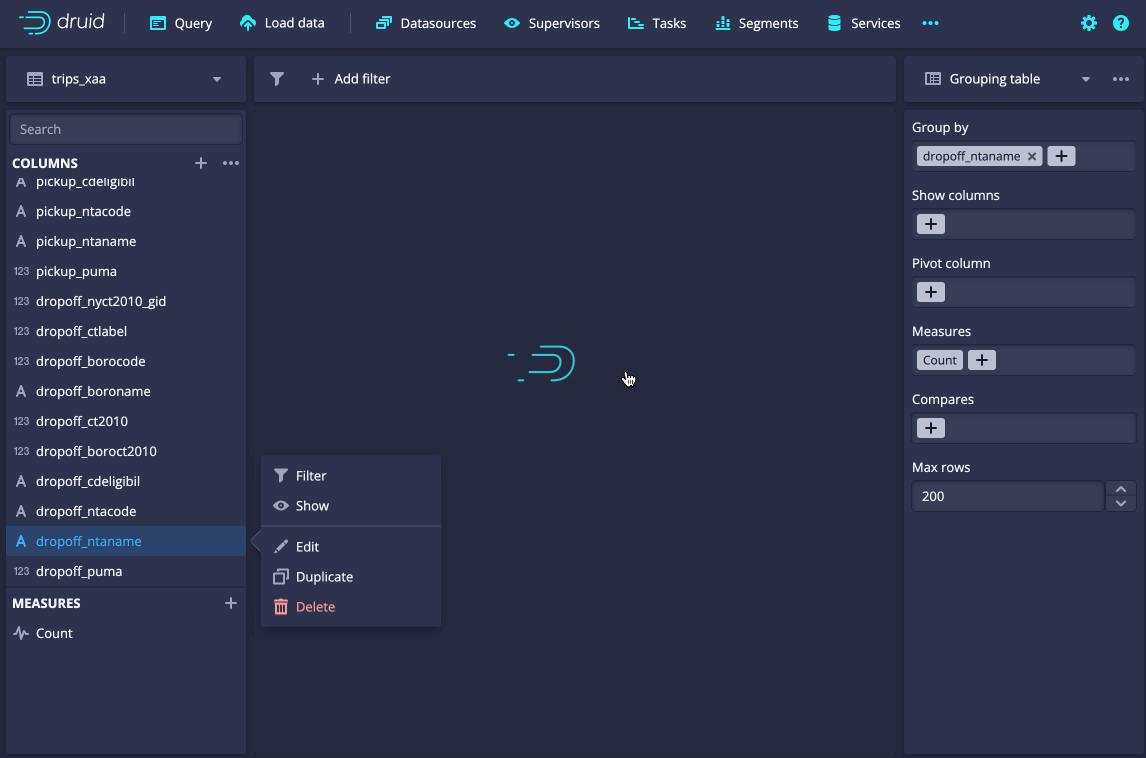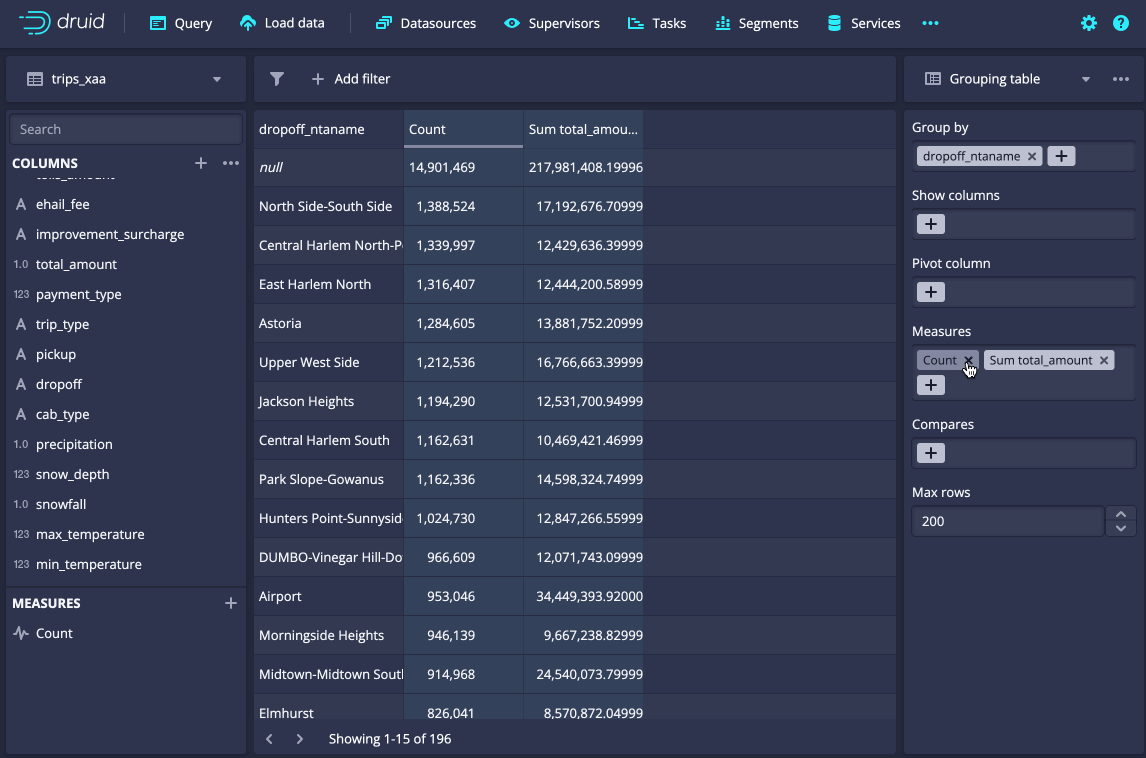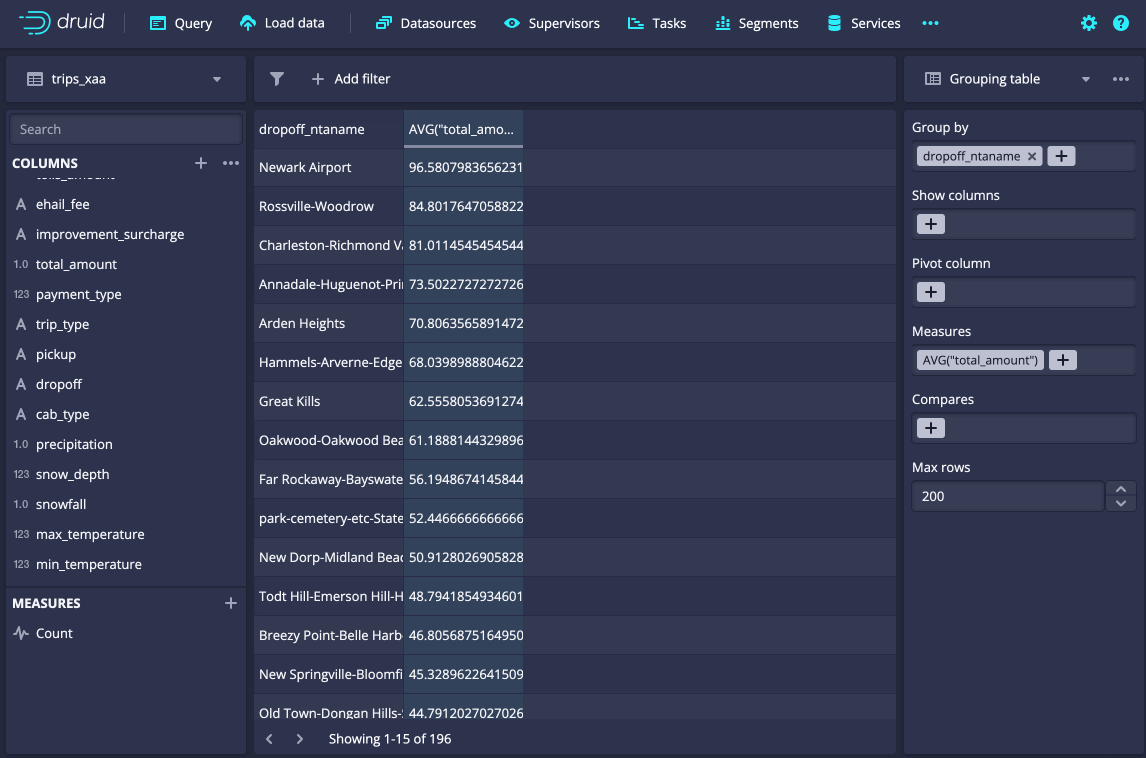
The Explore view, first introduced in Druid 27, enables interactive exploration of data direct from the console, making it an all-in-one tool for exploring and getting the most out of the dataset you have.
Along with an access control UI introduced in previous releases, Druid 31’s enhancements allow a wider range of users to get access to data without needing to learn SQL.
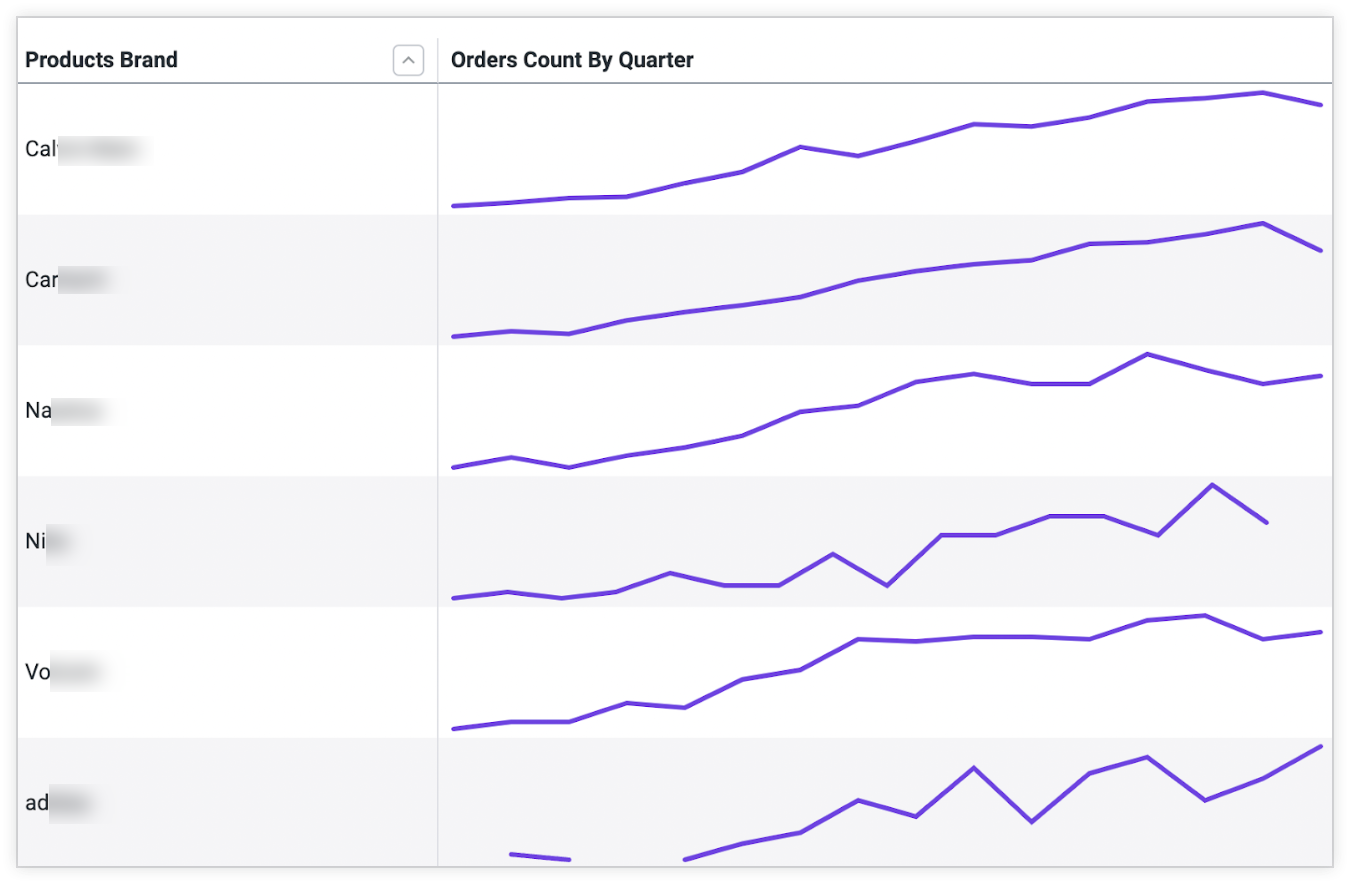
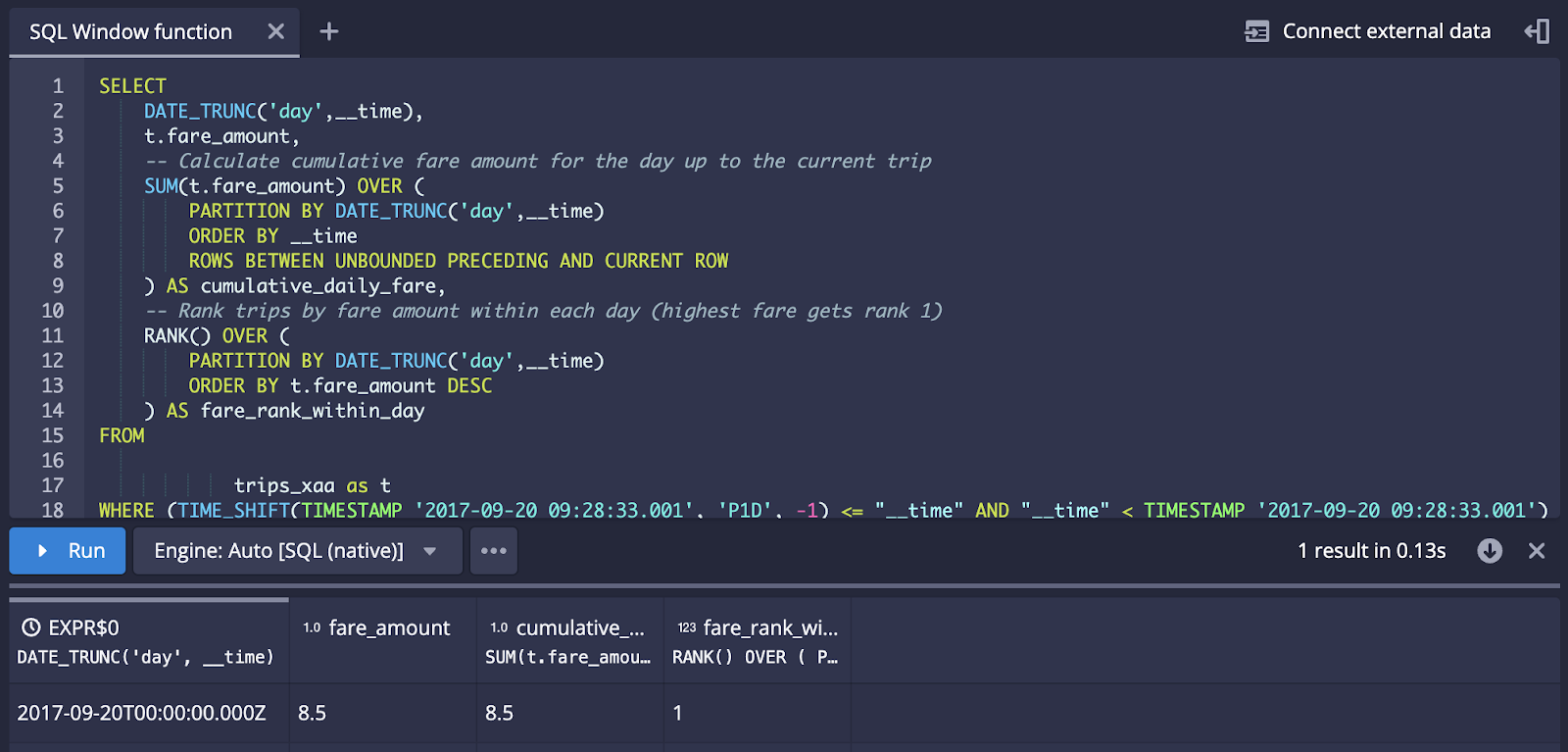
SQL Window functions
SQL Window functions are ideal for doing categorized analysis, such as sparkline visualization as well as doing analysis such as cumulative sums and trend analysis.
The community has been hard at work through Druid 29 and Druid 30 to address limitations and issues around SQL window functions in Druid. Druid 31 adds support for executing SQL window functions with the MSQ engine, addressing all known correctness issues.
Through MSQ, Druid now supports a wide variety of SQL window function query shapes, and as you can see in the example below.
Compaction improvements
Compaction is an automated house-keeping feature in Druid, laying out table data optimally behind-the-scenes, keeping query execution efficient. The community has rallied to support compaction users, especially those relying on auto-compaction in streaming use cases.
Here are the 3 critical areas of improvement in Druid 31:
Concurrent append and replace is coming out of experimental mode after stabilization and testing at scale in large-scale production deployments since its introduction some releases ago. This feature allows streaming data to be compacted even when late arrival data is causing fragmentation. You can turn this feature on by following the guide here.
Supervisor-based compaction scheduling is an experimental feature that allows compaction tasks to be scheduled just like a regular supervisor-managed task, such as a streaming ingestion task. Historically, compaction tasks have been scheduled separately from all other task types. This poses challenges when users try to balance resources between ingestion tasks and compaction tasks. It also poses challenges around scheduling, failure retry, and prioritization on which intervals to compact. The supervisor-based compaction scheduler resolves those issues and allow the cluster to reduce fragmentation rapidly. To learn more on how to use this new feature, please follow this guide here.
MSQ based auto-compaction is a new mode of compaction system. As you may know, MSQ engine is very efficient at data processing. With the supervisor-based compaction scheduler, we can now schedule MSQ tasks to complete compaction. MSQ-based auto-compaction is faster, more memory efficient, and less prone to failures when processing large amount of data. Once you turn on supervisor-based compaction scheduling, you can turn on MSQ-based auto-compaction at a cluster level by setting `druid.supervisor.compaction.engine` to `msq` in Overlord’s runtime config, or set `spec.engine` to `msq` at a compaction supervisor task level if you want to enable this per datasource.
In upcoming releases, we’ll continue to graduate those features and address any stability or functionality gaps.
Try this out today!
For a full list of all new functionality in Druid 31.0.0, head over to the Apache Druid download page and check out the release notes.
Try out Druid via Python notebooks in the Imply learn-druid Github repo.
Alternatively, you can sign up for Imply Polaris, Imply’s SaaS offering that includes Druid 31’s production quality capabilities and a lot more.
Stay Connected
Are you new to Druid? Check out the Druid quickstart, take Imply’s Druid Basics course, and head to the resource-packed Developer Center.
Check out our blogs, videos, and podcasts!Join the Druid community on Slack to keep up with the latest news and releases, chat with other Druid users, and get answers to your real-time analytics database questions.