Machine data architectures are rapidly changing.
As telemetry volumes continue to grow and as costs rise, organizations are increasingly moving logs and other machine data into object stores such as AWS S3. At the same time, modern lakehouse platforms have popularized the separation of storage and compute, allowing teams to retain significantly more data at far lower cost than traditional always-on observability/SIEM infrastructure.
This shift represents the future of how machine data will be stored.
However, popular systems that embrace this architecture for logs suffer from one major limitation: logs must be structured and schemas must be pre-defined (often in a data catalog).
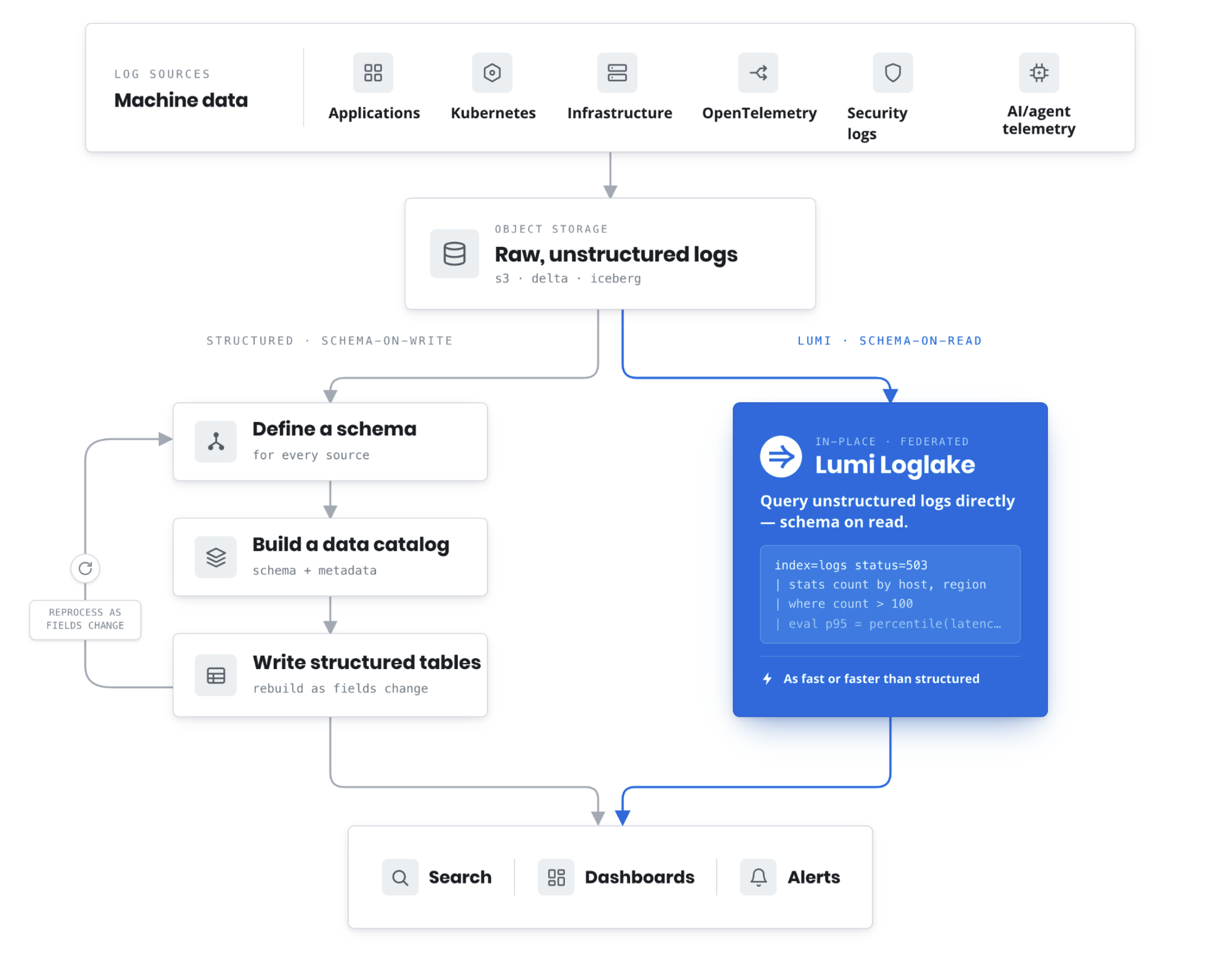
Traditional schema-on-write pipelines require schemas, catalogs, and structured tables before logs can be queried, while Lumi Loglake enables direct search of unstructured logs in object storage using schema-on-read.
Logs are not business data
Logs are messy.
Logs look fundamentally different from business data because they are unstructured.
Different services emit different formats. Fields evolve constantly. New telemetry sources appear continuously. Even within the same application stack, log structures often change over time.
Furthermore, during an investigation, teams usually do not know ahead of time what information will matter.
An investigation might begin with something as simple as:
- A suspicious IP address
- An error code
- An unexpected API request
- A hostname
- A user ID
From there, teams need to rapidly search across massive telemetry datasets to reconstruct context and understand what actually happened.
That is a fundamentally different workflow from running predefined analytics against structured datasets like sales transactions, customer records, or financial reporting data. Operational investigations are exploratory by nature and the questions are often unknown until the investigation has already started.
Why schema-on-write approaches create friction for SIEM/observability
Imagine a security team identifies a suspicious IP address during an active incident.
The first question is simple: “Where else does this IP appear?”
At that moment, teams are not running predefined analytics against clean structured datasets.
They are trying to rapidly search across massive volumes of raw operational logs to reconstruct context in real time.
This is where many lakehouse and machine data lake architectures struggle.
At a high level, these systems are designed around a relatively simple assumption: you generally know what questions you want to ask before you start querying the data.
Structuring data makes sense for analytics use cases. Organizations generally know what datasets matter, what fields are important, and how the data will be queried over time. Teams can define schemas upfront, optimize storage layouts, partition datasets, and accelerate repeatable queries.
Operational logs however, rarely behave this way. As a result, teams often end up repeatedly reconstructing rows from raw logs, restructuring datasets, rebuilding schemas, and reprocessing telemetry pipelines before investigations can continue.
The overhead may be manageable for traditional analytics workloads where queries are relatively predictable. But during an incident, delays matter. Teams need to quickly search and explore unpredictable telemetry without constantly redesigning schemas or rebuilding pipelines every time data changes.
Lumi: query first, optimize later
Federated query systems and machine data lake architectures represent an important step forward for observability. They allow organizations to retain significantly larger volumes of telemetry in object storage while querying data stored in object storage. But many of these systems still fundamentally assume logs have already been transformed into structured, queryable datasets before investigations begin.
Lumi is designed around a different assumption: operational investigations should not require logs to be fully structured before teams can begin searching them. Performance on unstructured logs should match what they are for structured data, without needing to define the explicit fields in the data before the logs can be queried.
Instead of forcing teams to define schemas upfront, Lumi and our new Loglake feature allow organizations to query unstructured logs directly where they already live in object storage, with performance exceeding systems that require structured data.
That means teams can search first, reconstruct context dynamically, and optimize later if needed.
Without requiring:
- Predefined schemas
- Rehydration workflows
- Duplicate indexing pipelines
- Repeated data reconstruction before investigations can begin
With Loglake, teams can point Lumi at unstructured logs in object storage and immediately begin searching them interactively.
The future of observability/SIEM
The industry is clearly moving towards separating storage and compute for machine data. That transition is both necessary and inevitable. But the future is not simply about where logs are stored. It is about how quickly teams can search, explore, and understand large volumes of machine data directly from open storage environments without introducing unnecessary preprocessing, reconstruction delays, or operational complexity.
The next challenge is making that data instantly searchable for operational and security investigations without requiring heavy preprocessing or predefined schemas.
That is the problem Lumi and Loglake solve.