An upsert is a database operation that will update an existing row if a specified value already exists in a table, or insert a new row if the specified value doesn’t already exist.
Upserts are particularly useful for two key reasons:
Data Consistency. Upserts ensure that data remains consistent by either updating existing records or adding new ones.
Efficiency. Upserts combine the insert and update operations into a single action, reducing the number of database queries and improving performance.
In this blog, we’ll discuss how we support upserts in Imply Polaris for a variety of use cases.
Using Dimension Tables in Polaris
Today, Polaris supports a smaller version of an upsert that we are calling a Dimension Table. Fundamentally, they are database tables that store the latest snapshot of attribute data that changes over time. Uniquely, in Polaris, they can be hooked up to an event streaming pipeline like Kafka to upsert the latest attributes and then JOINed at query time for instantaneous change consumption.
They are distinct from fact/event tables in that they are not well-suited for transactions—but are beneficial in two primary ways:
They are intuitive to understand and implement, dimension tables make it easy for end users to find the data they need.
They are great for simple queries.
Dimension Tables support ingestion from Kafka, MSK, and Confluent Cloud, as well as near-instant updates of data and deletion events.
Let’s examine how Dimension Tables work.
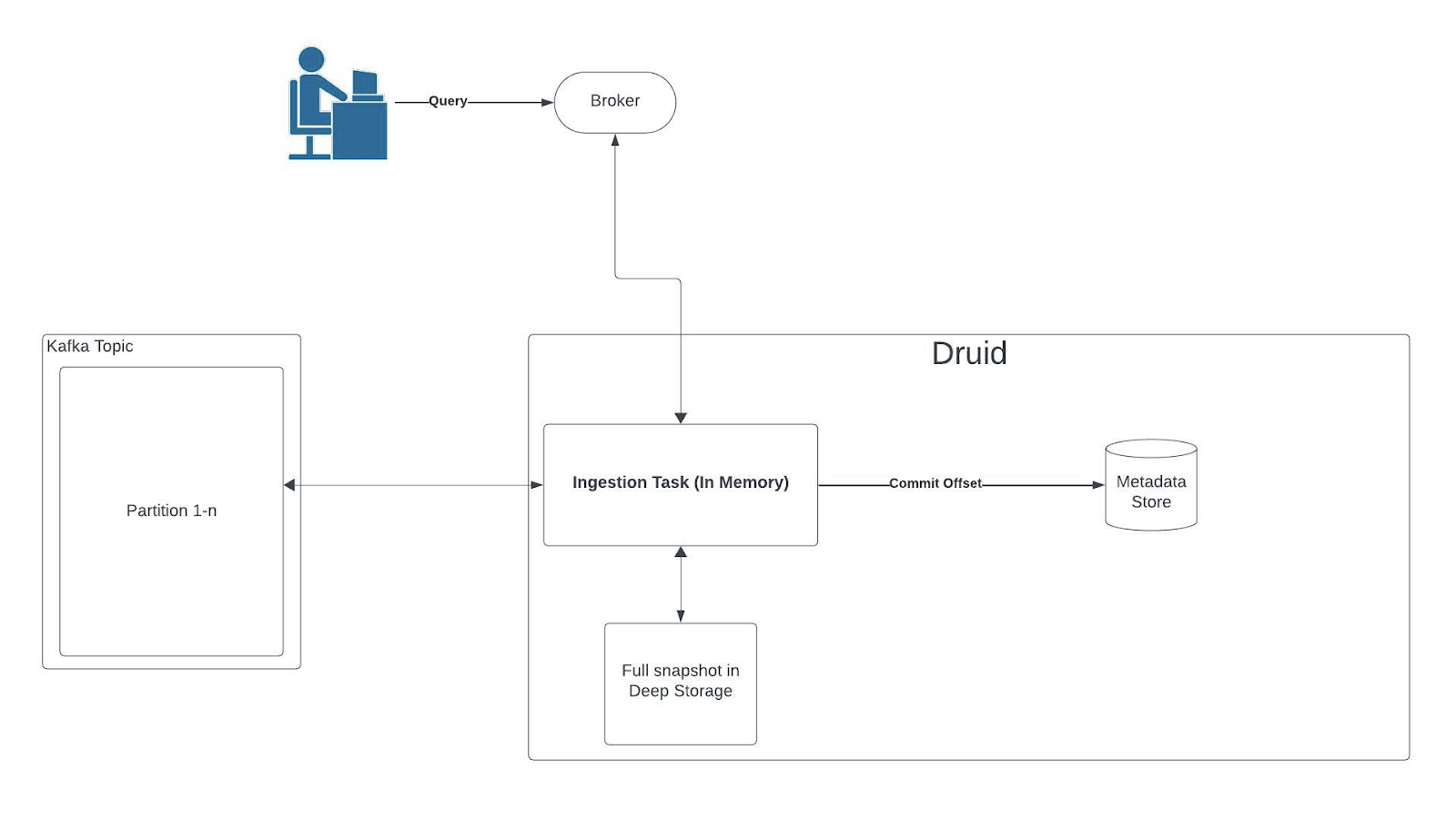
Dimension Tables are populated from Kafka via a change data capture mechanism.
Data comes in a single topic, Imply Polaris reads the entire topic, creates the table, and updates it.
Every 30 minutes, we write a snapshot to deep storage and the Druid task cycles and starts again.
A user can use a JOIN to combine data in that Dimension Table with event data in a separate table in Polaris for a wide range of tasks, such as building a line chart that provides a global view of all their IoT assets in real time.
Today, we have a few customers using these new tables in a production environment. MetaCX, which creates an analytics platform for impact-driven organizations, uses Dimension Tables to identify normalization for customer-provided data without requiring denormalization.
“Polaris Dimension Tables make it possible for us to perform live identity normalization without having to re-ingest raw events when identity mappings are updated. With support for multiple columns, they’re the logical successor to Lookup functions.”
—Jason Schmidt, Software Architect, MetaCX
The advantages of using Lookups in Apache Druid
Today, Lookups in Apache Druid are a way to manage changing dimension values over time. They are essentially key-value maps that associate a dimension value with a specific time interval.
Lookups are useful in scenarios where the attribute values of a dimension can change, such as:
A customer’s address changes when they move, so an ecommerce platform uses Lookups to associate different values of the “address” dimension with specific time intervals.
A team uses Lookups to enrich data with external information, such as mapping a user ID to corresponding demographic data in a different table.
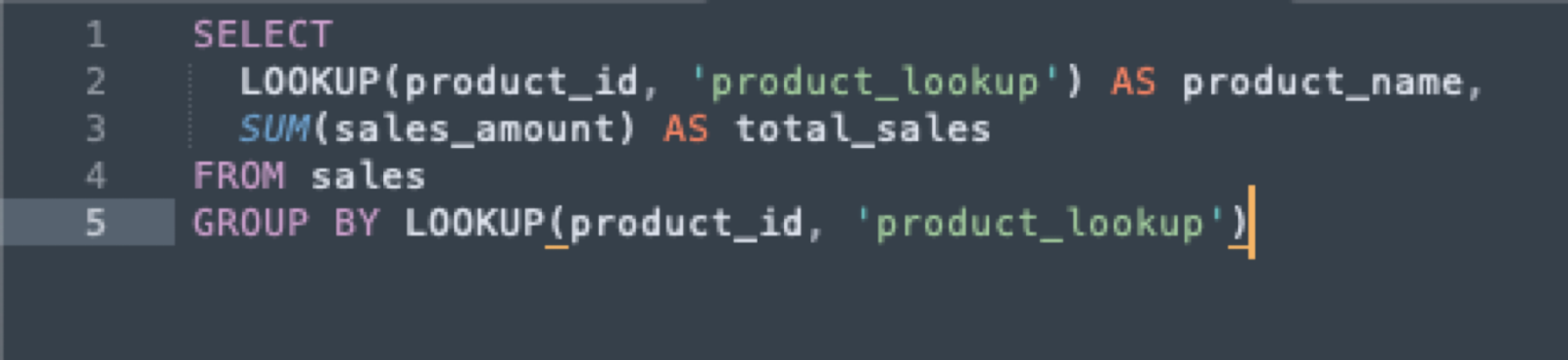
In this example, the Lookup function is used to retrieve the “product_name” from the “product_Lookup” table based on the “product_id” dimension.
To put it simply, Dimension Tables have two primary advantages over Lookups: they’re easy to set up and maintain, and they can effectively leverage JOINs.
Making updates to data in near-real time with Kafka-based Lookups presents a few challenges. In this case, the customer sets up a Kafka topic (containing key-value pairs) for the Lookup data. Some external system publishes the Lookup data to the Kafka topic and Druid subscribes to that topic. Druid then continuously ingests the updates and makes them available at query-time.
The problem is that the larger the dataset is, the longer it takes for Druid to read the whole topic. There’s a risk that Druid serves queries with partial data and at high latency.
While wonderful for small Lookup tables, they do not scale well when handling large Lookup data sets. If you have the same key and multiple dimensions you want to Lookup against, you need to have separate Lookup tables for each value.
With Dimension Tables, one simply needs one table that contains all the data that needs to be JOINed on at query time.
Dimension Tables are a different and improved way to achieve the same outcome as a Lookup table in open source Druid—one involving a more simplified setup while leveraging JOINs.
Looking to the Future
The addition of the Dimension Tables feature is the first stage of our Upsert roadmap. We are currently working on these additional capabilities for immediate release:
More event throughput
CDC input sources via Debezium
Upserts for entire event tables
We have seen a growing demand to support JOINing decorative metadata with event transactions at scale. Polaris’s ability to support JOINs at query time in conjunction with Upserts can unlock analytics at hyperscale.
Other blogs you might find interesting
No records found...
May 07, 2025
Real-Time Observability Without Operational Overhead: What’s Next?
Observability is meant to provide clarity, speed, and confidence in modern systems. Yet for many organizations, it has become a source of complexity, cost, and operational drag. Managing pipelines, tuning...
It’s Time to Rethink Observability: The Event-Driven Future
Observability has evolved. Forward-looking teams are already moving beyond static dashboards and fragmented telemetry—treating all observability data as events and unlocking real-time insights across their...
5 Reasons to Use Imply Polaris over Apache Druid for Real-Time Analytics
Introduction Real-time analytics is a game-changer for businesses that need to make fast, data-driven decisions. Whether you’re analyzing user activity, monitoring applications and infrastructure, detecting...