Bring all the data and users you want. Druid handles it with the best economics.
- Coordinated processing
- Unique hybrid architecture
- Efficient storage engine
Provide interactivity
on any data set
Bring on thousands
of concurrent users
Hyper growth
without hyper cost
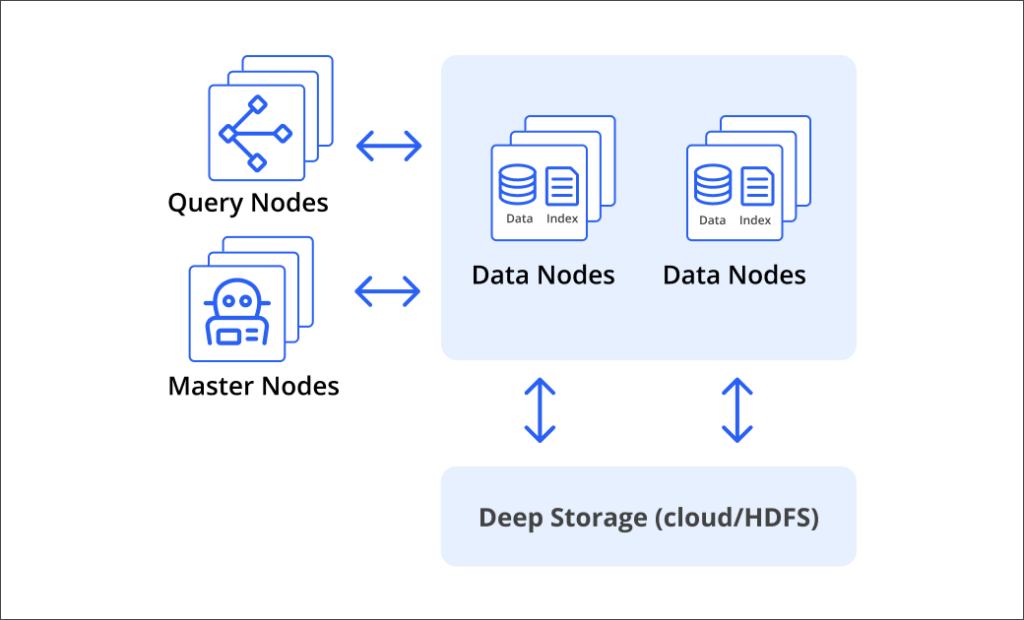
Coordinated Processing
Ready to grow. And grow. And grow.
Druid attains sub-second response at any scale because it coordinates workloads with three scalable node types:
Data: manage manages ingestion and stores data
Query: process queries with massive parallelism
Master: manage overall health, including balancing data
Most analytics databases have only query nodes, leaving the rest of the management burden to you as your application grows.
Unique Hybrid Architecture
Performance? Flexibility? Get both.
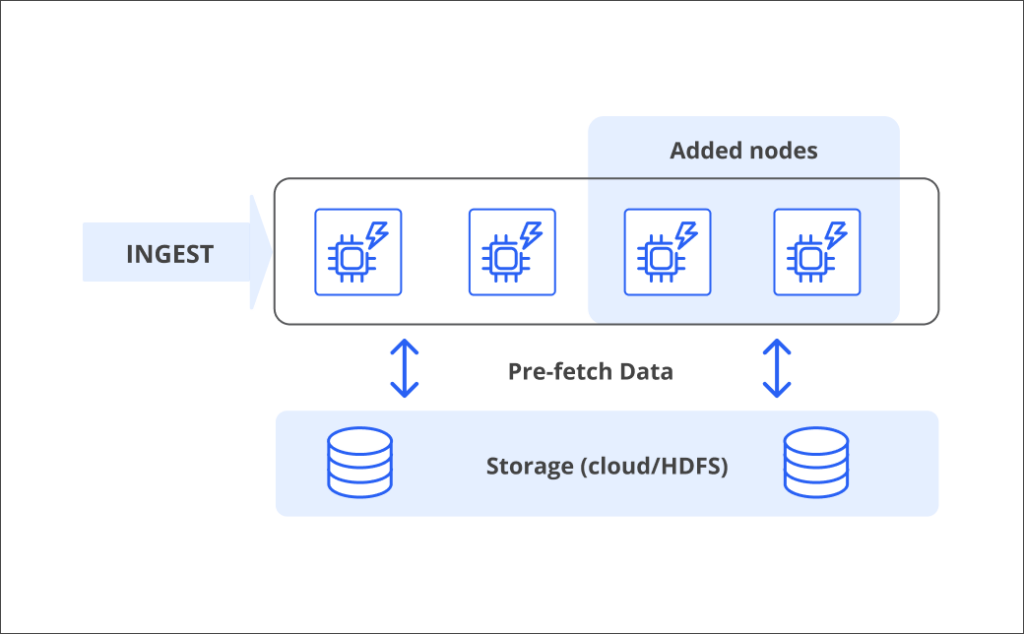
Druid’s sub-second performance is possible even with unlimited growth, thanks to a unique relationship between storage and compute. You get the query performance of local storage (shared nothing) with the flexibility of separate storage-compute.
Data is pre-fetched from deep storage to compute, meaning you never worry about a cache miss. Adding or removing nodes is simple, with no downtime or manual rebalancing.
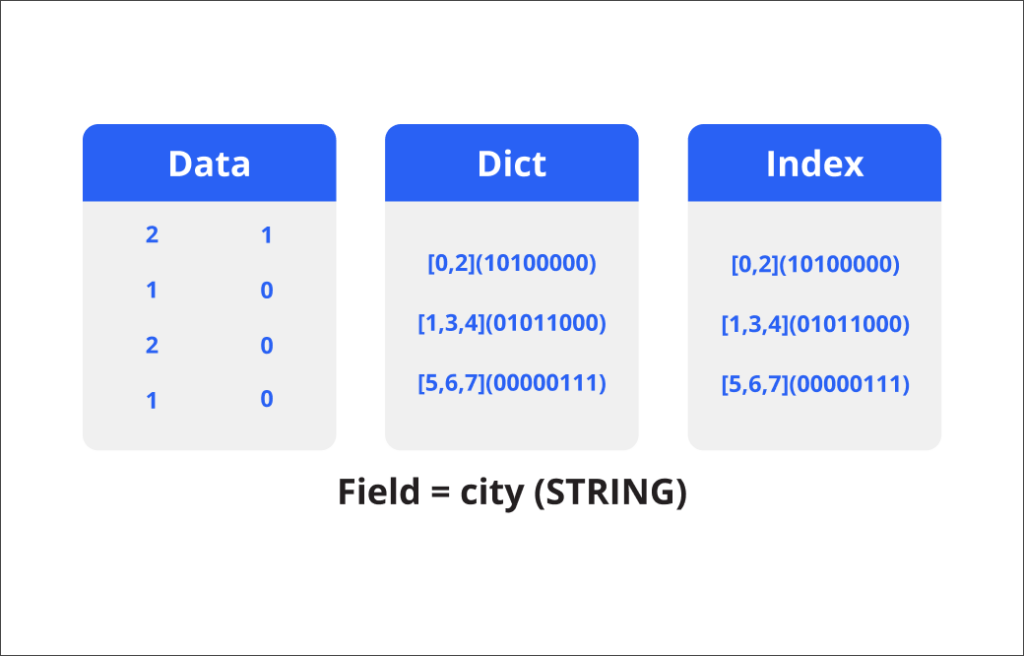
Efficient Storage Engine
Big power in a small package
Druid data segments are columnar, compressed, and automatically indexed so you get maximum performance with minimal effort and resources. With everything close together, traffic is minimized. Most Druid use cases involve massive amounts of read-only data organized by time – perfect for this efficient storage design.
Learn more about Apache Druid
An introduction to Apache Druid
Druid flexible, efficient, and resilient design make it the best choice for modern analytics application. Here’s a quick but technical overview of what makes Druid different.
An introduction to Analytics Applications
The world of analytics is shifting from traditional Bill solutions designed by data engineers to custom applications created by developers. Learn what this is all about and what it takes to build successful analytics application.
Try Apache Druid for yourself. Get started in minutes with Imply Polaris. No credit card required
More ways to support your Druid journey


Druid University
Grow your knowledge with Druid videos and accreditation courses.
Join the University →

Druid Meetups
Engage with other Druid believers. Share knowledge. Expand your network.
Attend a Meetup →

Druid Stories