Apr 16, 2024
How to Monitor Your IoT Environment in Real Time
As IoT environments become more complex, so too does data grow in volume, variety, and velocity. Learn why, when, and how to monitor your IoT environment.
Learn MorePollfish, the “easiest and most affordable way to get real-time insights from real consumers”, delivers democratic, real-time insights with an innovative Apache Druid-powered pipeline that includes microservices leveraging an open-source Scala library for Apache Druid called Scruid. Anastasios Skarlatidis , Director of Data Engineering and Science at Pollfish, tells us more.
The Pollfish advanced data collection platform enables application developers to create mobile app and game surveys, reaching more than half-a-billion real consumers, helping global companies inform advertising, branding, market research, content, and product strategies with fresh and fast data.
“Whether understanding the time it will take to collect answers from their audience of interest, or breaking down results in real-time as respondents answer surveys, Druid delivers the high-performance time-series OLAP database we need to monitor, measure and explore data in real-time.”
Researchers extract and query statistical information on a plethora of dimensions, including income, gender, age distribution, country, state, city and geographical area over multiple time intervals with varying time granularities.
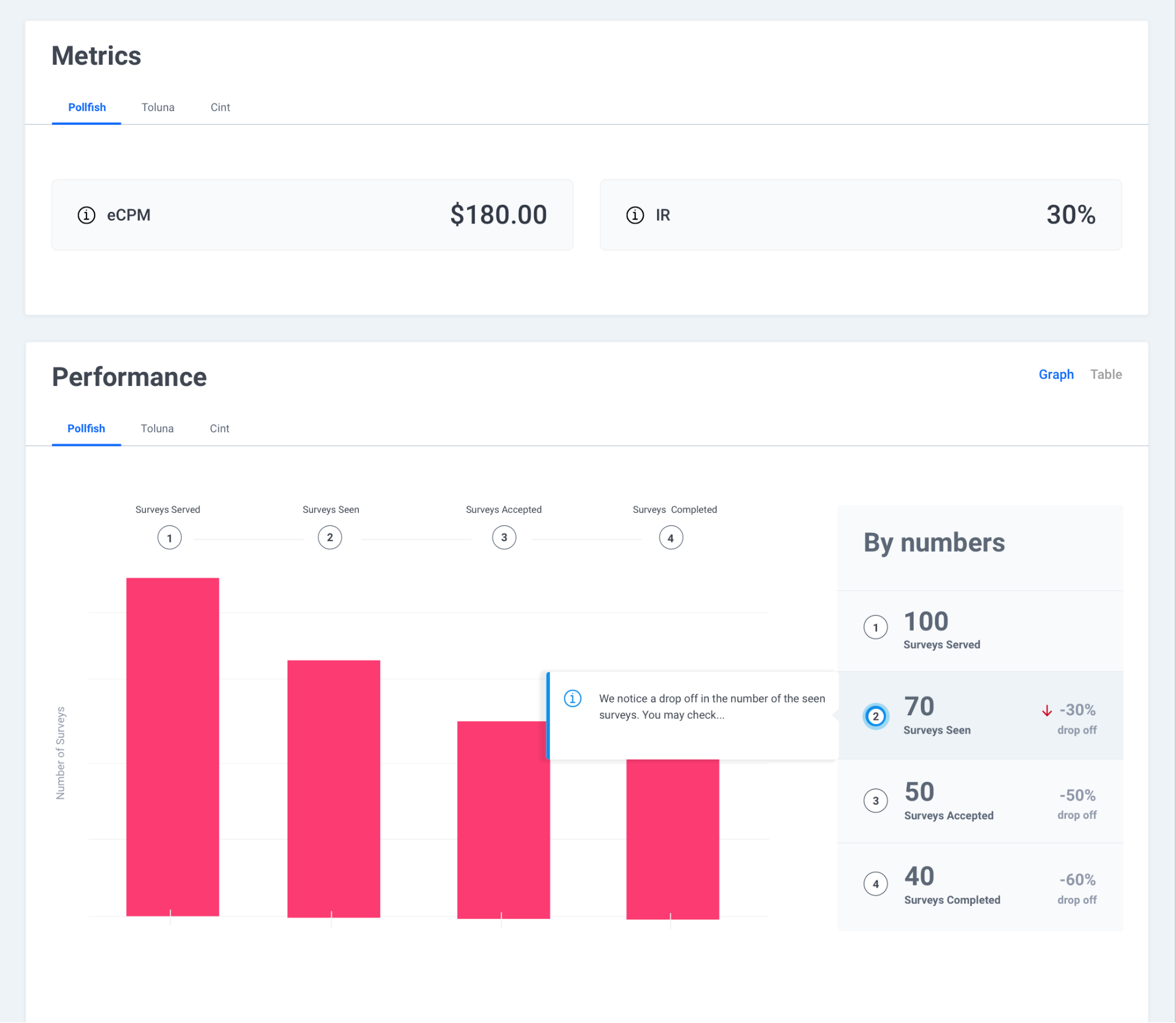
Real-time analytics dashboards show survey performance data: revenue, eCPM, funnel survey participation and more, live and direct from the stream.
The majority of data for analysis in this low-latency pipeline is passed through Apache Kafka, backed by a compute stack composed of Spark, Flink and Akka Streams. Micro-services are implemented mainly in Finatra / Finagle and provide RESTful and Thrift APIs. Cassandra and PostgreSQL live alongside Apache Druid and an HDFS-compatible data lake for raw data which is, for the most part, stored in Parquet and made accessible via Hive.
Enrichment processes (e.g., transformations, enrichments with demographic and geographic data, etc.) publish data to the Apache Kafka® stream, where Apache Druid acts a native sink powering Metabase and Looker for those ad-hoc queries, BI tasks and internal dashboards.

With support for Group By, Top N, Timeseries, Scan, and Search queries, Scruid enables geo-spatial queries, context adjustments per query, and can handle large payloads with streaming. The advanced client enables cached connection pools, load-balancing, and incorporates strategies to handle failures and authentication. Scruid is completely non-blocking / asynchronous, giving a rich high-level API for creating queries for Druid native queries, as well as for SQL.
“Apache Druid accelerates and simplifies the process of exploring the data. On the one hand, you have a system that ingests real-time data and on the other hand, the same system, can directly answer any analytical query.”
Pollfish have built an inspirational example of the democratic, real-time data revolution.
Come into the spotlight! Share your Apache Druid story with the whole community, too. Email community@imply.io and we will get the ball rolling!
How to Monitor Your IoT Environment in Real Time
As IoT environments become more complex, so too does data grow in volume, variety, and velocity. Learn why, when, and how to monitor your IoT environment.
Learn MoreHow GameAnalytics Provides Flexible Data Exploration with Imply
Learn how GameAnalytics, the leading analytics provider for the gaming industry, provides insights on over 100,000 games, 1.75 billion players, and 24 billion monthly sessions.
Learn MoreSmart Devices, Intelligent Insights: How Rivian and Thing-it use Apache Druid for IoT Analytics
Learn how engineers and architects from electric vehicle manufacturer Rivian and smart asset management platform Thing-it use Apache Druid for their IoT analytics environments.
Learn MoreWhat’s new in Imply Polaris – January 2024
At Imply, we're excited to share the latest enhancements in Imply Polaris, our real-time analytics Database-as-a-Service (DBaaS) powered by Apache Druid®. Our commitment to refining your experience with Polaris...
Learn MoreIntroducing Apache Druid 29.0
Apache Druid® is an open-source distributed database designed for real-time analytics at scale. We are excited to announce the release of Apache Druid 29.0. This release contains over 350 commits & 67 contributors.
Learn MoreApache Druid vs. ClickHouse
If your project needs a real-time analytics database that provides subsecond performance at scale you should consider both Apache Druid and ClickHouse. Find out how to make an informed choice.
Learn MoreEnhancing Data Security with Role-Based Access Control in Druid and Imply
Managing user access to relevant data is a crucial aspect of any data platform. In a typical Role Based Access Control (RBAC) setup, users are assigned roles that determine their access to relevant data. We...
Learn MoreComparing Data Formats for Analytics: Parquet, Iceberg, and Druid Segments
In this blog, I will give you a detailed overview of each choice. We will cover key features, benefits, defining characteristics, and provide a table comparing the file formats. Dive in and explore the characteristics...
Learn MoreScheduling batch ingestion with Apache Airflow
This guide is your map to navigating the confluence of Airflow and Druid for smooth batch ingestion. We'll get you started by showing you how to setup Airflow and the Druid Provider and use it to ingest some...
Learn MoreA Buyer’s Guide to OLAP Tools
How do OLAP databases work—and which one is right for you? Read this blog post to learn more about which OLAP solutions are best for different use cases.
Learn MoreWhat is IoT Analytics?
Because it deals with fast-moving, real-time data, IoT analytics is uniquely challenging. Learn how to overcome these challenges and how to extract (and act on) valuable insights from IoT data.
Learn MoreOLTP and OLAP Databases: How They Differ and Where to Use Them
Learn about the differences between analytical and transactional databases—their strengths and weaknesses, what they’re used for, and which option to choose for your own use case.
Learn MoreQuery from deep storage: Introducing a new performance tier in Apache Druid
Now, Druid offers a simpler, cost-effective solution with its new feature, Query from Deep Storage. This feature enables you to query Druid’s deep storage layer directly without having to preload all of your...
Learn MoreHow KakaoBank Uses Imply for Financial Analysis
As a mobile-first digital platform, KakaoBank accumulates a substantial amount of data. Therefore, analysts need a solution that can effectively analyze and pre-process large quantities of data, visualize the...
Learn MoreJoins, Multi-Stage Queries, and More: Relive the Excitement of Druid Summit 2023
Druid Summit kicked off its fourth year as a global gathering of minds passionate about real-time analytics and the power of Apache Druid. This year’s event revealed a common theme: the growing significance...
Learn MoreAn Introduction to Online Analytical Processing (OLAP)
Online analytical processing (OLAP) analyzes data at scale—and provides actionable insights to organizations. Learn about how OLAP works, what a data cube is, and which OLAP product to use.
Learn MoreReal-Time Data: What it is, Why it Matters, and More
Real-time data travels directly from the source to end users, so that it can be processed and acted on instantly. Learn all about the challenges, benefits, and best practices for real-time data.
Learn MoreDruid vs Pinot: Choosing the best database for Real-Time Analytics
Do you want fast analytics, with subsecond queries, high concurrency, and combination of streams and batch data? If so, you want real-time analytics, and you probably want to consider the two Apache Software...
Learn MoreWhat’s new in Imply Polaris – October and November 2023
At Imply, our commitment to continually improving your experience with Imply Polaris—our real-time analytics Database-as-a-Service (DBaaS) powered by Apache Druid®—is evident in recent developments. Over...
Learn MoreIntroducing Apache Druid 28.0.0
Apache Druid 28.0, an open-source database for real-time analytics, introduces Async queries, UNION ALL support, SQL WINDOW functions, enhanced ingestion features, including multi-Kafka topic support, and...
Learn MoreMigrating Data From S3 To Apache Druid
This blog covers the rationale, advantages, and step-by-step process for data transfer from AWS s3 to Apache Druid for faster real-time analytics and querying.
Learn MoreWhat’s new in Imply Polaris, our real-time analytics DBaaS – September 2023
Every week, we add new features and capabilities to Imply Polaris. Throughout September, we've focused on enhancing your experience as you explore trials, navigate data integration, oversee data management,...
Learn MoreIntroducing incremental encoding for Apache Druid dictionary encoded columns
In this blog post we deep dive on a recent engineering effort: incremental encoding of STRING columns. In preliminary testing, it has shown to be quite promising at significantly reducing the size of segment...
Learn MoreMigrate Analytics Data from MongoDB to Apache Druid
This blog presents a concise guide on migrating data from MongoDB to Druid. It includes Python scripts to extract data from MongoDB, save it as CSV, and then ingest it into Druid. It also touches on maintaining...
Learn MoreHow Druid Facilitates Real-Time Analytics for Mass Transit
Mass transit plays a key role in reimagining life in a warmer, more densely populated world. Learn how Apache Druid helps power data and analytics for mass transit.
Learn MoreMigrate Analytics Data from Snowflake to Apache Druid
This blog outlines the steps needed to migrate data from Snowflake to Apache Druid, a platform designed for high-performance analytical queries. The article covers the migration process, including Python scripts...
Learn MoreApache Kafka, Flink, and Druid: Open Source Essentials for Real-Time Data Applications
Apache Kafka, Flink, and Druid, when used together, create a real-time data architecture that eliminates all these wait states. In this blog post, we’ll explore how the combination of these tools enables...
Learn MoreVisualizing Data in Apache Druid with the Plotly Python Library
In today's data-driven world, making sense of vast datasets can be a daunting task. Visualizing this data can transform complicated patterns into actionable insights. This blog delves into the utilization of...
Learn MoreBringing Real-Time Data to Solar Power with Apache Druid
In a rapidly warming world, solar power is critical for decarbonization. Learn how Apache Druid empowers a solar equipment manufacturer to provide real-time data to users, from utility plant operators to homeowners
Learn MoreWhen to Build (Versus Buy) an Observability Application
Observability is the key to software reliability. Here’s how to decide whether to build or buy your own solution—and why Apache Druid is a popular database for real-time observability
Learn MoreHow Innowatts Simplifies Utility Management with Apache Druid
Data is a key driver of progress and innovation in all aspects of our society and economy. By bringing digital data to physical hardware, the Internet of Things (IoT) bridges the gap between the online and...
Learn MoreThree Ways to Use Apache Druid for Machine Learning Workflows
An excellent addition to any machine learning environment, Apache Druid® can facilitate analytics, streamline monitoring, and add real-time data to operations and training
Learn MoreIntroducing Apache Druid 27.0.0
Apache Druid® is an open-source distributed database designed for real-time analytics at scale. Apache Druid 27.0 contains over 350 commits & 46 contributors. This release's focus is on stability and scaling...
Learn MoreUnleashing Real-Time Analytics in APJ: Introducing Imply Polaris on AWS AP-South-1
Imply, the company founded by the original creators of Apache Druid, has exciting news for developers in India seeking to build real-time analytics applications. Introducing Imply Polaris, a powerful database-as-a-Service...
Learn MoreEmbedding Visualizations using React and Express
In this guide, we will walk you through creating a very simple web app that shows a different embedded chart for each user selected from a drop-down. While this example is simple it highlights the possibilities...
Learn MoreApache Druid: Making 1000+ QPS for Analytics Look Easy
This 2-part blog post explores key technical considerations to support high QPS for analytics and the strengths of Apache Druid
Learn MoreThings to Consider When Scaling Analytics for High QPS
This 2-part blog post explores key technical considerations to support high QPS for analytics and the strengths of Apache Druid
Learn MoreAutomate Streaming Data Ingestion with Kafka and Druid
In this blog post, we explore the integration of Kafka and Druid for data stream management and analysis, emphasizing automatic topic detection and ingestion. We delve into the creation of 'Ingestion Spec',...
Learn MoreSchema Auto-Discovery with Apache Druid
This guide explores configuring Apache Druid to receive Kafka streaming messages. To demonstrate Druid's game-changing automatic schema discovery. Using a real-world scenario where data changes are handled...
Learn MoreWhat’s new in Imply Polaris – Q2 2023
Imply Polaris, our ever-evolving Database-as-a-Service, recently focused on global expansion, enhanced security, and improved data handling and visualization. This fully managed cloud service, based on Apache...
Learn MoreIntroducing hands-on developer tutorials for Apache Druid
The objective of this blog is to introduce the new set of interactive tutorials focused on the Druid API fundamentals. These tutorials are available as Jupyter Notebooks and can be downloaded as a Docker container.
Learn MoreIntroducing Schema Auto-Discovery in Apache Druid
In this blog article I’ll unpack schema auto-discovery, a new feature now available in Druid 26.0, that enables Druid to automatically discover data fields and data types and update tables to match changing...
Learn MoreExploring Unnest in Druid
Druid now has a new function, Unnest. Unnest explodes an array into individual elements. This blog contains design methodology and examples for this new Unnest function both from native and SQL binding perspectives.
Learn MoreWhat’s new in Imply Polaris – Our Real-Time Analytics DBaaS
Every week we add new features and capabilities to Imply Polaris. This month, we’ve expanded security capabilities, added new query functionality, and made it easier to monitor your service with your preferred...
Learn MoreIntroducing Apache Druid 26.0
Apache Druid® 26.0, an open-source distributed database for real-time analytics, has seen significant improvements with 411 new commits, a 40% increase from version 25.0. The expanded contributor base of 60...
Learn MoreACID and Apache Druid
ACID and Druid, an interesting dive into some of the Druid capabilities in the light of ACID compliance
Learn MoreHow to Build a Sentiment Analysis Application with ChatGPT and Druid
Leveraging ChatGPT for sentiment analysis, when combined with Apache Druid, offers results from large data volumes. This integration is easily achievable, revealing valuable insights and trends for businesses...
Learn MoreSnowflake and Apache Druid
In this blog, we will compare Snowflake and Druid. It is important to note that reporting data warehouses and real-time analytics databases are different domains. Choosing the right tool for your specific requirements...
Learn MoreLearn how to achieve sub-second responses with Apache Druid
Learn how to achieve sub-second responses with Apache Druid. This article is an in-depth look at how Druid resolves queries and describes data modeling techniques that improve performance.
Learn MoreApache Druid – Recovering Dropped Segments
Apache Druid uses load rules to manage the ageing of segments from one historical tier to another and finally to purge old segments from the cluster. In this article, we’ll show what happens when you make...
Learn MoreReal-Time Analytics: Building Blocks and Architecture
This blog identifies the key technical considerations for real-time analytics. It answers what is the right data architecture and why. It spotlights the technologies used at Confluent, Reddit, Target and 1000s...
Learn MoreTransactions Come and Go, but Events are Forever
For decades, analytics has focused on Transactions. While Transactions are still important, the future of analytics is understanding Events.
Learn MoreWhat’s new in Imply Polaris – Our Real-Time Analytics DBaaS
This blog explains some of the new features, functionality and connectivity added to Imply Polaris over the last two months. We've expanded ingestion capabilities, simplified operations and increased reliability...
Learn MoreElasticsearch and Druid
This blog will help you understand what Elasticsearch and Druid do well and will help you decide whether you need one or both to reach your goals
Learn MoreWow, that was easy – Up and running with Apache Druid
The objective of this blog is to provide a step-by-step guide on setting up Druid locally, including the use of SQL ingestion for importing data and executing analytical queries.
Learn MoreTop 7 Questions about Kafka and Druid
Read on to learn more about common questions and answers about using Kafka with Druid.
Learn MoreTales at Scale Podcast Kicks off with the Apache Druid Origin Story
Tales at Scale cracks open the world of analytics projects and shares stories from developers and engineers who are building analytics applications or working within the real-time data space. One of the key...
Learn MoreReal-time Analytics Database uses partitioning and pruning to achieve its legendary performance
Apache Druid uses partitioning (splitting data) and pruning (selecting subset of data) to achieve its legendary performance. Learn how to use the CLUSTERED BY clause during ingestion for performance and high...
Learn MoreEasily embed analytics into your own apps with Imply’s DBaaS
This blog explains how developers can leverage Imply Polaris to embed robust visualization options directly into their own applications without them having to build a UI. This is super important because consuming...
Learn MoreBuilding an Event Analytics Pipeline with Confluent Cloud and Imply’s real time DBaaS, Polaris
Learn how to set up a pipeline that generates a simulated clickstream event stream and sends it to Confluent Cloud, processes the raw clickstream data using managed ksqlDB in Confluent Cloud, delivers the processed...
Learn MoreReal time DBaaS comes to Europe
We are excited to announce the availability of Imply Polaris in Europe, specifically in AWS eu-central-1 region based in Frankfurt. Since its launch in March 2022, Imply Polaris, the fully managed Database-as-a-Service...
Learn MoreStream big, think bigger—Analyze streaming data at scale in 2023
Imply is predicting the next "big thing" in 2023 will be analyzing streaming data in real time (and Druid is built for just that!)
Learn MoreShould You Build or Buy Security Analytics for SecOps?
When should you build—or buy—a security analytics platform for your environment? Here are some common considerations—and how Apache Druid is the ideal foundation for any in-house security solution.
Learn MoreIntroducing Apache Druid 25.0
Apache Druid 25.0 contains over 293 updates from over 56 contributors.
Learn More2022 in Review: A Breakout Year for Druid, A Banner Year for Imply
2022 was a great year for Druid AND Imply!
Learn MoreDruid and SQL syntax
This is a technical blog, which summarises the process of extending the Druid's SQL grammar for ingestion and delves into the nitty gritty of Calcite.
Learn MoreNative support for semi-structured data in Apache Druid
Describes a new feature- ingest complex data as is into Druid- massive improvement in developer productivity
Learn MoreReal-Time Analytics with Imply Polaris: From Setup to Visualization
Imply Polaris offers reduced operational overhead and elastic scaling for efficient real-time analytics that helps you unlock your data's potential.
Learn MoreDatanami Award
Apache Druid won Datanami's 2022 Readers’ and Editors’ Choice Awards for Reader's Choice "Best Data and AI Product or Technology: Analytics Database".
Learn MoreAlerting and Security Features in Polaris
Describes new features - alerts and some security features- and how Imply customers can leverage it
Learn MoreIngestion from Amazon Kinesis and S3 into Imply Polaris
Imply Polaris now supports data ingestion from Amazon Kinesis and Amazon S3
Learn MoreGetting the Most Out of your Data
Ingesting data from one table to another is easy and fast in Imply Polaris!
Learn MoreCombating financial fraud and money laundering at scale with Apache Druid
Learn how Apache Druid enables financial services firms and FinTech companies to get immediate insights from petabytes-plus data volumes for anti-fraud and anti-money laundering compliance.
Learn MoreWhat’s new in Imply – December 2022
This is a what's new to Imply in Dec 2022. We’ve added two new features to Imply Polaris to make it easier for your end users to take advantage of real-time insights.
Learn MoreWhat’s New in Imply Polaris – November 2022
This blog provides an overview for the new features, functionality, and connectivity to Imply Polaris for November 2022.
Learn MoreImply Pivot delivers the final mile for modern analytics applications
This blog is focused on how Imply Pivot delivers the final mile for building an anlaytics app. It showcases two customer examples - Twitch and ironsource.
Learn MoreWhy Analytics Need More than a Data Warehouse
For decades, analytics has been defined by the standard reporting and BI workflow, supported by the data warehouse. Now, 1000s of companies are realizing an expansion of analytics beyond reporting, which requires...
Learn MoreWhy Open Source Matters for Databases
Apache Druid is at the heart of Imply. We’re an open source business, and that’s why we’re committed to making Druid the best open source database for modern analytics applications
Learn MoreIngestion from Confluent Cloud and Kafka in Polaris
How to ingest data into Imply Polaris from Confluent Cloud and from Apache Kafka
Learn MoreWhat Makes a Database Built for Streaming Data?
For an analytics app to handle real-time, streaming sources, it must be built for streaming data. Druid has 3 essential features for stream data.
Learn MoreSQL-based Transformations and JSON Columns in Imply Polaris
You can easily do data transformations and manage JSON data with Imply Polaris, both using SQL.
Learn MoreApproximate Distinct Counts in Imply Polaris
When it comes to modern data analytics applications, speed is of the utmost importance. In this blog we discuss two approximation algorithms which can be used to greatly enhance speed with only a slight reduction...
Learn MoreThe next chapter for Imply Polaris: celebrating 250+ accounts, continued innovation
Today we announced the next iteration of Imply Polaris, the fully managed Database-as-a-Service that helps you build modern analytics applications faster, cheaper, and with less effort. Since its launch in...
Learn MoreIntroducing Imply’s Total Value Guarantee for Apache Druid
Apache Druid 24.0 contains 450 updates and new features, major performance enhancements, bug fixes, and major documentation improvements
Learn MoreIntroducing Apache Druid 24.0
Apache Druid 24.0 contains 450 updates and new features, major performance enhancements, bug fixes, and major documentation improvements
Learn MoreUsing Imply Pivot with Druid to Deduplicate Timeseries Data
Imply Pivot offers multi step aggregations, which is valuable for timeseries data where measures are not evenly distributed in time.
Learn MoreA Look Under the Surface at Polaris Security
We have taken a security-first approach in building the easiest real-time database for modern analytics applications.
Learn MoreUpserts and Data Deduplication with Druid
A look at what can be done with Druid for upserts and data deduplication.
Learn MoreWhat Developers Can Build with Apache Druid
We obviously talk a lot about #ApacheDruid on here. But what are folks actually building with Druid? What is a modern analytics application, exactly? Let's find out
Learn MoreWhen Streaming Analytics… Isn’t
Nearly all databases are designed for batch processing, which leaves three options for stream analytics.
Learn MoreApache Druid vs. Snowflake
Elasticity is important, but beware the database that can only save you money when your application is not in use. The best solution will have excellent price-performance under all conditions.
Learn MoreDruid 0.23 – Features And Capabilities For Advanced Scenarios
Many of Druid’s improvements focus on building a solid foundation, including making the system more stable, easier to use, faster to scale, and better integrated with the rest of the data ecosystem. But for...
Learn MoreIntroducing Apache Druid 0.23
Apache Druid 0.23.0 contains over 450 updates, including new features, major performance enhancements, bug fixes, and major documentation improvements.
Learn MoreAn Opinionated Guide to Component APIs
We have collected a number of guidelines for React component APIs that make components more predictable in terms of behavior and performance.
Learn MoreDruid Architecture & Concepts
In a world full of databases, learn how Apache Druid makes real-time analytics apps a reality in this Whitepaper from Imply
Learn More3 decisions that shaped the Polaris UI
Imply Polaris is a fully managed database-as-a-service for building realtime analytics applications. John is the tech lead for the Polaris UI, known internally as the Unified App. It began with a profound question:...
Learn MoreHow Imply Polaris takes a security-first approach
A primer for developers on security tools and controls available in Imply Polaris
Learn MoreImply Raises $100MM in Series D funding
There is a new category within data analytics emerging which is not centered in the world of reports and dashboards (the purview of data analysts and data scientists), but instead centered in the world of applications...
Learn MoreImply Named “Cool Database Vendor” by CRN
There can’t be one database good at everything. When it comes to real-time analytics, you need a database built for it.
Learn MoreLiving the Stream
We are in the early stages of a stream revolution, as developers build modern transactional and analytic applications that use real-time data continuously delivered.
Learn More