In our 2024 Product Innovation Recap, we reflected on our progress in growing the Apache Druid® project and making additional enhancements to Imply Polaris, our fully managed DBaaS that makes it easier to use Druid and build awesome data applications on top of it.
Read the 2024 Innovation Recap
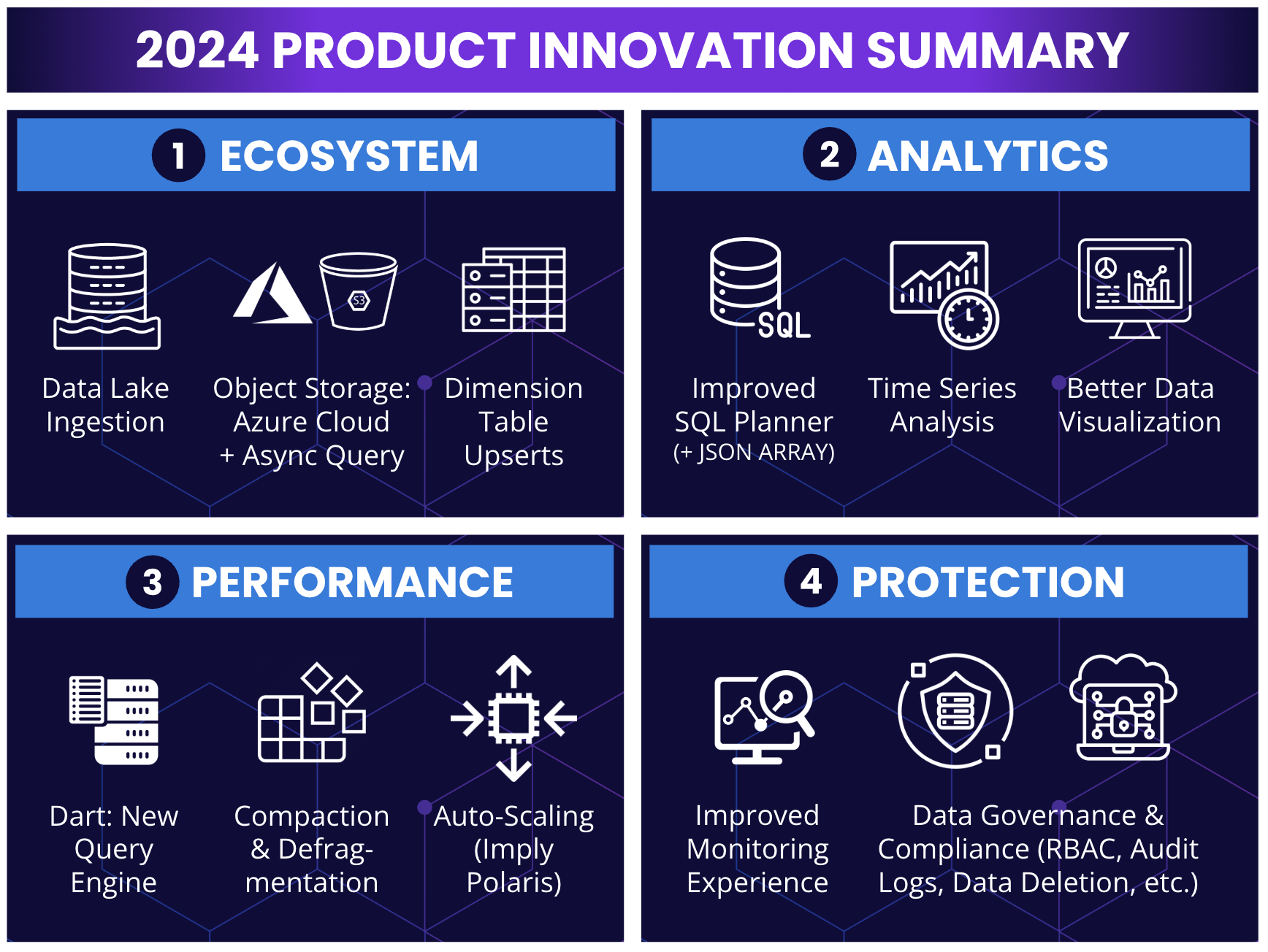
We encourage you to start with the innovation recap above before reading further, but to briefly summarize our strategy ー we released over 1,500 updates to Druid and Imply last year, focused on four key pillars that we’ll continue to build upon in 2025:
- ECOSYSTEM: Power Partner Connections & Seamless Data Ingestion ー Expanding ecosystem accessibility is not just about adding more partners and data types, but also about making it so the data can be ingested and queried efficiently.
- ANALYTICS: Simplify Complex Queries with SQL Completeness ー We build ANSI SQL compatibility into any and all analytics powered by our query engine, simplifying the steps to do complex analysis.
- PERFORMANCE: Push Scale & Operational Efficiency Boundaries ー Druid is optimized for extremely large clusters, so we are constantly improving operational efficiency through storage compaction, query engine improvements, and more.
- PROTECTION: Enhance Resiliency, Security & Governance ー While Druid was built with security by design, Imply Polaris takes this to a whole new level with more elasticity, resilience, a monitoring UI, and major enhancements to data governance.
From here, we’ll dive deep into these four strategic pillars to define the purpose and value of the top 2024 product updates shown in the image below, plus a few extra updates that you may be keen to explore further.
(1) ECOSYSTEM:
Power Partner Connections & Seamless Data Ingestion
Building upon the vision of positioning Druid as an event database, our goal was to expand partner connections while building simple tools for data ingestion to reduce friction.
Looking back at our momentum from 2023, we built upon our schema auto-discovery capabilities by adding support for nested columns and native arrays in Druid, allowing you to ingest any data shape without having to worry about the schema or complexity inside those data files. We also added SQL-ingestion support for existing tooling that generates DML-based statements for batch ingestion. Lastly, we introduced Kubernetes (K8s) native task scheduling to utilize K8s for launching and managing ingestion tasks, providing ingestion auto-scaling support for substantial compute saving during low traffic periods.
In 2024, we added support for data lakes, expanded the ways we work with object storage via Azure marketplace and async query, and introduced Dimension Tables for Imply Polaris to instantly upsert new or changed data upon ingestion.
Ingest from Deltalake and Iceberg
We introduced support for ingesting and querying data from Apache Iceberg and Deltalake, making it easier to integrate Druid across your full data stack. We further improved the ingestion system by adding the ability to filter data based on folder names (such as parquet partitions and columns), which reduces the amount of data to process during ingestion.
Azure Cloud Marketplace (Imply Polaris)
Imply Polaris is now available in the Azure cloud marketplace, completing a crucial part of our commitment to providing flexibility and support for multi- and hybrid-cloud strategies.
“With Polaris on Microsoft Azure, customers worldwide can more easily build premium-experience real-time analytics applications on Microsoft Azure,” said Alistair Spears, Senior Director, Product Marketing, Microsoft. “We are pleased to welcome Imply Polaris to the growing Azure ecosystem.” Check out the blog announcement to learn more.
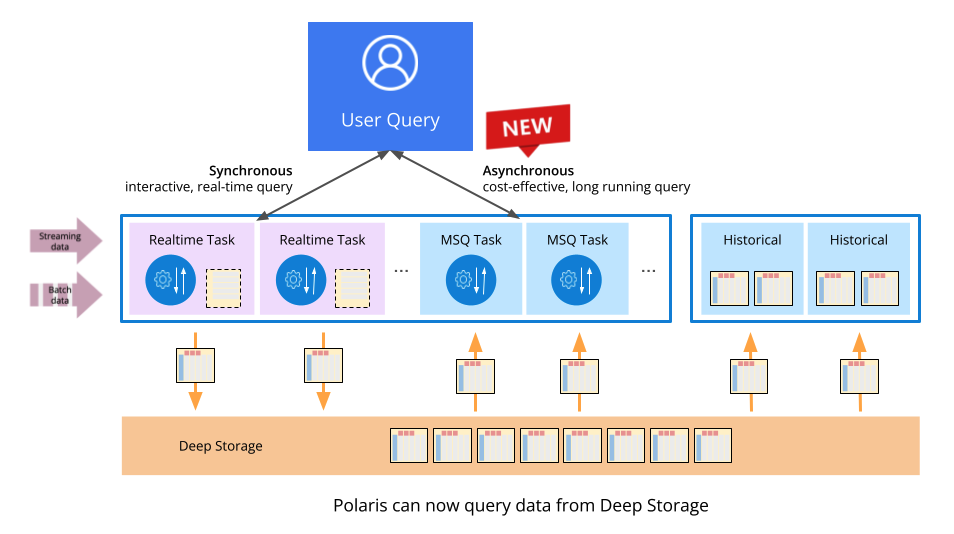
Asynchronous Query
Asynchronous query unlocks the ability to cheaply query old data from object storage services like Amazon S3 for side-by-side analysis against real-time data. While also available in Apache Druid, leveraging async query in Imply Polaris provides fast, interactive queries and cost-effective options for aged data, all from a single, efficient platform.
Dimension Table Upserts (Imply Polaris)
Exclusive to Imply Polaris, Dimension Tables allow you to instantly upsert data when ingesting from Kafka for new or changed streaming data. Dimension Tables provide one table that contains all the data that needs to be JOINed on at query time, facilitating fast, accurate, storage-optimized updates without needing to reprocess entire datasets.
Dimension Tables provide a more efficient and scalable solution compared to traditional Kafka-based lookup tables. Metaimpact explains step-by-step how they made the switch here, improving memory efficiency by at least 2x.
Other Ecosystem Updates
In addition to the above, we released system fields ingestion and multi-stage query (MSQ) support for Azure, GCP, and CSV export in Druid 29; a better ingestion experience, improved Kafka and Kinesis streaming ingestion, Rabbit MQ Superstream (experimental), GCS export support with MSQ, and Azure multi-storage account ingestion in Druid 30; improved operations for K8s ingestion in Druid 31; and enhanced IPv6 support in Imply.
(2) ANALYTICS:
Simplify Complex Queries with SQL Completeness
We’re always looking for new ways to improve analytics workflows, from simplifying the steps for complex analysis to optimizing the efficiency of data storage. In doing so, SQL compatibility is crucial to ensure ease of use across the developer community.
SQL Planner Improvements
First and foremost, we improved our SQL planner engine to handle more complex filters, subqueries and joins. This entailed multiple updates across Druid 29, 30, and 31, including:
- Window function enhancements: Enhanced window functions allow for advanced analytical queries, such as running totals, moving averages, and sparkline visualizations, directly within Druid. We made various improvements in Druid 29-31, including MSQ support for a wide variety of SQL window function query shapes.
- Large subquery joins: Support for Unequal Joins enables more complex data transformations in Druid (no external processing required).
- SQL compatible NULL handling: This includes stricter handling of NULL values and boolean logic, adopting SQL’s three-valued logic (true, false, unknown).
- GROUP BY and ORDER BY on complex columns: This enables more sophisticated aggregations and sorting on nested data structures, improving query flexibility.
- Speedier IN and AND filters: We made the IN filter type aware to optimize the execution by making assumptions about the underlying data type and reducing work on each row processed. We also added new logic to AND filters to check the selectivity of indexes as it processes each clause of the AND filter.
JSON_QUERY_ARRAY (supporting UNNEST)
In Druid 29, we added JSON_QUERY_ARRAY, which is similar to JSON_QUERY except the return type is always an array. This allows you to apply UNNEST with JSON objects, extending our SQL planner to provide a composite that flattens the arrays of objects. In Druid 30, we added ARRAY support for doubles and null values for dynamic queries.
This enhances Druid’s ability to handle complex, nested data structures, enabling enhanced data modeling (by flattening arrays into individual rows), improved query flexibility (e.g. GROUP BY, ORDER BY, and filtering on unnested elements), and performance optimization (by performing unnesting locally within each segment, reducing computational overhead).
Time Series Analysis (Imply Polaris)
Time series analysis is a game changer for Imply Polaris, overcoming the hurdles of storage optimization and operational complexity involved in the analysis of time series data. With Polaris, you can easily slice and splice your data with simplified queries and built-in visualization to derive valuable insights.
Although Apache Druid offers some basic time series queries, the updates to Polaris make the process significantly easier, with a 35% smaller column footprint and 25% faster speed than open-source implementations. In addition to the powerful visualizations in Polaris, time series algebra like TIME_WEIGHTED_AVERAGE and SUBTRACT_TIMESERIES offer streamlined function processing (reducing the need for subqueries), while interpolation allows you to easily smooth and fill data gaps.
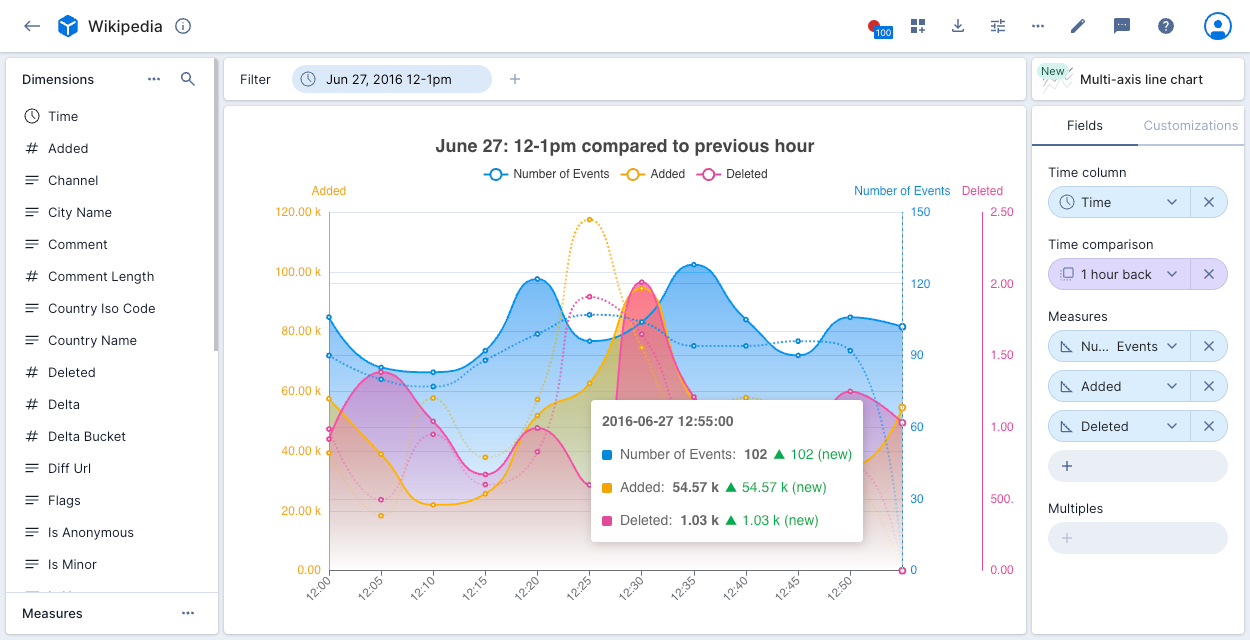
Better Data Visualization (Imply Pivot)
Imply Pivot is a simple, “no-code” engine designed to help you visualize and embed data directly into applications. Designed for self-service analytics, it puts insights directly at your fingertips—without the complexity of building visualizations from scratch.
We made numerous Pivot enhancements in 2024. We improved visualization options, including a new bar chart, multi-axis line chart, time series analysis, and more embedding visualization types. We also made it easier to edit data under the hood, including timezone controls, datacube access filters for API keys, and records table (explore) visualization.
Other Analytics Updates
In addition to the above, we released SQL PIVOT / UNPIVOT and EARLIEST / LATEST support for numerical columns in Druid 29; TABLE(APPEND) syntax for UNION operations in Druid 30; and Explore view to enable wider access to users without SQL knowledge in Druid 31.
(3) PERFORMANCE:
Push Scale & Operational Efficiency Boundaries
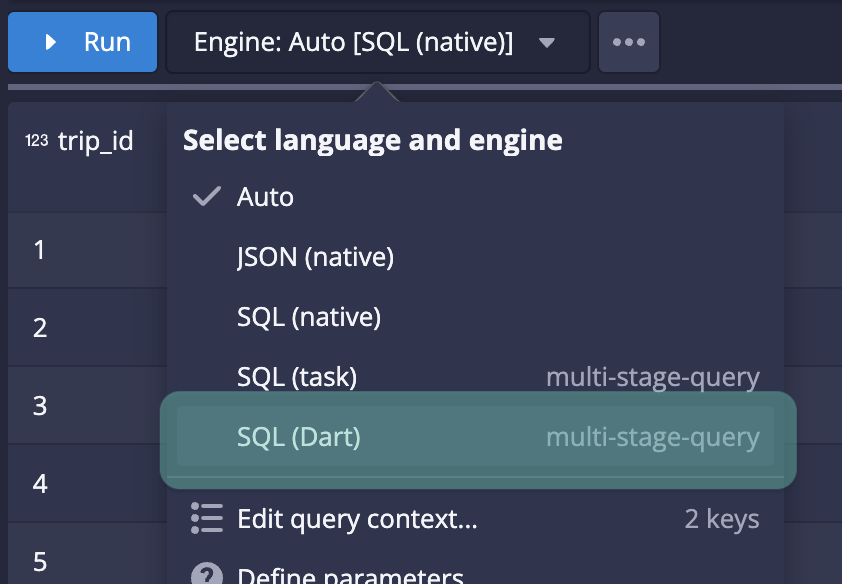
In 2024, we pushed scale and operational efficiency boundaries to new limits. As an extension of the analytical efficiency improvements above, we also made significant enhancements to the underlying query engine to improve storage efficiency and query speed. We introduced a new query engine called Dart, made significant compaction enhancements, and continued to finetune Imply Polaris’ auto-scaling capabilities.
Dart (Brand New Engine)
In addition to the established Druid interactive query profile and the MSQ profile from Druid 24, Druid 31 adds a new experimental profile – Dart. Dart is a high-parallelism engine that supports a wider range of workloads, reducing the need for additional infrastructure. Initial tests show up to 2000% performance improvement for demanding queries when compared against the current Druid SQL query engine.
Dart is designed to support high-complexity queries, such as large joins, high-cardinality GROUP BY, large sub-queries and CTEs. These are the query types commonly found in ad-hoc analysis in data warehouses, and they will be familiar to developers using Apache Spark, BigQuery, Snowflake, and Presto (Trino).
The Dart profile is powered by a new query engine that is fully compatible with current Druid query shapes and the Druid storage format. The Dart query engine is a revolution in query engine design: it uses multi-threaded workers and conducts in-memory shuffles.
Defragmentation & Compaction Improvements
Continuous defragmentation is an automated process that reorganizes and compacts data segments to optimize storage efficiency and query performance. As data is ingested, updated, or deleted over time, data fragmentation will result in substantially slower queries. By automatically merging small or underutilized segments into larger, more efficient ones, Druid improves query performance, operational simplicity, and cost efficiency. We made the following improvements in Druid 31:
- Concurrent append and replace: Now out of experimental mode, this feature allows streaming data to be compacted even when late arrival data is causing fragmentation, improving throughput and minimizing compaction bottlenecks. This feature is designed to ensure data consistency with automatic recovery and check-pointing such that during scaling or failures, the compaction and streaming system can continue to work in unison.
- Supervisor-based compaction scheduling: This is an experimental feature that allows compaction tasks to be scheduled just like a regular supervisor-managed task, such as a streaming ingestion task. Historically, compaction tasks have been scheduled separately from all other task types. This poses challenges when users try to balance resources between ingestion tasks and compaction tasks. It also poses challenges around scheduling, failure retry, and prioritization on which intervals to compact. The supervisor-based compaction scheduler resolves those issues and allows the cluster to reduce fragmentation rapidly.
- MSQ based auto-compaction: Compared to the previous compaction system, MSQ-based auto-compaction is faster, more memory efficient, and less prone to failures when processing large amounts of data. Once you turn on supervisor-based compaction scheduling, you can turn on MSQ-based auto-compaction at a cluster level by setting ‘druid.supervisor.compaction.engine’ to ‘msq’ in Overlord’s runtime config, or set ‘spec.engine’ to ‘msq’ at a compaction supervisor task level if you want to enable this per data source.
Auto-Scaling (Imply Polaris)
Lastly, Imply Polaris provides enhanced auto-scaling for higher performance and cost efficiency. While Druid and Imply Enterprise Hybrid require users to constantly manage and fine-tune the compute and storage required for their Druid clusters, Polaris does all of this automatically to reduce operational overhead.
Imply Polaris dynamically adjusts streaming / batch ingestion resources based on actual event flow, automatically managing the sizing, scaling, and upgrading of resources across clusters for optimal performance without manual intervention. As we continuously finetune this process behind the scenes, Polaris operates more efficiently in production at scale. Enterprise Polaris customers can avoid overprovisioning, without having to worry about peaks for seasonality and high traffic days, resulting in significant cost savings.
(4) PROTECTION:
Enhance Resiliency, Security & Governance
In addition to the aforementioned Polaris-exclusive features (Azure Marketplace, Dimension Tables, time series analysis, enhanced auto-scaling), we placed a concerted effort on maximizing the resiliency, security, and data governance of Imply Polaris while minimizing manual legwork.
Improved Monitoring Experience
In 2024, we improved the streaming ingestion dashboard for easier visualization, zoom-out and zoom-in, as shown below. We also added usage analytics, additional query cache metrics, and more detailed metrics for streaming data (e.g. failed tasks, successful tasks, events processed %, events unparseable %, processed with error %, etc.).

Access Control (RBAC)
Polaris now provides full RBAC with security at the row, column, and user level for multitenant use cases. You can use the Imply View Manager (utilizing SQL Views) to control the data available to different users and user groups within your organization, ensuring that individuals can only access the resources necessary for their job responsibilities.
Audit Logs
Going beyond routine tracking, Audit Logs play an important role in enhancing security, compliance, and oversight within your organization. By capturing essential user management and authentication events, Audit Logs can help detect anomalous activities, investigate privilege misuse, and efficiently address security incidents.
Restore or Permanently Delete Data
The ability to restore or permanently delete data after it expires adds safeguards for minimizing data loss, while improving control over the cost of data usage.
After you soft delete data in Imply Polaris or data expires based on your retention period, you have a 30-day grace period that gives you the option to: do nothing (allow permanent deletion after 30 days), proactively delete the data (to reduce data usage and stay within your project size earlier in the grace period), or restore the data (within the grace period).
You can also manage specific versions of soft deleted data. For example, if you replaced data multiple times last month, you may want to restore an older version of the data rather than the most recently deleted one.
Other Protection Updates
To further improve data governance in Imply Polaris, we also added an IP allowlist to control API key access to a project, a precache policy to control data that is precached or only in deep storage, and pause and stop protection to prevent accidental pausing and stopping of a project.
Conclusion: Looking Back and Ahead
Throughout 2024, we extended our commitment to provide better experiences for Imply and Druid users alike by supporting additional data types, making it easier and more cost effective to conduct complex analysis, improving performance for operational efficiency at scale, and enhancing data protection for better security, resilience, and governance.
As we continue to innovate in 2025, we’ll be exploring new projects like a virtual storage layer to unify storage across hybrid data sources, projections that promise 10x faster query speeds on pre-aggregating data, and further improvements to the Dart query engine.
To learn more, check out our 2024 Product Innovation Recap. In addition to providing context on our strategic growth, you’ll find more details on our 2025 vision plus a list of additional resources at the end of the article. Whether or not you choose to read further, we hope you’ll stay with us on our journey to reshape the real-time data space.
 Architecture
Architecture Deployment
Deployment Ingestion
Ingestion Modeling
Modeling Operations
Operations Development
Development


