The Apache Druid community released Druid 0.18 on April 20th, 2020. This release contains over 200 new features, performance enhancements, bug fixes, and major documentation improvements from 42 contributors.
As always, you can visit the Apache Druid download page to download the software and read the full release notes detailing every change. This Druid release is also available as part of the Imply distribution, which includes Imply Pivot as well.
Support wider business intelligence use cases
On the path towards being a comprehensive analytics engine, Druid has picked up a few new capabilities in 0.18, including improved subqueries, JOINs, and GROUPING SETS
Improved subqueries
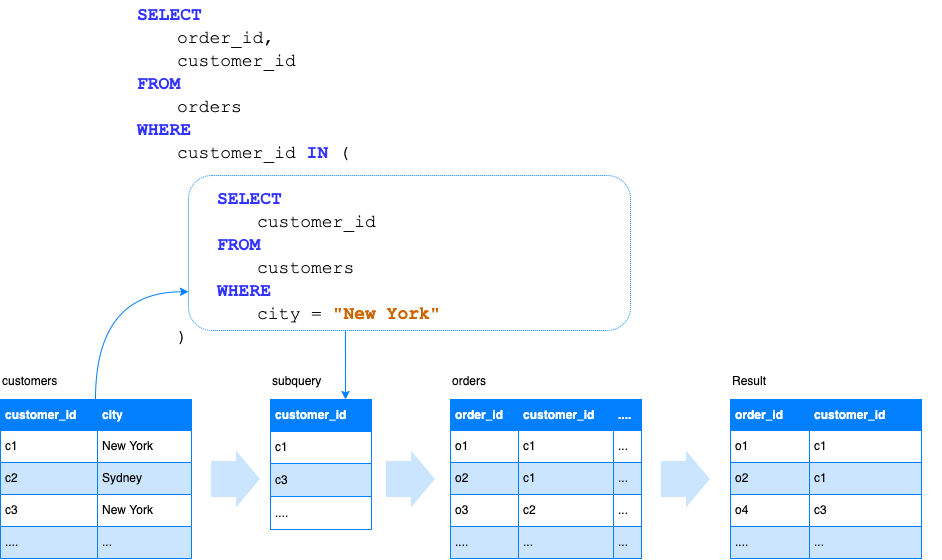
Queries that have multiple stages of calculations are easier to express with subqueries. Druid engine has improved support for subqueries in 0.18. You can find more details about subquery support in Druid documentation.
Subqueries look like this:
Note that all subqueries in a single query share the same limit of 100,000 rows by default. This is because the intermediate table lives in the broker memory. The memory on the broker is a shared, limited resource. Thus you should avoid creating subqueries that output large result sets.
JOIN
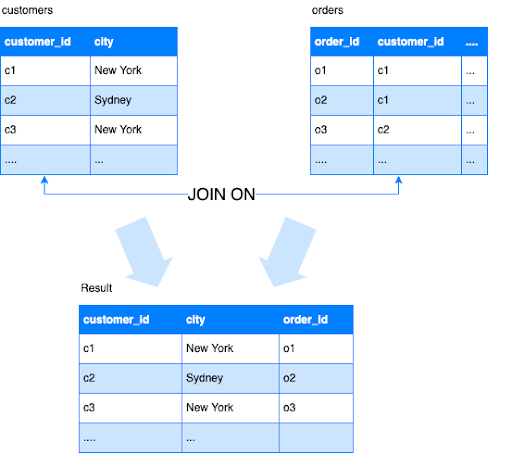
In relational databases, normalized schemas are commonplace. This means that analytical engines must be able to merge data across tables. SQL JOINs provides this capability.
Prior to 0.18.0, Druid supported some JOIN features, such as Lookups or semi-joins in SQL. Druid 0.18.0 supports real joins for the first time ever in its history including support for INNER, LEFT, and CROSS joins.
With JOIN and subqueries, you can now express many common queries used in business intelligence use cases.
In 0.18, JOIN support is limited to lookups, inline queries and subquery data sources. We are planning on adding support for more data sources in the future. Let us know what you want to see in the community.
GROUPING SETS
Queries that have multiple stages of calculations are easier to express with subqueries. Druid engine has improved support for subqueries in 0.18. You can find more details about subquery support in Druid documentation.
In 0.18, Druid has also introduced GROUPING SETS. For example, GROUP BY GROUPING SETS ( (country, city), (country), () ) will create a resultset that contains 3 sets of data, an aggregation (e.g., sum) breaking down at country-city level, then country-level, where the city is null, and followed by a grand total.
This is especially useful when you are doing multiple layers of roll up in reporting, from region, to city, to state level, for example. This is very efficient as the data only needs to be scanned once.
In multi-tenant environments with heterogeneous workloads, resource contention can lead to short-running queries having to wait in a queue for a long time. In Druid 0.18, we’ve introduced query laning and dynamic prioritization, giving you more control over how resources in a cluster are allocated. See more details here.
With laning, the broker examines and classifies a query and assigns it a lane. You also have the option to manually assign a lane. You can specify the maximum amount of resources a lane can use, ensuring some capacity is left to handle other workloads, such as short-running queries.
Automatic query prioritization determines the query priority based on how expensive a query is. It takes account of how much data is scanned, how far back in history the query is trying to read from, and a few other factors to estimate the cost of a query.
This is another step towards smarter resource allocation and it gives cluster administrators another tool in their toolbox.
SQL dynamic parameters
Druid now supports dynamic parameters for SQL. This can be used to enhance security. Because it will correctly escape parameter strings to avoid SQL injections. It also reduces the need to pass large blobs of data into the query planner. Because data blobs don’t need to be parsed by the planner during planning time, it’ll improve the query planning performance and reduce the memory requirement for query planning.
Roaring bitmaps as default
Druid supports two bitmap types, Roaring and CONCISE. Since Roaring bitmaps provide a better out-of-box experience (faster query speed in general), the default bitmap type has been switched to Roaring bitmaps.
Other items
For a full list of all new functionality in Druid 0.18.0, head over to the Apache Druid download page and check out the release notes!
Other blogs you might find interesting
No records found...
May 07, 2025
Real-Time Observability Without Operational Overhead: What’s Next?
Observability is meant to provide clarity, speed, and confidence in modern systems. Yet for many organizations, it has become a source of complexity, cost, and operational drag. Managing pipelines, tuning...
It’s Time to Rethink Observability: The Event-Driven Future
Observability has evolved. Forward-looking teams are already moving beyond static dashboards and fragmented telemetry—treating all observability data as events and unlocking real-time insights across their...
5 Reasons to Use Imply Polaris over Apache Druid for Real-Time Analytics
Introduction Real-time analytics is a game-changer for businesses that need to make fast, data-driven decisions. Whether you’re analyzing user activity, monitoring applications and infrastructure, detecting...