Introduction
Data is the lifeblood of modern business, government, and institutional operations—it can uncover risks, fuel mission-critical systems, and inform decisions at every level of an organization. In the coming years, the volume of data stemming from digital interactions, whether they involve individuals or machines, is projected to grow exponentially1.
As data proliferates, the ability to process, analyze, and act on it as soon as it’s created is increasingly in demand. Real-time data management and analysis present a considerable set of challenges for data teams responsible for making these data available to a wide spectrum of applications and use cases.
In the realm of data streaming, Apache Kafka® is established as an industry-leading technology due to its scalability, fault tolerance, open standards, and distributed design. Kafka has popularized data streaming in nearly every industry, with more than 80% of Fortune 100 companies having adopted the technology2. Kafka excels at moving data rapidly to and from systems, but what happens when that data needs to be analyzed as soon as it arrives? This is where Apache Druid®, a real-time analytics database built for streaming data and speed at scale, comes into play.
Druid is specifically designed for projects where time-to-insight is critical. It is capable of processing both real-time and historical data, delivering sub-second queries at scale, and handling high concurrency—invaluable attributes in the context of financial services, advertising, IoT, defense and intelligence, media, and other industries where real-time insights are key to decision-making processes.
Together, Kafka and Druid provide a powerful and robust data architecture for real-time analytics applications at any scale. Companies like Netflix, Salesforce, and Confluent leverage Druid with Kafka to power operational visibility, rapid data exploration, real-time decisioning, and customer-facing analytics on large-scale streaming data. This paper is your guide to analyzing streams in real time, detailing Druid’s seamless and complementary integration with Kafka to extend data in motion with real-time insights.
Challenges in analyzing streaming data at scale
In this era of data ubiquity, large-scale streaming data poses a unique set of challenges, which data teams need to address effectively to derive real-time insights and value. Let’s explore some of these challenges in detail.
Data Freshness
For certain real-time data, its value depends on how quickly it can be analyzed and acted upon. This time sensitivity requires systems to process and analyze data with minimal latency. Analyzing data and delivering insights while still “fresh” means ensuring consistent, sub-second query response times under high load.
Real-time in Context
In many use cases, it is valuable to combine stream data with historical data for real-time contextual analysis. Most databases are not designed to ingest and align both real-time and historical data while delivering subsecond performance. Streaming data arrives in high volumes and at a fast pace, while historical data is larger but not real-time. Integrating the two types of data requires handling varying formats, varying schemas, and ensuring data consistency.
Scalability and Elasticity
As data volumes grow, a database must scale seamlessly, either vertically (by adding more power to a single node) or horizontally (by adding more nodes). This scalability should be dynamic to handle peak loads efficiently without over-provisioning resources during non-peak times.
Fault Tolerance
Many real-time use cases require a system designed to run continuously without planned downtime for any reason, even for configuration changes and software updates. Ensuring a database is durable and will not lose data, even in the event of major system failures, is a non-trivial task.
Variety
Data diversity is another common challenge. Streaming data often comes in various formats, from different sources, with diverse schemas to serve a variety of workloads. It can be structured or semi-structured data from sources such as logs, sensors, user interactions, and transactions. This variety necessitates flexible and adaptable tools to manage and analyze the data.
Security and Compliance
Ensuring data security, privacy, and compliance with regulatory norms is an unavoidable requirement, which only becomes more difficult as data volume and velocity increase. This requirement is not only a technological challenge but also involves policy, process, and personnel considerations.
Stream-to-batch vs. stream-to-stream: Key differences and considerations
When selecting how to house data in an organization, there are two key approaches to consider: batch processing, or ‘stream-to-batch’, and real-time data processing, or ‘stream-to-stream’.
Batch processing involves analyzing and processing a set of data that has already been stored. Examples include payroll and billing systems, where data is ingested periodically. This is the status quo of data management—and it’s perfectly suitable for periodic BI reporting purposes.
Real-time data processing, on the other hand, involves analyzing and reporting events as they occur. This approach allows for near real-time analysis and is crucial for time-sensitive applications where immediate actions are required. For example, a real-time application that purchases a stock within 20 milliseconds of receiving a desired price, or a programmatic advertising system that places an ad within 300 milliseconds of a user opening a webpage.
Stream-to-batch architecture
In a stream-to-batch architecture, the incoming streaming data is first collected and stored in files, which are small subsets of the data stream. These files are then processed and analyzed using batch processing techniques (sometimes called “micro-batch” processing when there are many small files to ingest). The continuous data stream is divided into chunks that are processed sequentially.
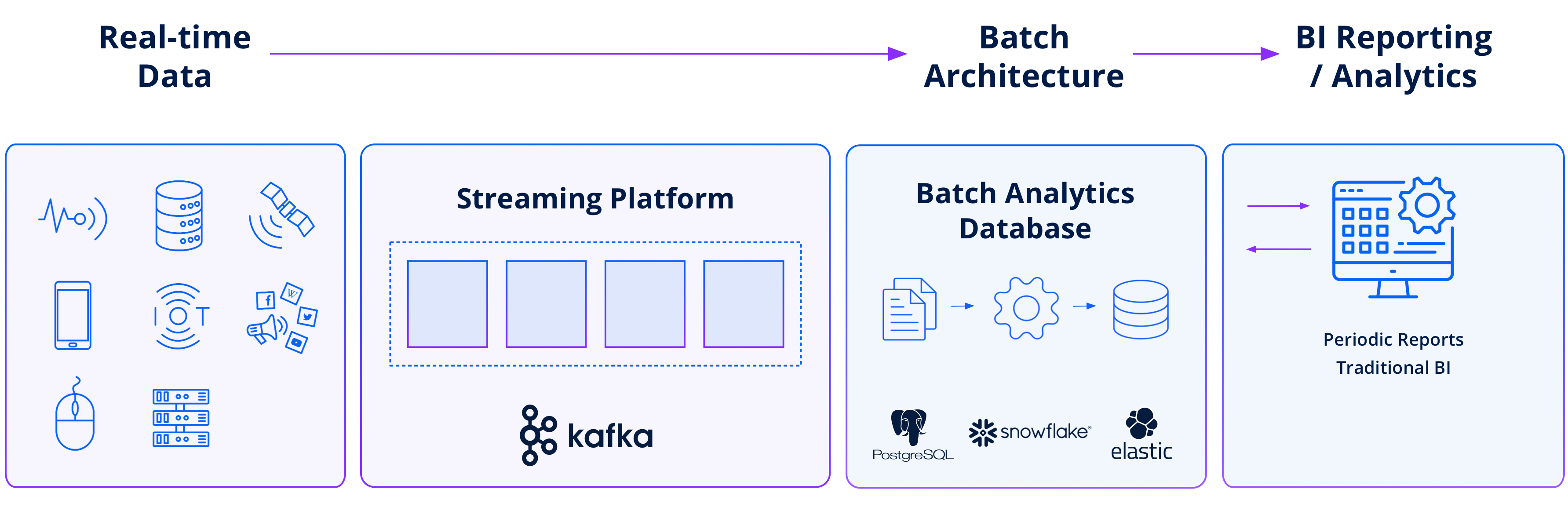
Stream-to-batch architectures are commonly employed in systems that use distributed data processing frameworks, such as Snowflake or ClickHouse, which lack real-time ingestion and require micro-batch processing. This approach can be more straightforward to implement, as it leverages existing batch processing techniques and can manage the complexity of data processing and analysis effectively.
However, stream-to-batch architectures do not provide the lowest possible latency, as there is an inherent delay introduced by batch processing. Additionally, this approach may require more memory and storage resources, as data must be buffered before processing. In essence, while the idea of using a cloud data warehouse or other batch data processing system to serve both batch-oriented and real-time use cases might sound efficient, doing so defeats the purpose of a streaming pipeline.
Stream-to-stream architecture
In a stream-to-stream architecture, each event in incoming streaming data is processed and made available for analysis as it arrives, without dividing it into micro-batches. This approach is also known as event-driven ingestion or true stream ingestion. In this architecture, the data is ingested on-the-fly, allowing for real-time analytics with minimal latency.
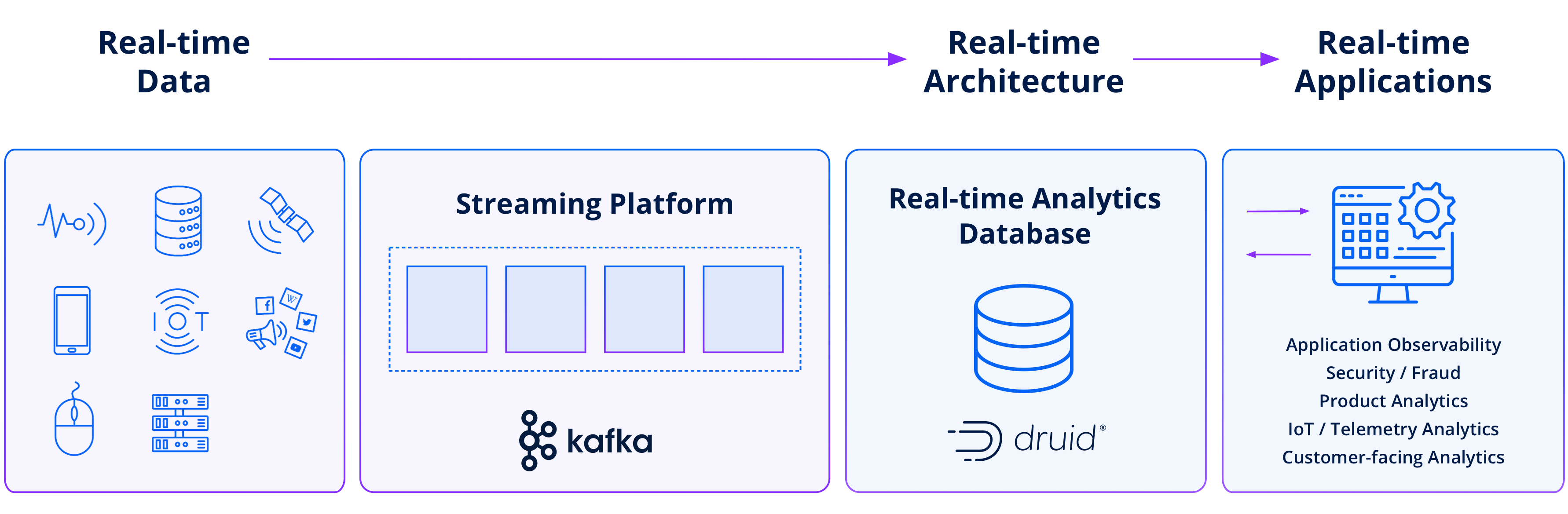
Stream-to-stream architectures are typically employed in systems that require high-throughput, low-latency processing and need to handle millions of events per second and beyond.
Stream-to-stream architectures offer several advantages, such as lower latency and subsecond query response times. However, it’s often useful to combine real-time stream data with historical data—and this is where Druid is differentiated from other data stores in its ability to combine streaming and historical data for real-time analysis. The combination of real-time and historical capabilities in Druid ensures that queries covering any time frame can be quickly resolved. Druid-powered applications can seamlessly retrieve insights that span the complete data timeline, whether it’s the most recent events or past data.
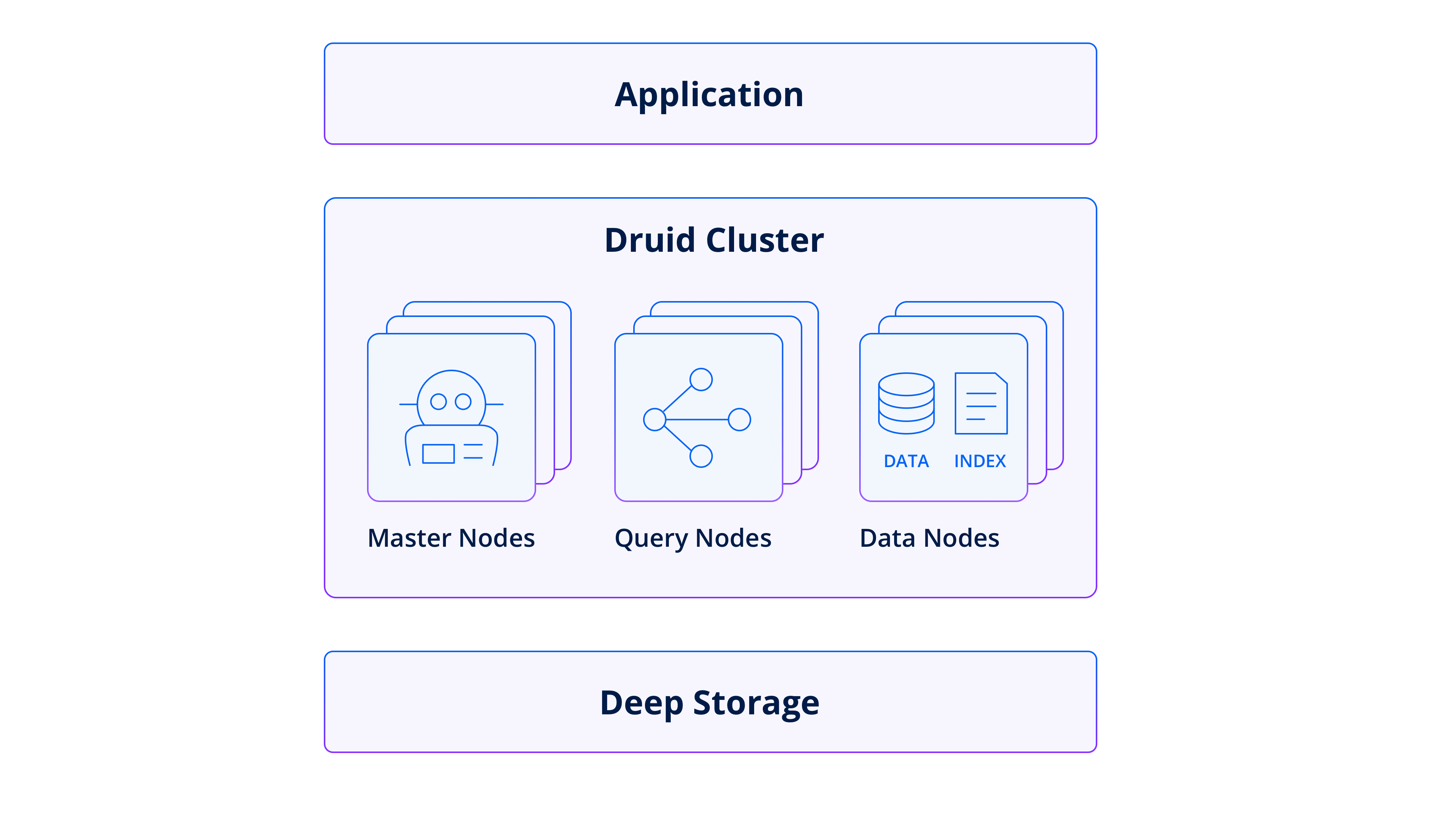
Apache Druid: A real-time analytics database purpose-built for Kafka
Druid enables subsecond performance at scale, provides high concurrency at the best value, and easily ingests and combines real-time streaming data and historical batch data. It is a high-performance, real-time analytics database that is flexible, efficient, and resilient.
In addition to its out-of-the-box integration with Kafka, Druid comes with built-in indexing services that provide event-by-event ingestion. This means streaming data is ingested into memory and made immediately available for use. No waiting for events to be processed through batch processes before they can be queried.
This capability, coupled with exactly-once semantics, guarantees data is always fresh and consistent. If there’s a failure during stream ingestion, Druid will automatically continue to ingest every event exactly once (including events that enter the stream during the outage) to prevent any duplicates or data loss. And with support for schema auto-discovery, developers are assured every row of every Druid table can have the dimensions and metrics that match incoming streaming data, even as the streams evolve.
Perhaps the most powerful reason to use Druid for real-time analytics with Kafka stream is its near-infinite scalability. For even the largest, most complex ingestion jobs, Druid can easily scale into the tens of millions of events per second. With variable ingestion patterns, Druid avoids resource lag (as well as overprovisioning) with dynamic scaling. This means you can add and remove computing power from a Druid cluster without downtime for rebalancing, which is handled automatically.
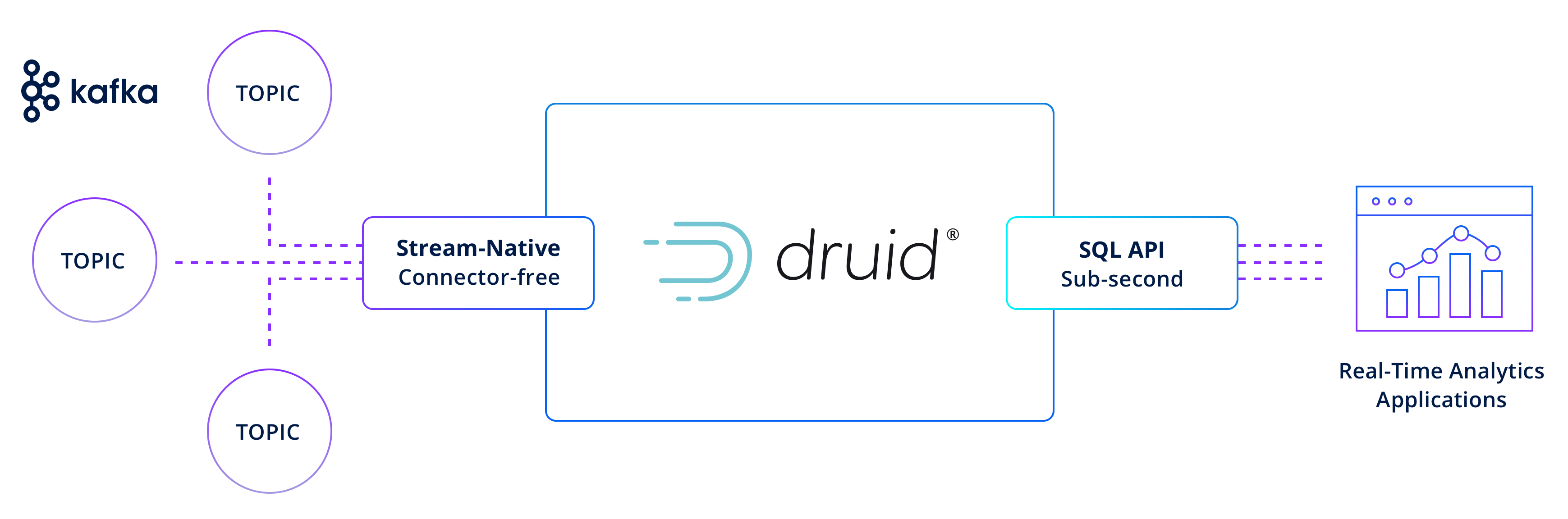
The Apache Kafka to Apache Druid architecture
Druid provides a connector-free integration with Kafka and handles the latency, consistency, and scale requirements for high-performance analytics on large-scale streaming data cost-effectively. Here’s how it works:
At the beginning of the pipeline, event data producers use Kafka’s scalable feature—partitions—to send any number of messages (from zero to millions) per second to each topic.
Druid picks up from there by creating one or more tasks that consume data from one or more Kafka partitions in the topic. This process is carried out automatically by Druid, which distributes all the partitions in a topic across the tasks of a job. Each task is responsible for consuming messages from its assigned Kafka partitions. Events in a topic are immediately available for analysis in Druid and are treated the same as historical data by queries.
As a background process, Druid indexes the newly-arrived data and produces segment files. These files are then published to both query nodes (known in Druid as “historical” processes) and immutable deep storage. Once the data is confirmed into segments, it can be safely removed from its Kafka topic.
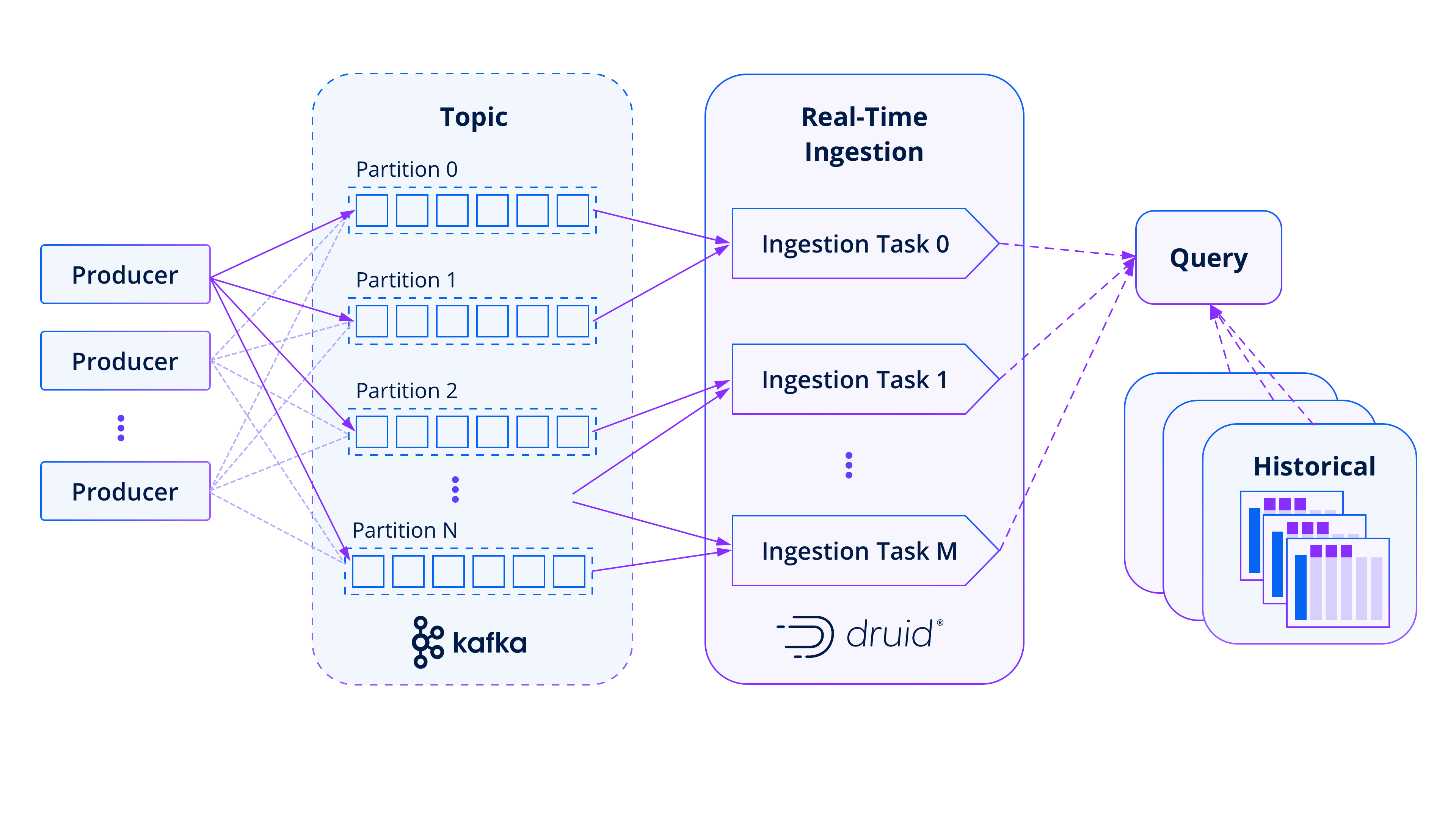
What’s unique about this setup is that when a query is processed by Druid, if the time filter includes the most recent events, Druid will automatically connect with the real-time tasks to handle the part of the query related to the timeframe they have in memory. Simultaneously, the query engine communicates with the Historical processes to deal with the portions of the query that pertain to “past” data (data that has already been ingested).
This dual approach provides a seamless experience for applications that build queries for any specific time frame. Developers no longer need to distinguish between real-time streaming data and past data. Druid takes care of this automatically, providing analytics across any portion of the timeline.
The inherent parallelism of Druid provides scalability both in data ingestion and data queries, producing both high performance for each query and high concurrency across simultaneous queries.
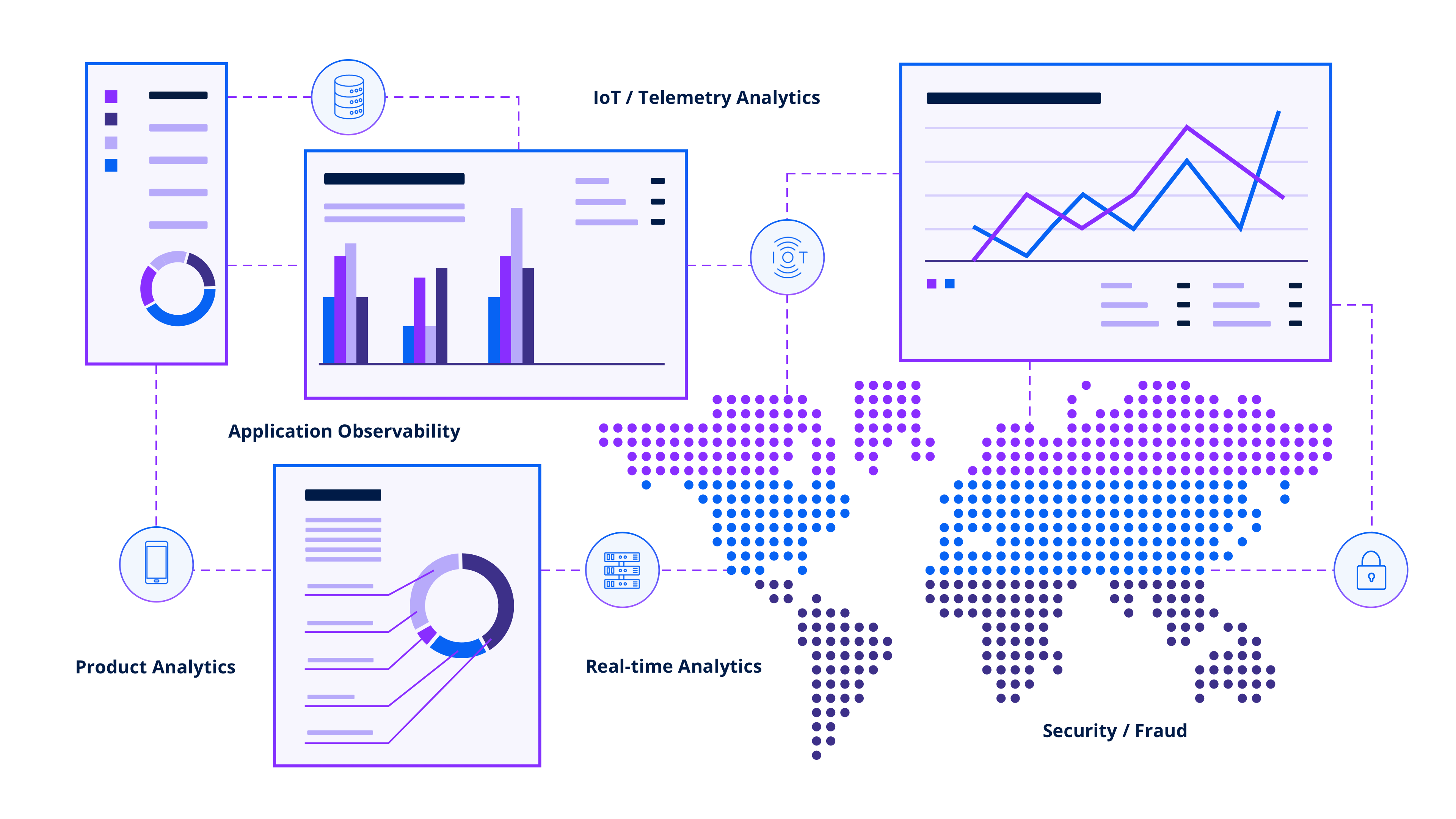
Building real-time analytics applications: Why Druid for Kafka?
Developers choose Kafka because it can move millions of events in a flash. They build with Druid because it natively connects to Kafka, and can query millions to trillions of events per second.
Druid stands out not just for its robust stream-native capabilities but also for its proficiency in ingesting and querying batch data. It features a query engine that’s specifically optimized for subsecond queries at any scale, from GBs to PBs. The fusion of both streaming and batch capabilities within a single database helps simplify application architectures.
Technical benefits of using Druid for Kafka data
Event-based ingestion
Druid is uniquely built for analyzing streams in context. Unlike systems that rely on periodic batch processing, Druid’s event-based ingestion enables data to be ingested and processed as soon as events occur. As a real-time analytics database, it is designed to enable users to query every event as it joins the data stream and do it at a tremendous scale while enabling subsecond queries on a mix of stream and batch data.
This is made possible by Druid’s native connectivity with Kafka, which allows for the ingestion of data on an event-by-event basis without the need for a connector.
Query-on-arrival
As events are ingested into Druid from Kafka, they are held in memory and made immediately available for analytical queries. In the background, the events are indexed and committed to longer-term storage. Druid provides instantaneous access to streaming data, enabling real-time insights and facilitating timely decision-making and rapid response to changing conditions.
The real-time nature of query-on-arrival enables organizations to monitor and analyze streaming data in real time, detecting patterns, anomalies, and trends as they occur. It facilitates applications such as real-time dashboards, alerting systems, and operational analytics, where immediate insights are crucial.
By combining the scalability and low-latency ingestion capabilities of Druid with the continuous data stream from Kafka, query-on-arrival eliminates the need to wait for batch processing or data updates, enabling timely decision-making and rapid response to changing conditions.
High EPS scalability
Druid’s real-time ingestion scales equivalently to Kafka, so you can confidently scale up to millions of events per second (EPS). Similar to Kafka’s scalability using partitions, Druid distributes partitions across tasks to handle high message volumes. The pipeline starts at event data producers, leveraging Kafka’s scalability to push messages to a topic. Druid automatically creates tasks consuming from topic partitions, indexing the data, and publishing segment files to deep storage.
One key aspect to note is how queries in Druid handle real-time and historical data at scale. When a query includes the most recent events, it interacts with real-time tasks, which hold relevant data in memory. Simultaneously, the query engine communicates with historical processes to resolve the parts related to already ingested “past” data. This integrated approach provides a seamless experience for application developers, eliminating concerns about differentiating real-time and historical data. Druid effortlessly resolves the query across the entire timeline, enabling analytics for any timeframe.
The parallelism and integration between real-time ingestion and historical data empower scalability in handling both streaming traffic and application user concurrency, making Druid an efficient and scalable database.
Automatic schema discovery
Druid stands out as the first analytics database to offer the performance of a strongly-typed data structure with the flexibility of a schemaless data structure.
With schema auto-discovery, Druid automatically discerns the fields and types of data ingested, updating tables to align with the evolving data. An added advantage is that as the data schemas undergo changes—additions, removals, or alterations in data types or dimensions—Druid intuitively recognizes these changes and adjusts its tables to correspond to the new schema, eliminating the need to reprocess pre-existing data.
Schema auto-discovery simplifies the process of handling ever-changing event data from Kafka. It provides the performance benefits of a strongly-typed data structure while offering the flexibility and ease of ingestion associated with a schemaless data structure to enhance operational efficiency, reduce administrative burden, and ensure that Druid adapts seamlessly to evolving data schemas.
Guaranteed consistency
Druid enables reliable and accurate data processing through the combination of its Kafka Indexing Service and the inherent features of Kafka. When data in a Kafka topic has been committed to a Druid segment, it is processed as consumed from Kafka, Druid’s indexing service keeps track of the consumed offsets and commits them to Kafka, indicating successful processing.
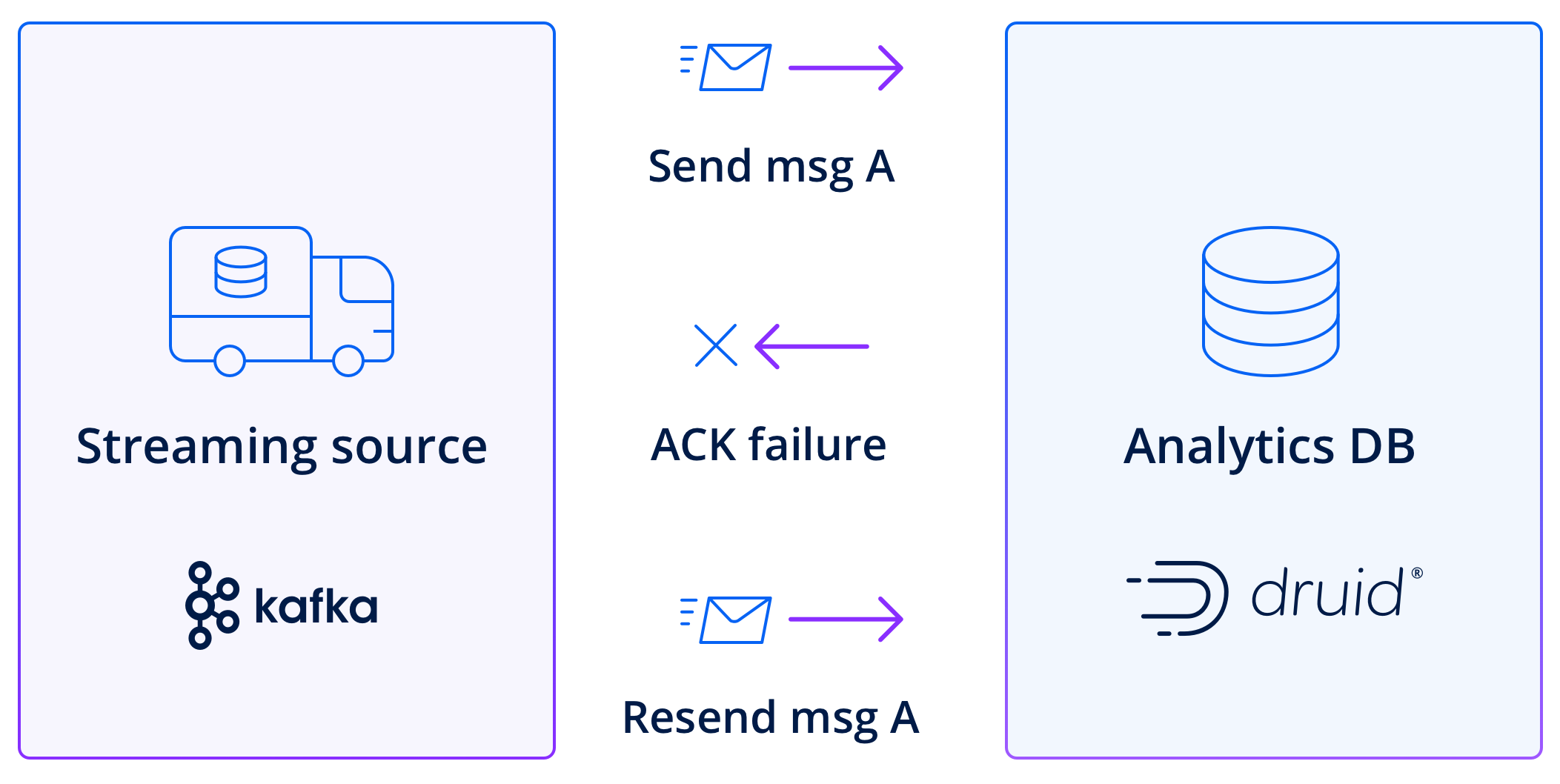
In the event of failures or interruptions during ingestion, Druid’s Kafka indexing service utilizes Kafka’s offset management and commit features to achieve exactly-once semantics. It ensures that data is ingested exactly once, without duplicates or data loss. If a failure occurs, the indexing service can resume ingestion from the last committed offset, ensuring no data is skipped or processed multiple times.
This ensures the reliability and accuracy of the ingested data, which is a key requirement for mission-critical applications.
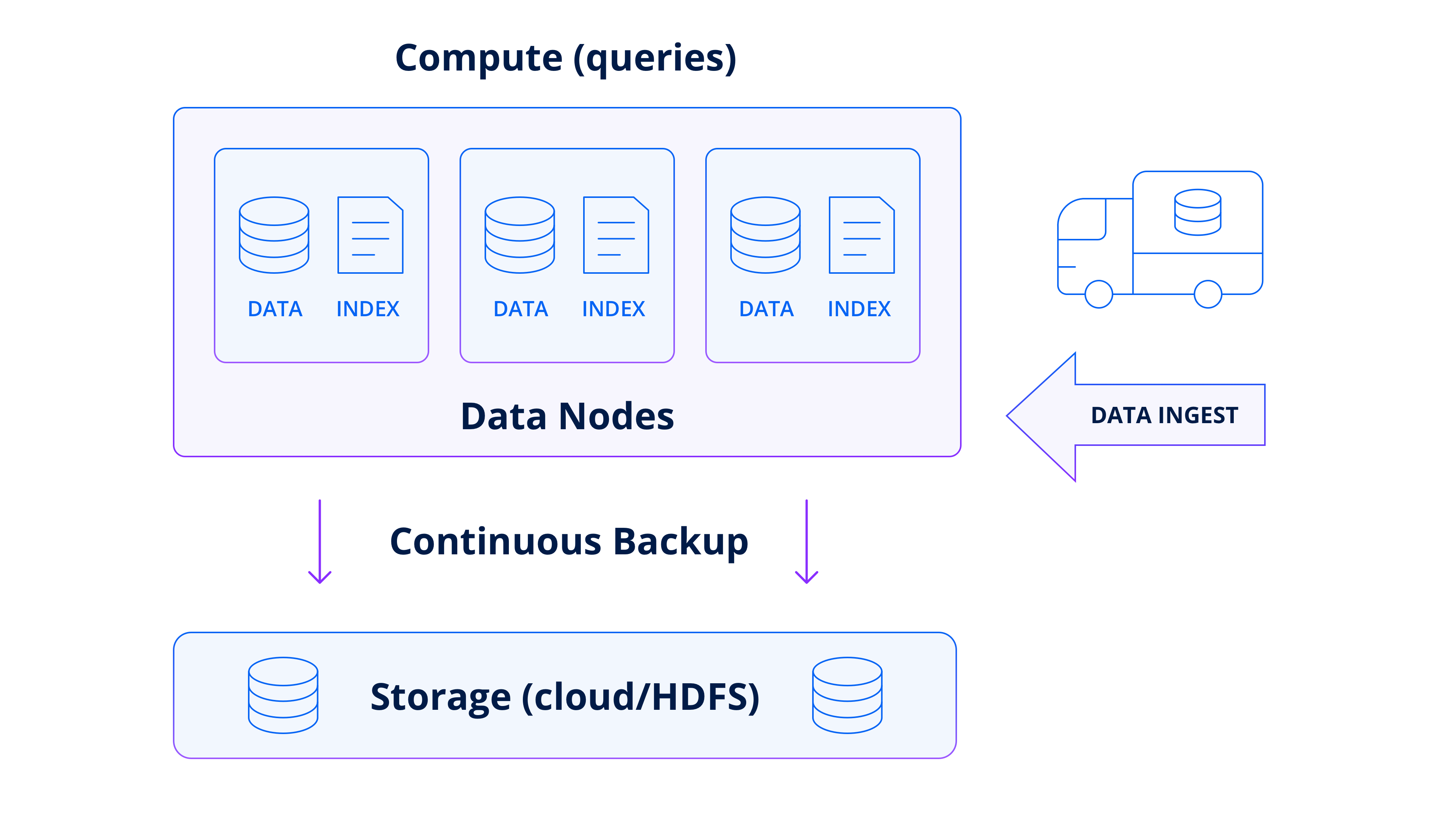
Continuous backup
When ingesting data from Kafka, Druid effectively creates a backup of the data continuously in conjunction with the Kafka indexing service. It continuously persists ingested events into deep storage, such as an object store like Amazon S3, to enable zero data loss in the event of a system failure.
As Druid is persisting new segments incrementally, it is, therefore, unnecessary for an administrator to create backups of the data set, removing a major source of risk and costs that are required to operate most databases.
In case of failures, such as hardware outages or accidental data corruption, Druid enables easy and fast recovery. It’s as simple as watching Druid automatically rehydrate data nodes from deep storage. Because of the built-in Kafka Indexing Service, Druid tracks the Kafka off-set so it can start ingesting events where it left off, ensuring no data loss and a zero recovery point objective.
Getting data from Kafka to Druid
Setting up Druid to ingest data from Kafka is very simple. First, you’ll need to set up ingestion for each Kafka topic you want. By default, Druid will create a table where each event key is a dimension (a column in the table). You can specify how to parse the data, which information to ingest, and, if you prefer, how to rollup the data, such as one row per second or one row per 15 minutes.
Native connectivity
Druid has native connectivity with Kafka, which allows real-time ingestion of streaming data without the need for a Kafka connector. Unlike databases that use a Kafka connector, there is no work or management required to maintain a connector in Druid.
Druid includes the Kafka Indexing Service. This service acts as a Kafka consumer, directly subscribing to Kafka topics and receiving data in real time. It maintains a connection with Kafka brokers, continually fetching messages from the specified Kafka topics.
When data is received from a Kafka topic, the Kafka Indexing Service processes the messages, transforms them into Druid’s internal data format, and indexes them into Druid’s data stores. This means streaming data is made immediately available for querying and analysis. Simply define an ingestion spec with “type”: “kafka” that defines the topic and parameters you want, and Druid handles the rest.
Monitoring data consumption from Kafka
Once you’ve set up Druid to ingest data from Kafka, you generally don’t need to do much to keep it running. This is because Druid employs a Kafka supervisor, which is a type of indexing service that manages the Kafka indexing tasks.
The Kafka supervisor is responsible for managing and monitoring Kafka indexing tasks and ensuring that they are always consuming data. This means the supervisor will create new tasks as needed (in response to failures, scaling needs, task duration/time limits, and such), monitor the state of running tasks, and manage the data replication.
Leading companies running Kafka and Druid in production
Kafka and Druid are commonly deployed together in large, data-intensive companies where real-time analytics are a crucial aspect of product offerings, operations, and customer experiences. Today, many of the world’s industry-leading and digital-native organizations use these technologies to gain real-time insights and deliver cutting-edge products. In total, there are likely well over 1,500 organizations using Kafka and Druid in production (it’s impossible to get an exact count since both technologies are open source). Ultimately, when you decide to leverage Druid to analyze Kafka data, you can build with confidence in the most proven high-performance and scalable real-time event architecture.
Netflix: Global streaming services
Netflix built an observability application powered by Druid, in conjunction with Kafka, that monitors playback quality and ensures a consistent user experience across millions of devices and multiple operating systems. By leveraging the real-time log streams from playback devices, streamed through Kafka and ingested into Druid, Netflix derives actionable metrics to quantify device performance during browsing and playback.
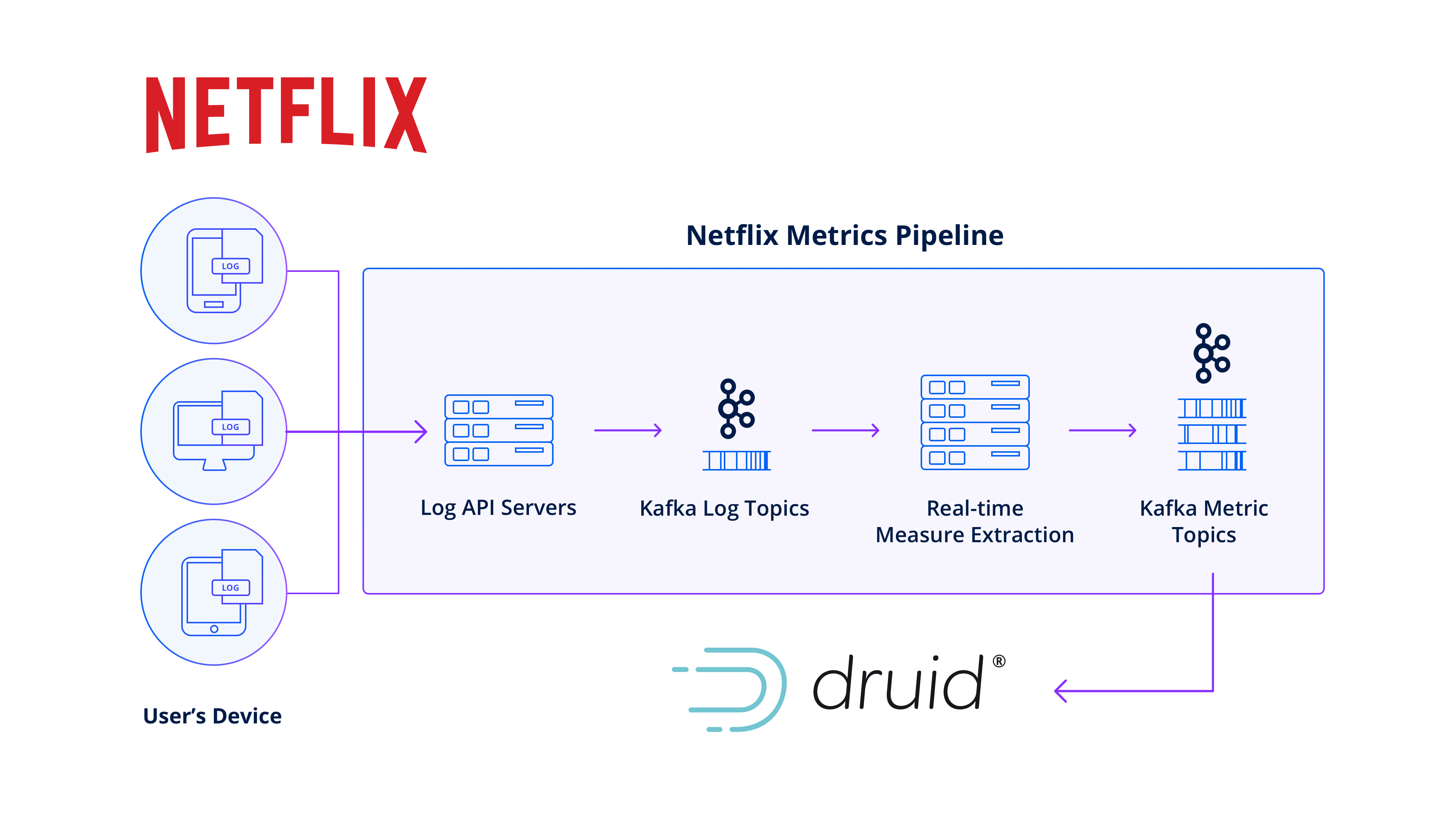
With Druid’s ability to handle high ingestion rates (2 million-plus events per second), high cardinality, and fast queries (subsecond queries across 1.5 trillion rows), Netflix engineers can pinpoint anomalies within their infrastructure, endpoint activity, and content flow. This empowers Netflix to identify and resolve issues that may impact specific customer groups, device types, or regions, ensuring an optimal streaming experience.
By combining Kafka’s reliable and scalable streaming platform with Druid’s real-time analytics capabilities, Netflix continuously improves their streaming service and delivers a seamless user experience to millions of subscribers worldwide.
Salesforce: Cloud-based software for sales, service, and marketing
Salesforce, a global leader in Software-as-a-Service, built a product analytics application powered by Druid to ensure a consistently excellent user experience for over 150,000 customers worldwide. By leveraging Druid with Kafka, Salesforce is able to transform log data into real-time application performance metrics, gaining valuable data-driven insights such as performance analysis, trend analysis, release comparison, issue triage, and troubleshooting. Salesforce chose Druid for its ability to query distributed data sources, deliver ad hoc interactive analytics, and process non-aggregated data at a massive scale.
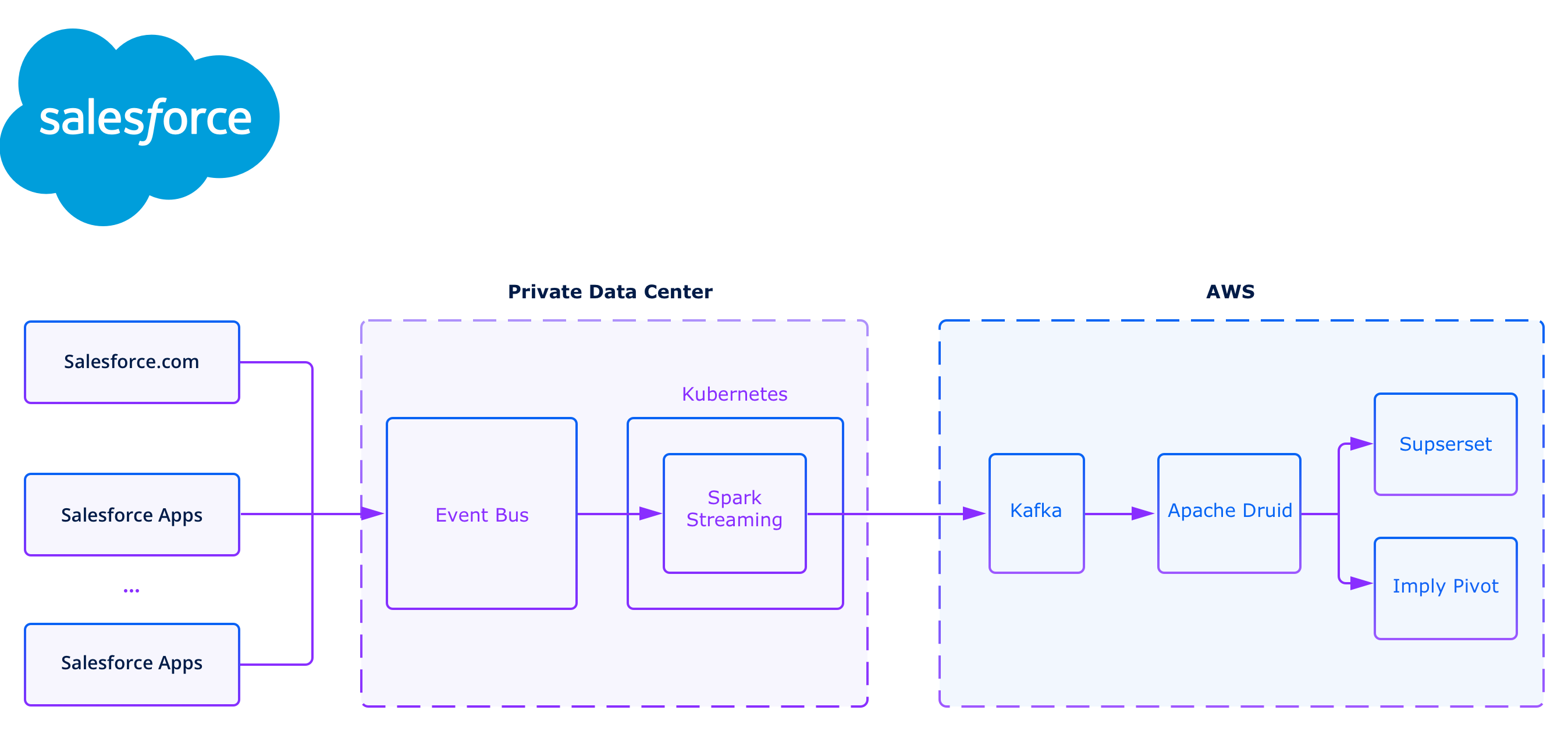
With an extensive ecosystem of production services and the need to monitor their health and performance, Salesforce faces the challenge of managing and understanding the behavior of over 2,700 services. Their data landscape is vast, including petabytes of data in transactional stores, large amounts of log data accumulating each month, and substantial data volumes ingested daily.
Druid was chosen as the real-time analytical database for storing and analyzing application performance metrics extracted from log lines. Druid satisfies Salesforce’s requirements by enabling the ingestion of billions to trillions of log lines per day, providing flexible querying capabilities with various dimensions and filters, and delivering interactive query results in seconds. The diverse teams at Salesforce, including engineers, product owners, and customer service representatives, utilize the application to gain valuable insights for performance analysis, trend analysis, release comparison, issue triage, and troubleshooting.
Druid’s unique features, such as support for complex group-by aggregations, interactive queries with SQL capabilities, and rich analytical dashboards, empower Salesforce teams to access finer, more granular insights across distributed data sources. Salesforce leverages Druid’s compaction and rollup capabilities to optimize storage efficiency and enhance query performance, resulting in significant storage footprint reduction and improved query response times.
By leveraging Druid, Salesforce effectively addresses their analytics requirements, enabling real-time monitoring, analysis, and troubleshooting of their extensive ecosystem of services, ultimately ensuring a superior user experience for their customers.
Confluent: The foundational platform for data-in-motion
Confluent is the data streaming platform founded by the creators of Apache Kafka. Confluent’s data engineering team developed an observability application that ingests more than 5 million events per second and handles hundreds of queries per second. By leveraging Druid as their analytics database, Confluent delivers real-time insights to both internal stakeholders and customers, ensuring an exceptional cloud experience with Confluent Cloud, their fully-managed Kafka service, and Confluent Platform, the enterprise-grade distribution of Apache Kafka.
As a company that manages multiple multi-tenant Kafka clusters across different cloud providers, Confluent needed real-time monitoring and operational visibility for their customer’s critical workloads. Confluent chose to build their observability platform with Druid, where metrics data from Confluent Cloud clusters and customer-managed Confluent Platform clusters are transported to Druid using a Kafka pipeline.
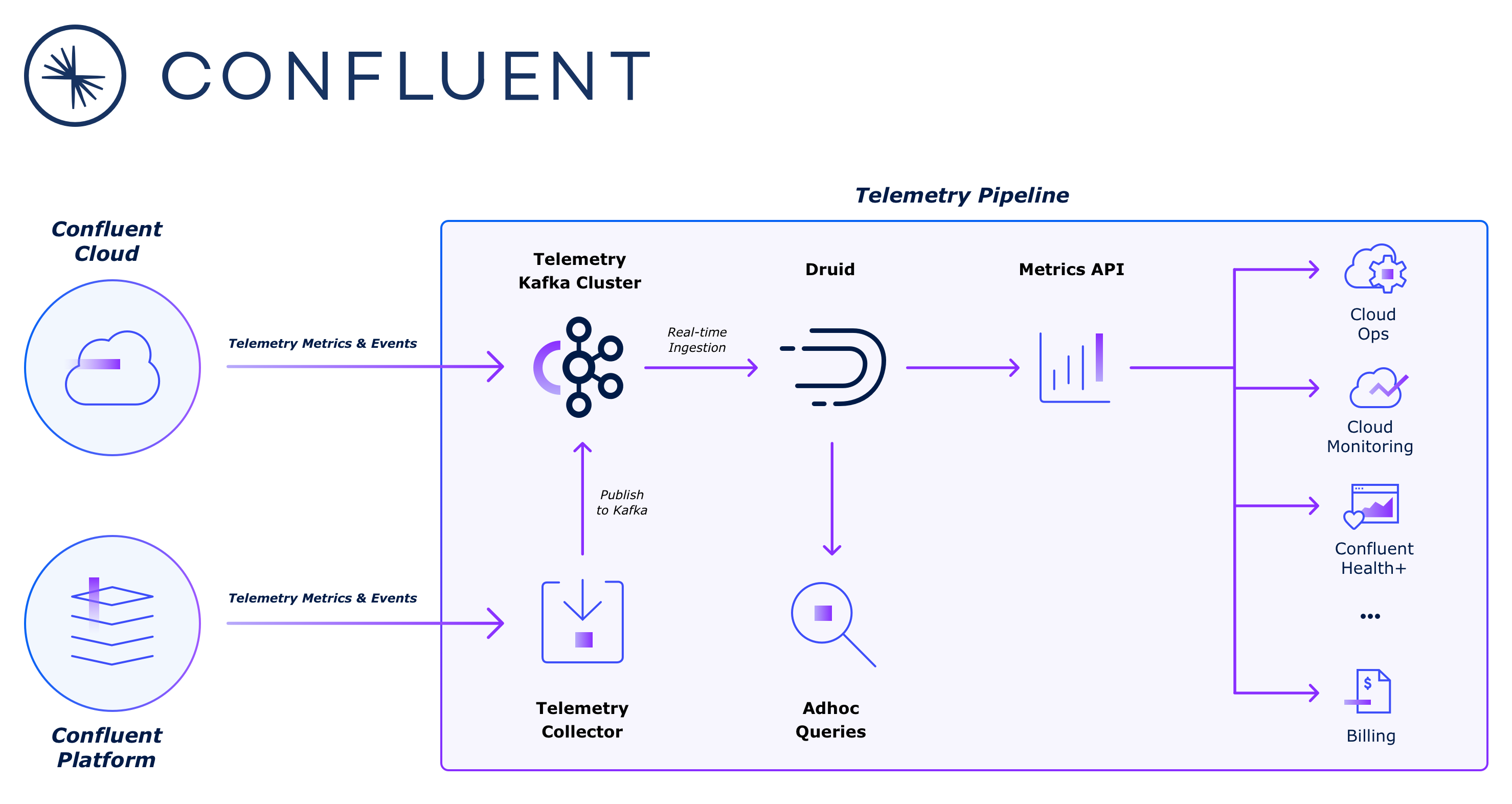
Druid’s real-time ingestion efficiently consumes high-volume data and provides low-latency queries. Engineers at Confluent benefit from ad hoc querying directly to Druid for debugging and optimization, enabling them to fine-tune resource allocation and load balancing while quickly diagnosing the root causes of operational issues. Meanwhile, Confluent customers can use Health+ to monitor their Confluent Cloud and Confluent Platform clusters in real time.
The integration of Druid with Kafka enables Confluent and its customers to achieve powerful real-time analytics and operational visibility, facilitating efficient monitoring and decision-making within their cloud infrastructure.
A complete, secure, and scalable platform for the Kafka-to-Druid architecture
The Kafka-to-Druid architecture unlocks real-time analytics with high throughput, delivering insights with guaranteed consistency and the lowest possible latency. The two open-source technologies are synergistic by design, forming a powerful backbone for your analytics applications.
Deploying open-source software comes with some level of operational complexity and management. If your application is customer-facing or business-critical and requires nonstop availability, strict support SLAs, and enterprise-grade security, open-source community-led updates and troubleshooting may not be enough. If any of these requirements are relevant to you, Imply is here to help.
Confluent Cloud + Imply Polaris: the fastest and easiest way to build real-time analytics on streaming data
Combining Confluent Cloud and Imply Polaris is the fastest and easiest way to construct real-time analytics applications on streaming data.
Confluent Cloud is a resilient, scalable, streaming data service based on Apache Kafka, delivered as a fully managed service. With Imply Polaris, the cloud-native service for Apache Druid, organizations gain the ability to explore, analyze, and visualize large-scale event data in real time. Polaris offers a connector-free integration with Confluent Cloud, simplified management, and powerful visualization tools to derive valuable insights from streaming data.
Together, Confluent Cloud and Imply Polaris provide a comprehensive platform for real-time analytics on streaming data, enabling organizations to build real-time applications with speed and ease.
About Imply
Imply offers the complete developer experience for Apache Druid. Founded by Druid’s original creators, Imply adds to the speed and scale of the database with committer-driven expertise, effortless operations, and flexible deployment to meet developers’ application requirements.
Imply Polaris is a fully-managed cloud Database-as-a-Service that helps you build modern analytics applications faster, cheaper, and with less effort. Polaris enables you to get the full power of open-source Apache Druid and start extracting insights from your data within minutes—without requiring additional infrastructure. You can use the same database from start to scale, with automatic tuning and continuous upgrades that ensure the best performance at every stage of your application’s life—from the first query to your first thousand users and beyond.
To start a free trial of Polaris, visit www.imply.io/polaris.