We’re excited to announce the release of Imply 3.4 with Apache Druid 0.19 at its core. This release includes new capabilities in Druid and Pivot that bring the stack closer to standard BI capabilities along with dozens of bug fixes and enhancements.
If you’re an Imply Cloud customer or if you run Imply on Kubernetes with the self-hosted Manager, you can now upgrade to the latest version through the management UI. This release is also available for download on our getting started page.
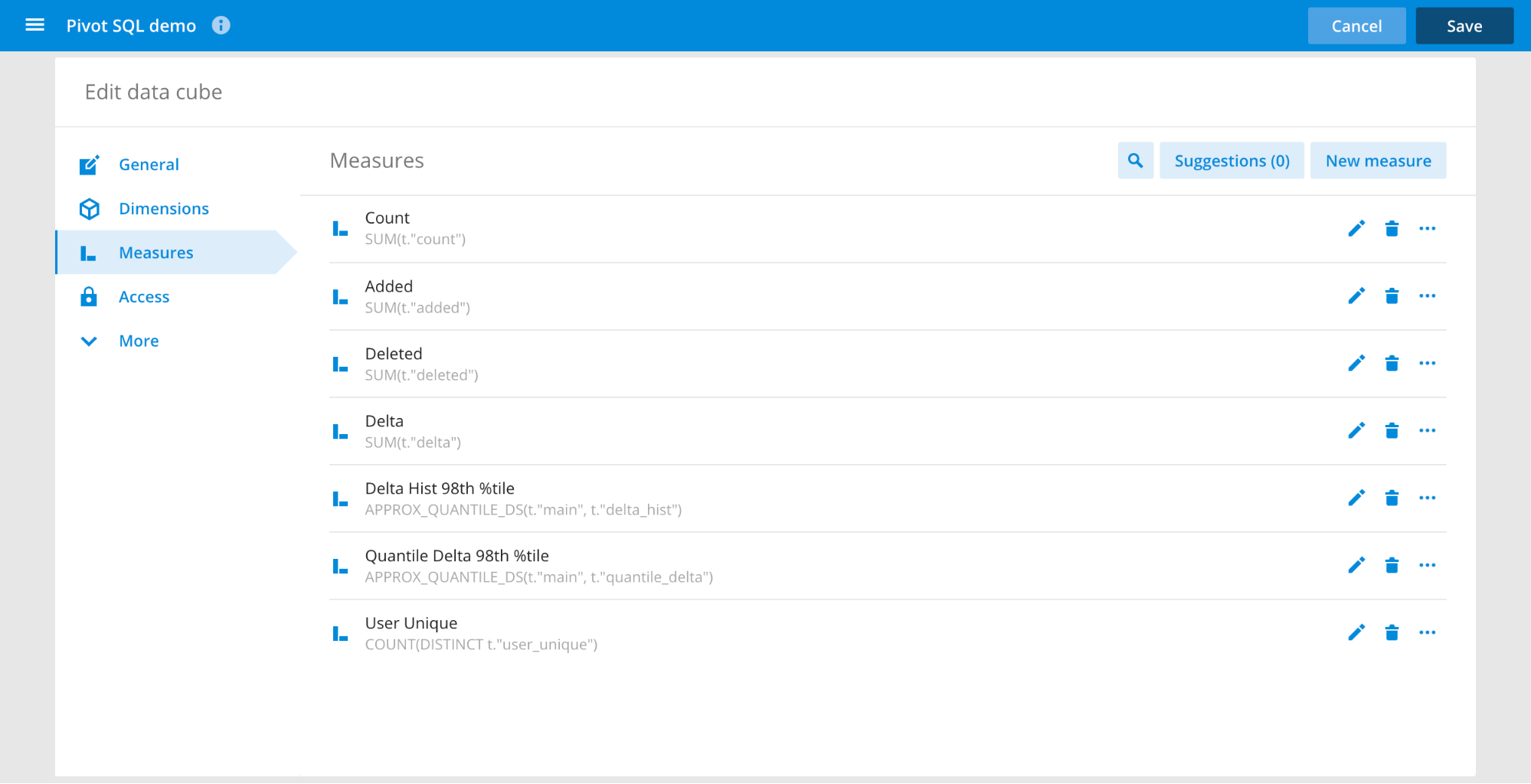
Pivot SQL (Alpha)
In Imply 3.4, we’re introducing an early preview of a new way to define data cubes in Pivot, allowing users to define custom measures and dimensions using SQL expressions instead of Plywood. We’re excited about the possibilities this feature holds for democratizing data analysis with Pivot given the broad reach of SQL, and for making it easier for people used to working with BI tools to work with Pivot. If you’d like to take it for a test drive, it can be enabled via the “Experimental features” toggle in the Advanced Settings UI.
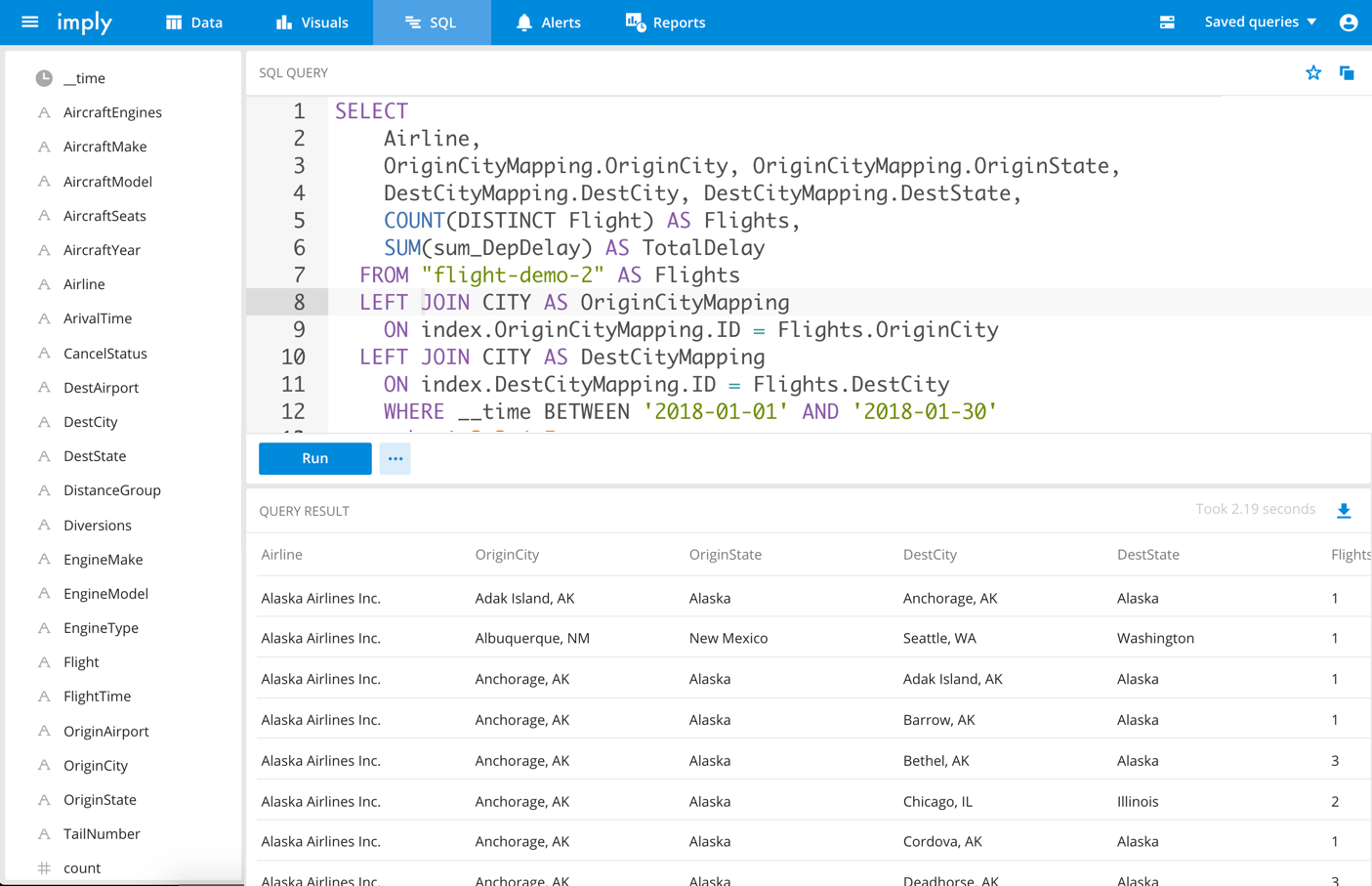
Druid Broadcast Indexed Tables (Beta)
Along the same lines, we are continuing to work on improving SQL JOIN capabilities within Druid. Imply 3.4 enables Druid SQL users to join against multi-column indexed dimension tables. This release adds numerous reliability and usability enhancements, including the ability to load indexed tables through ingestion specs, with Druid automatically handling broadcasting them to all nodes in the cluster. The screenshot shows a SELECT statement spanning multiple columns.
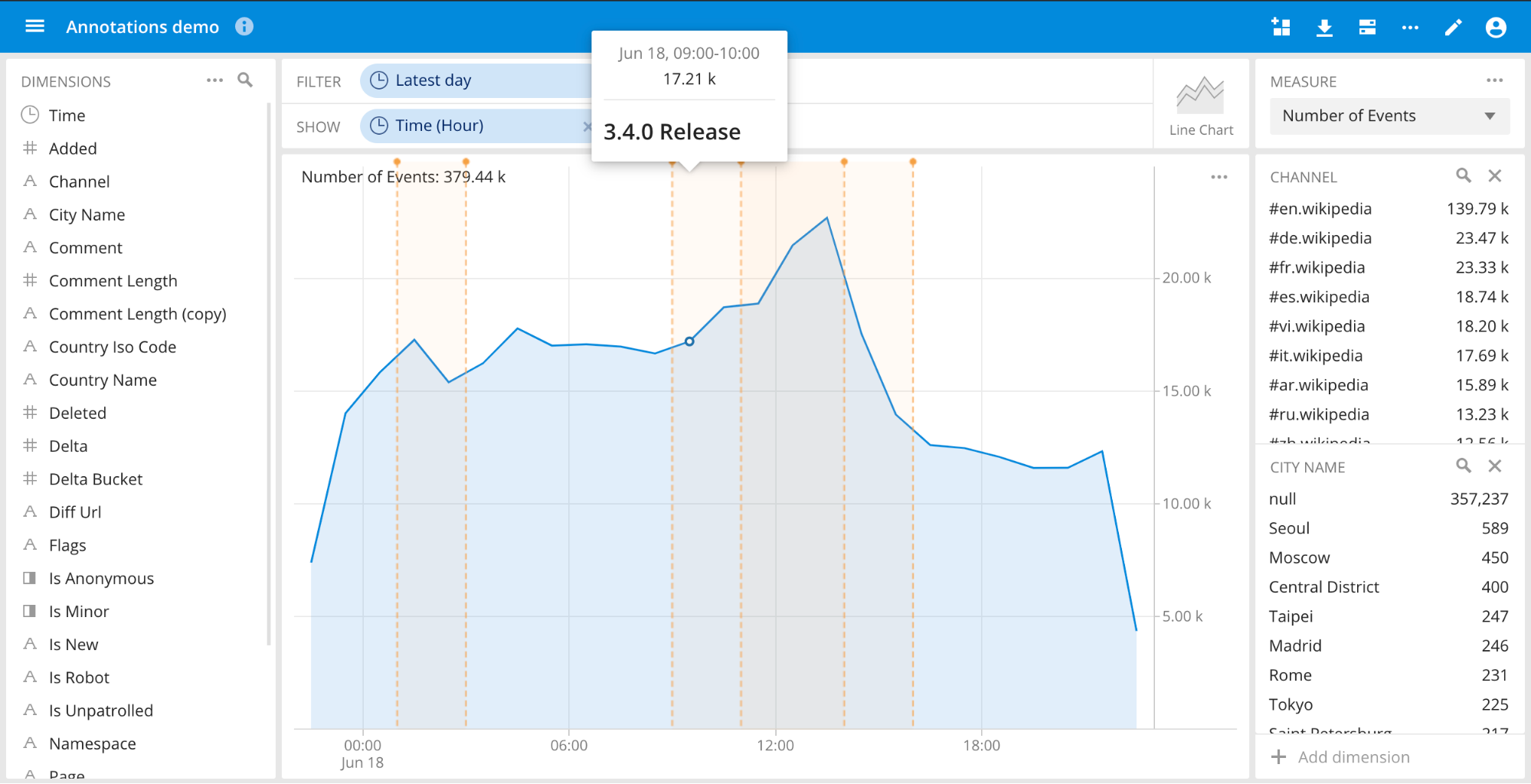
Pivot Event annotations (Alpha)
Additionally, we’re introducing a sneak peak at the ability to annotate time series views in Pivot, allowing users to easily correlate real-world events such as software releases or advertising campaigns against changes in metrics. Like Pivot SQL, this can be enabled via the “Experimental features” toggle in the Advanced Settings UI.
Other enhancements & bug fixes
Pivot in Imply 3.4 also comes with over 30 bug fixes and product enhancements. Among other things, we’ve further expanded support for comparisons and filter by measure, which now work more reliably on a number of visualizations.
Along with over 200 new features, performance enhancements and bug fixes, Druid now has vectorization turned on by default for a large number of queries, providing a performance boost that can reach 5x on some queries.
Other blogs you might find interesting
No records found...
Feb 25, 2026
Imply Lumi Product Preview: Removing the Cost–Performance Tradeoff in Observability
If you caught our recent product update, you’ve already seen the pace of development on Imply Lumi has been relentless. Last quarter, we delivered major performance and usability improvements to data...
Since releasing Imply Lumi in September 2025 as a decoupled data layer for observability, the Imply R&D team has been hard at work to make it easier and more economical to retain, query, and analyze observability...
The Most-Read Imply Blogs of 2025 (and what they signal for 2026)
Before we take on 2026, let’s rewind. 2025 was the year observability teams stopped asking, “How do we reduce data?” and started asking the real question: “How do we build an architecture that can keep...