Imply Lumi Product Preview: Removing the Cost–Performance Tradeoff in Observability
Feb 25, 2026
David Gee
If you caught our recent product update, you’ve already seen the pace of development on Imply Lumi has been relentless. Last quarter, we delivered major performance and usability improvements to data collection, expanded our SPL support, and released new enterprise deployment options that allow you to run Lumi inside your own cloud accounts.
The concept of a decoupled observability warehouse is resonating across the market, and customers are proving it. A global investment bank reduced observability costs by over 70% with Lumi. And we’re fast approaching full compatibility with the Splunk ecosystem, including transparent federated search, knowledge bundle replication with lookups, and complete SPL support.
But compatibility is just table stakes. A truly decoupled observability data layer must eliminate the structural tradeoffs that legacy platforms force teams to accept.
This quarter, we’re delivering new capabilities that make all of your data queryable without compromise, whether it’s flowing through Lumi or sitting untouched in your cloud. Here’s how.
One query experience for all your data
Observability costs are under a microscope. Gartner’s April 2025 report, Get Your Observability Spend Under Control, found that median enterprise spend on a single observability vendor now exceeds $800,000 annually, with log analysis alone accounting for more than half of total spend at larger organizations.
The root of the problem is a forced tradeoff between cost and access.
It shows up in two ways.
Data that ages out
Logs from three hours ago are invaluable during an outage. Sixty days later, they’re necessary for compliance and trend analysis, but don’t need to be sitting on hot infrastructure. Existing platforms offer various flavors of tiering, but eventually every tier bottoms out: data moves to progressively lower-performance storage until it’s offloaded to object storage entirely.
Data that never gets loaded
VPC flow logs, CloudTrail audit events, DNS query logs, CDN access logs, AI workload telemetry: massive volumes of event data that land in object storage, lakehouses, or data warehouses because the cost and complexity of ingestion into an observability tool aren’t justified by how often they’re queried.
Both paths converge on the same dead end. Real-time data powers detection: dashboards, alerts, anomaly triggers. But when an incident occurs, or an audit is required, investigation means scanning massive volumes of historical data, fast.
Teams are left with two options.
Hydrate it back in, paying for parsing, indexing, and storage overhead you’ll rarely use again.
Query it in place with Athena or Spark-based engines, where you’ll need to define strict schemas against messy, semi-structured data, learn a specialized query dialect, and wait.
Even when platforms do support querying across tiers, it comes at a cost that isn’t on the invoice. A slow-running query against an audit dataset or an ad hoc incident investigation pulls from the same compute pool that powers your dashboards and alerting. The query that’s supposed to answer “what happened last quarter” ends up degrading the monitors telling you what’s happening right now.
Existing platforms can distinguish between hot and cold data. They just make you pay for it in friction, performance, or both. Lumi doesn’t.
This is why we call Lumi an Observability Warehouse. Just as data warehouses decoupled analytics from transactional systems, Lumi decouples observability storage and compute from the interaction layer — eliminating the cost–performance tradeoff.
On-demand workloads for Lumi
On-demand workloads let you assign dedicated compute to any data that doesn’t need always-on infrastructure.
Define workload rules based on any combination of time, dataset, source, or custom filter, and Lumi provisions isolated compute resources for that data when you need it. Instead of paying for always-on capacity across everything, you pay for real-time compute on the data that needs it, and everything else only costs compute when it’s actually being queried.
When a query targets data served by on-demand workloads, Lumi routes it to isolated resources that spin up and scale back down when idle. The routing is transparent: Lumi inspects each query and directs it accordingly. Your queries, dashboards, and alerts work exactly as they do today.
Two technologies underpin this.
A virtual storage fabric loads infrequently accessed data from cold storage into a transient cache only when a query needs it, and evicts it when it doesn’t.
Dedicated compute pools serve those queries in full isolation from the infrastructure powering your real-time monitoring, so a historical deep-dive never degrades the operational workloads you depend on.
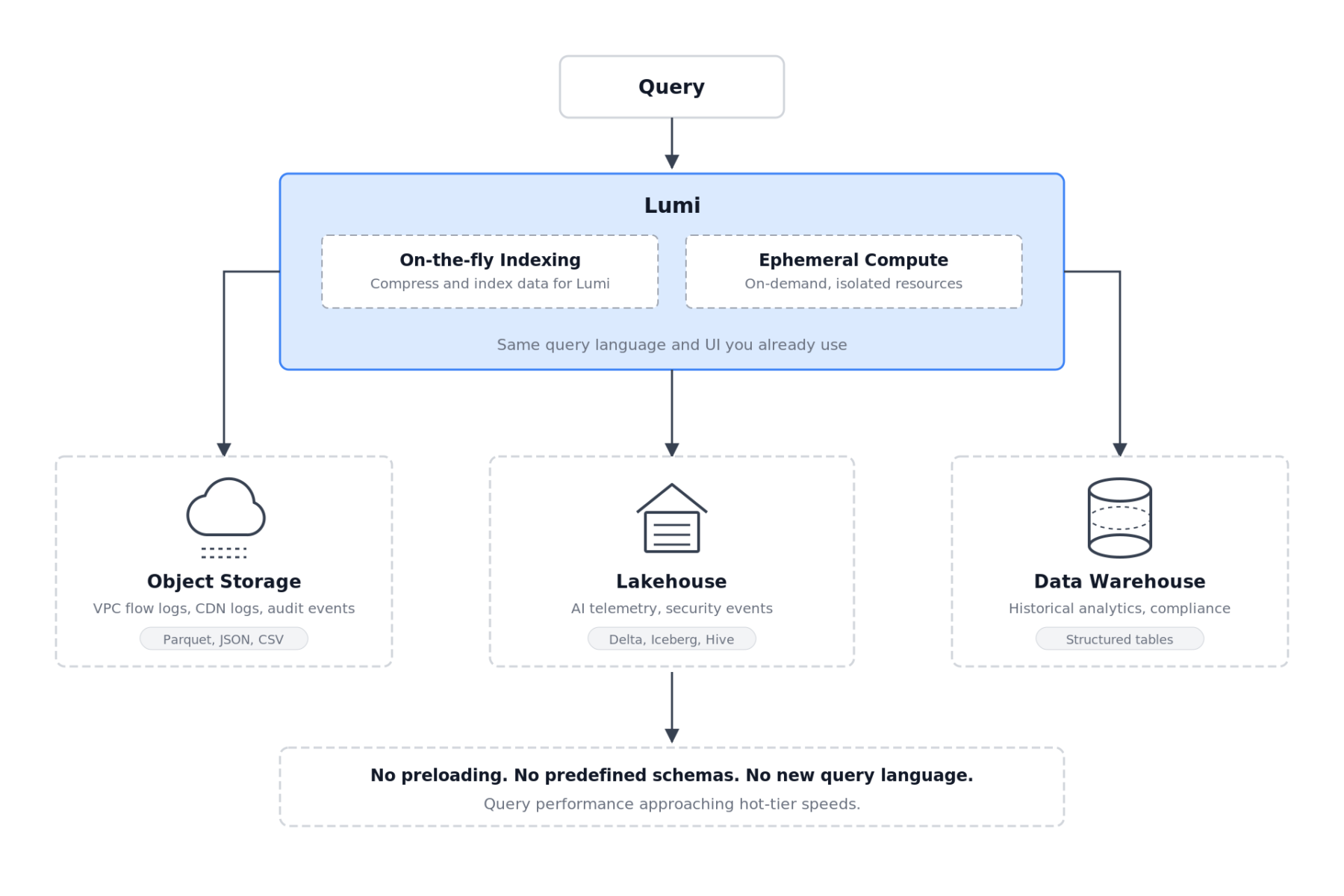
In-place querying for data in your cloud
These on-demand workloads solve the price-performance problem for data already flowing into Lumi.
But what about datasets that never make it into your observability platform in the first place?
For data sitting in cloud storage, lakehouses, or data warehouses, Lumi queries it exactly where it sits, with the same query language and UI you already use for everything else.
No preloading.
No predefined schemas.
No new query language.
What makes this fast is the same on-demand compute capability. When a query hits cloud data, Lumi applies on-the-fly compression and indexing against the target dataset. Rather than scanning raw files end to end the way Athena or Spark would, Lumi builds indexes as data is queried that lets it skip irrelevant data and decompress only what the query actually touches.
The result is query performance that approaches hot-tier speeds and outperforms those engines by orders of magnitude, on data you never had to move, transform, or model.
Bidirectional access: your lakehouse meets your observability data
Lumi doesn’t just query your cloud data. It exposes its own data back to your lakehouse tools.
Your Jupyter notebooks, Spark SQL jobs, and analytics workflows can query Lumi datasets directly, without extracting or duplicating anything. The same data powering your real-time dashboards is accessible from the tools your data engineering and security teams already live in.
Your lakehouse full of inaccessible Parquet files just became a first-class observability dataset.
Your observability data just became a first-class lakehouse citizen.
Same queries. Same tools. No boundaries.
What’s next
On-demand workloads, in-place querying, and bidirectional lakehouse access are the beginning of a broader vision for Lumi:
An observability data layer where cost, location, and infrastructure don’t dictate what you can ask of your data. Detection and investigation, real-time and historical, ingested and in-place, all queryable through a single experience.
The future of observability isn’t about adding more tiers. It’s about removing architectural constraints altogether.If you want to see what Lumi can do for your organization, request a demo.
Other blogs you might find interesting
No records found...
Feb 03, 2026
Imply Lumi product update: what’s new
Since releasing Imply Lumi in September 2025 as a decoupled data layer for observability, the Imply R&D team has been hard at work to make it easier and more economical to retain, query, and analyze observability...
The Most-Read Imply Blogs of 2025 (and what they signal for 2026)
Before we take on 2026, let’s rewind. 2025 was the year observability teams stopped asking, “How do we reduce data?” and started asking the real question: “How do we build an architecture that can keep...
Observability is at a crossroads For years, observability has promised to give teams the visibility they need to keep digital services resilient. But as data volumes explode, many leaders are realizing the...