Apache Druid® is an open-source distributed database designed for real-time analytics at scale.
Apache Druid 26.0 contains over 411 commits (+40%! from 25.0) & 60 contributors (+7% from 25.0)
As part of the Druid developer community, we are always looking for ways to improve the performance and functionality of our data processing systems. That’s why we are excited to share with you some of the cool features we are working on. We hope you can adopt Apache Druid for a broader range of scenarios with the introduction of these new features. So let’s dive in and explore what’s new in this exciting evolving technology.
Schema auto-discovery
Defining the data type of every dimension ingested into a Druid table can be a lot of work. Plus, what do you do when today’s source data doesn’t exactly match the structure of previous source data? Usually, you just get error messages until the schema is made to match.
Previously. With this feature, the data type of each incoming field is detected. When those future ingestions have added, dropped, or changed fields, you can choose to reject the nonconforming data (“the database is always correct – rejecting bad data!”), or you can let schema auto-discovery alter the table to match the incoming data (“the data is always right – change the database!”).
There are several benefits:
Time-saving: Manually defining schemas for each new data source can be time-consuming and error-prone. With schema-auto discovery, Druid can automatically detect and infer the schema of each datasource, saving significant time and effort.
Flexibility: In the modern data ecosystem, the schema of incoming data can change frequently. With schema auto-discovery, the ingestion system can automatically adapt to these changes without requiring manual updates to the schema definition.
Scalability: Ingesting large volumes of data can be challenging, especially when the schema of the data is unknown. With schema-auto discovery, the ingestion system can scale to handle large volumes of data from multiple sources without requiring manual schema definitions.
Improved data quality: When data is ingested with an incorrect schema or structure, it can result in data quality issues, such as data loss or data corruption. With schema-auto discovery, the ingestion system can automatically detect and correct schema errors, avoiding data quality errors.
Reduced risk: Manually defining schemas can introduce human error, which can cause downstream issues. With schema-auto discovery, the risk of human error is reduced, resulting in a more reliable and consistent ingestion process.
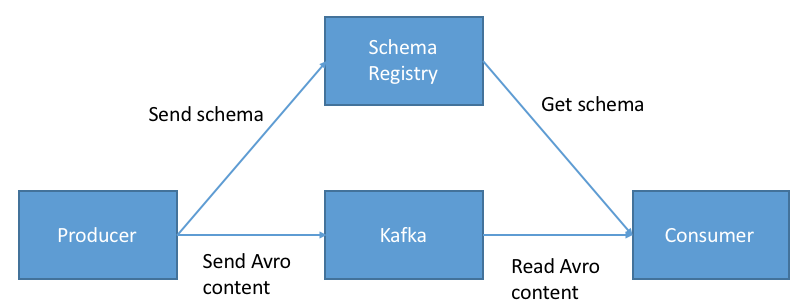
We’re adding schema auto-discovery capable of inferring types from upstream sources where the schema is available; this includes Parquet, Avro, and other file formats compatible with the schema registry.
Shuffle Joins for data ingestion
For some time, Druid has included broadcast joins, which are highly performant. This, however, has a limit on the scale of data you can join.
A shuffle join partitions data across multiple nodes in a cluster and then reshuffles to bring together the data needed for the join operation. Shuffle joins can be useful where large volumes of data need to be processed and joined together.
Here are a few examples of where shuffle joins can be useful:
E-commerce: Analyze customer behavior, such as understanding what products are frequently purchased together or which products are most commonly abandoned in online shopping carts. You can gain insights into shopper behavior and preferences by joining data from multiple large tables, such as customer transactions, website logs, and customer reviews.
Trading Data: Investigate large volumes of financial data, such as stock prices, trades, and financial statements. By joining data from multiple large tables, you can identify trends and patterns that can be used to inform investment decisions and risk management strategies.
Healthcare: Bring together patient data from multiple sources, such as medical records, lab results, and health surveys. By joining this data together, healthcare providers can gain insights into patient health outcomes and identify areas for improvement..
Advertising: Combine data from multiple large tables, such as ad impressions, clicks, and conversions. By joining this data together, you can gain insights into which ad campaigns are most effective and optimize advertising spend.
We’ll be providing the support of shuffle joins during data ingestion and simplifying the process of preparing data for Druid queries.
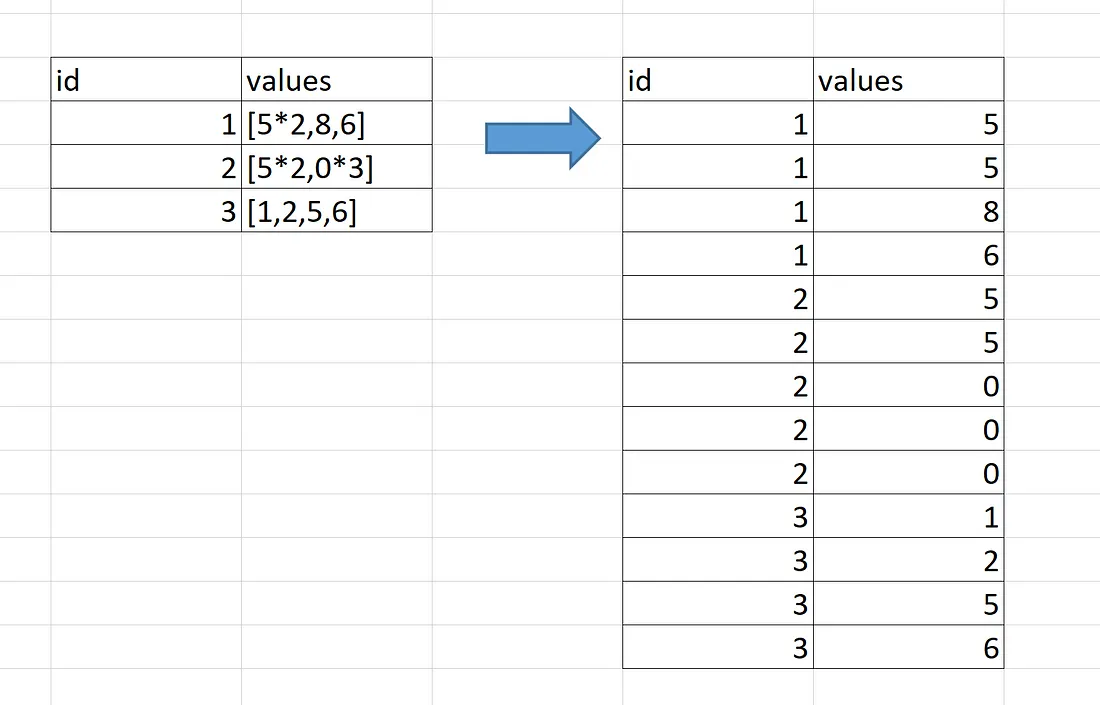
SQL UNNEST is a command that converts nested arrays or tables into individual rows. The UNNEST function is particularly useful when working with complex data types that contain nested arrays, such as JSON.
For example, suppose you have a table called “orders” with a column called “items” that contains an array of products for each order. You could use the UNNEST function to extract the individual products and their quantities as follows:
SELECT order_id, item_name FROM orders, UNNEST(items)
This would produce a result set with one row for each item in each order, with columns for the order ID and the item’s name.
Part of what’s cool about UNNEST is how it allows a wider range of operations that weren’t possible on Array data types. This lets us introduce the new and improved Array data type.
An array data type is a data type that allows you to store multiple values in a single column of a database table. Arrays are typically used to store sets of related data that can be easily accessed and manipulated as a group:
Storing multiple values in a single column: Instead of creating separate columns for each value, an array data type allows you to store multiple values in a single column. For example, if you have a table for blog posts, you could use an array data type to store tags associated with each post. This could be done using multi-value dimensions in Druid, but multi-value dimensions are not ideal for handling null cases.
Simplifying queries and calculations: When data is stored in arrays, you can use array functions to streamline queries and calculations. You can use the ARRAY_AGG() function to group values together into an array, or you can use the UNNEST() function to break an array apart into individual rows, as mentioned above.
Handling variable-length data: Arrays are flexible and can handle variable-length data. This is useful when you don’t know how many values you will need to store in advance.
It’s worth noting that not all database systems support array data types. Some popular databases, such as MySQL and Microsoft SQL Server, do not support arrays. Druid, a modern database where arrays are commonly required, fully supports array data types.
For a full list of all new functionality in Druid 26.0, head over to the Apache Druid download page and check out the release notes!
Stay Connected!
Are you new to Druid? Check out “Wow, That was Easy” in our Engineering blog to get Druid up and running.
Check out our blogs, videos, and podcasts! Join the Druid community on Slack to keep up with the latest news and releases, chat with other Druid users, and get answers to your real-time analytics database questions.
Other blogs you might find interesting
No records found...
Jul 24, 2026
Why You Shouldn’t Have to Delete Your VPC Flow Logs
When a security incident happens, investigators almost always start with the same questions: Which systems communicated? Where did the traffic originate? What changed before the incident? Was data exfiltrated?...
Splunk Smartstore vs Lumi Loglake: Two Very Different Ways to Search Logs in Object Storage
One copies data back before it can be searched. The other queries it where it lives. Lumi Loglake lets Splunk teams query logs directly in object storage, including AWS S3, Delta Lake, Apache Iceberg, using...
Supercharging Schema-On-Read: Logs in Object Storage Don’t Need a Data Catalog
Machine data architectures are rapidly changing. As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3....