A guide to how Apache Druid features and concepts relate to Imply Polaris
Imply Polaris serves as the “easy button” for Apache Druid, delivering key advantages that simplify operations, enhance performance, and reduce costs.
Welcome to Imply Polaris! Conceived as a cloud data warehouse for easily building real-time data applications, Polaris has been adopted by Apache Druid teams across the world looking to reduce operational burden and take advantage of Imply’s authentication, authorization, visualization, alerting, and reporting capabilities.
- Smarter scaling and reduced storage footprint: Polaris provides auto-scaling for higher performance and significantly reduced storage compared to self-managed Druid – without constant fine-tuning.
- Built-in visualization: Create customizable analytics applications for point-and-click data exploration, with optional white-labeling for customer-facing apps.
- Enterprise-grade security and reliability: Private networking, RBAC, audit logs, SSO, and guaranteed compliance fault tolerance, cluster self-healing, and rolling updates – eliminating manual intervention.
- Unique capabilities: Features like time series analysis, dimension tables (upserts) and seamless upgrades provide a competitive advantage while keeping your service always available.
- Expert support from the creators: With 24/7 committer-led support, Polaris users get access to the experts who build Druid – from onboarding to to optimization – accelerating time to value and reducing operational overhead. Combined with lower infrastructure costs, this leads to a lower total cost of ownership (TCO) compared to self-managed open-source Druid.
Imply shares your passion for Apache Druid, having chosen it to be the powerhouse behind Imply Polaris. In this guide, you’ll find technical information about how Polaris presents and manages the Druid cluster in your project, and learn about Imply’s role in managing the underlying processes, dependencies, and infrastructure that make up Polaris.
Imply Polaris in a nutshell
Polaris uses Apache Druid to offer APIs and user interfaces for fast slice-and-dice, zoom in-and-zoom out end-user analytics.
- Design and management tools enable you to design tables, lookups, and ingestion jobs.
- Secure exploration tools enable your teams to slice-and-dice, zoom in-and-out of data.
- Monitoring tools expose usage and database metrics to you and Imply’s teams.
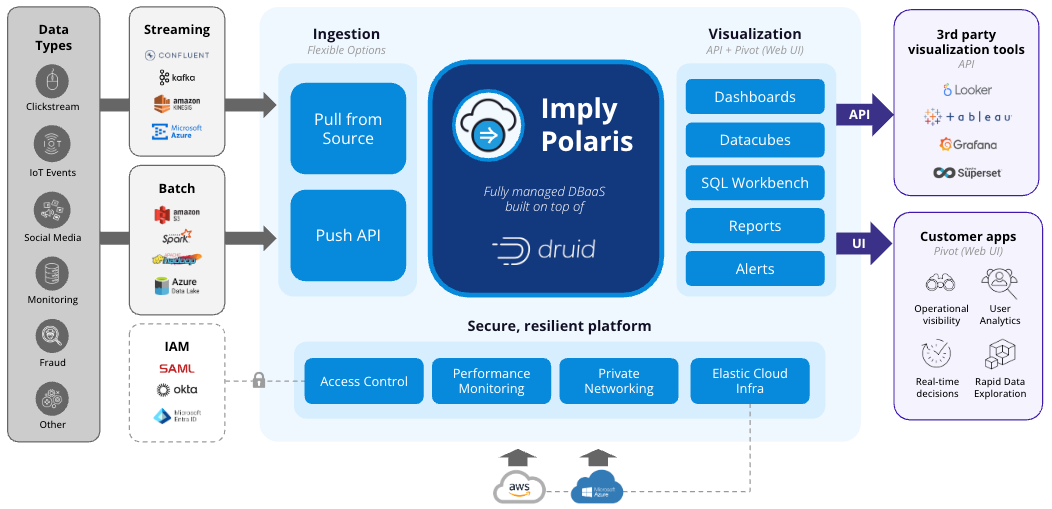
Imply Polaris tech stack architecture
Infrastructure
Polaris has a number of pre-sized clusters to choose from. Once selected, these templates prescribe the processing and storage capacity of the database instance. Imply’s chosen database is Apache Druid, with some extra bells and whistles!
The template you choose in Polaris, in part, prescribes the Apache Druid cluster that is created behind-the-scenes. The resulting Druid cluster has ingestion autoscaling, and provides ingestion, query, and data management services to Polaris.
Templates include specific extensions and Imply proprietary code. These enable such things as:
- Accurate geo functions.
- Time series functions.
- Dimension upserts.
Identity and access management features in Polaris aim to protect your cluster and its data. For example, Polaris acts as an intermediary for tasks you may be familiar with achieving through Druid APIs; when it does so, Polaris requires authentication and checks authorization.
Tables
Polaris holds configuration information for table schemas and layout and applies this to an underlying Druid data source.
When you make design changes in Polaris, it undertakes all necessary work in your Druid cluster to implement the new design. That includes changing automatic compaction configuration to ranged multi-dimension partitioning when you set data clustering (secondary partitioning), and when you change the granularity on an aggregate table.
Your Polaris table design includes the schema for the Druid data source. A table can either be strict (best for governance) or flexible (best for evolving schemas). While strict table schemas are made exclusively of declared columns, flexible table schemas can have a mix of declared and undeclared columns.
Polaris enables Druid rollup behind the scenes to create aggregate tables. Note that in Polaris, metrics are known as measures. You might also know “measures” as a type of dimension, alongside attributes. Measures are implemented by Polaris using metrics specifications, translated from input expressions.
Retention rules, including tiering and drop rules, surface in Polaris in several ways. Precache is the most obvious, with data being loaded onto Historicals behind-the-scenes. Polaris provides a UI on top of the load / drop rules from Druid and surfaces important information such as load completeness in the admin UI. In Polaris, historical servers all belong to the same tier since Polaris uses tiers themselves to provide availability zones.
Rather than directly accessing your Druid coordinator’s retention rules API, in Polaris, you update a table’s settings to modify its time periods for retention or cache. You can change these settings in the UI or using the tables API. By default, all data is precached and retained.
Polaris allows for a “soft delete” of table data when retention rules determine table data should be dropped. Polaris uses the unused segment status familiar to users of Druid to indicate a soft deletion, with a Kill task deleting the data only referencing segments older than 30 days.
While Druid lookups are limited to a pair per row, Polaris lookups are more like standard tables. Polaris lookups are able to use any column as the key column. If you do use Druid lookups, be sure to understand how to migrate lookups from Druid.
Ingestion
Every ingestion specification in Apache Druid includes a description of the input source. But unlike in Druid, Polaris allows you to administer a central catalogue of possible input sources. Those input sources are then associated with Polaris jobs.
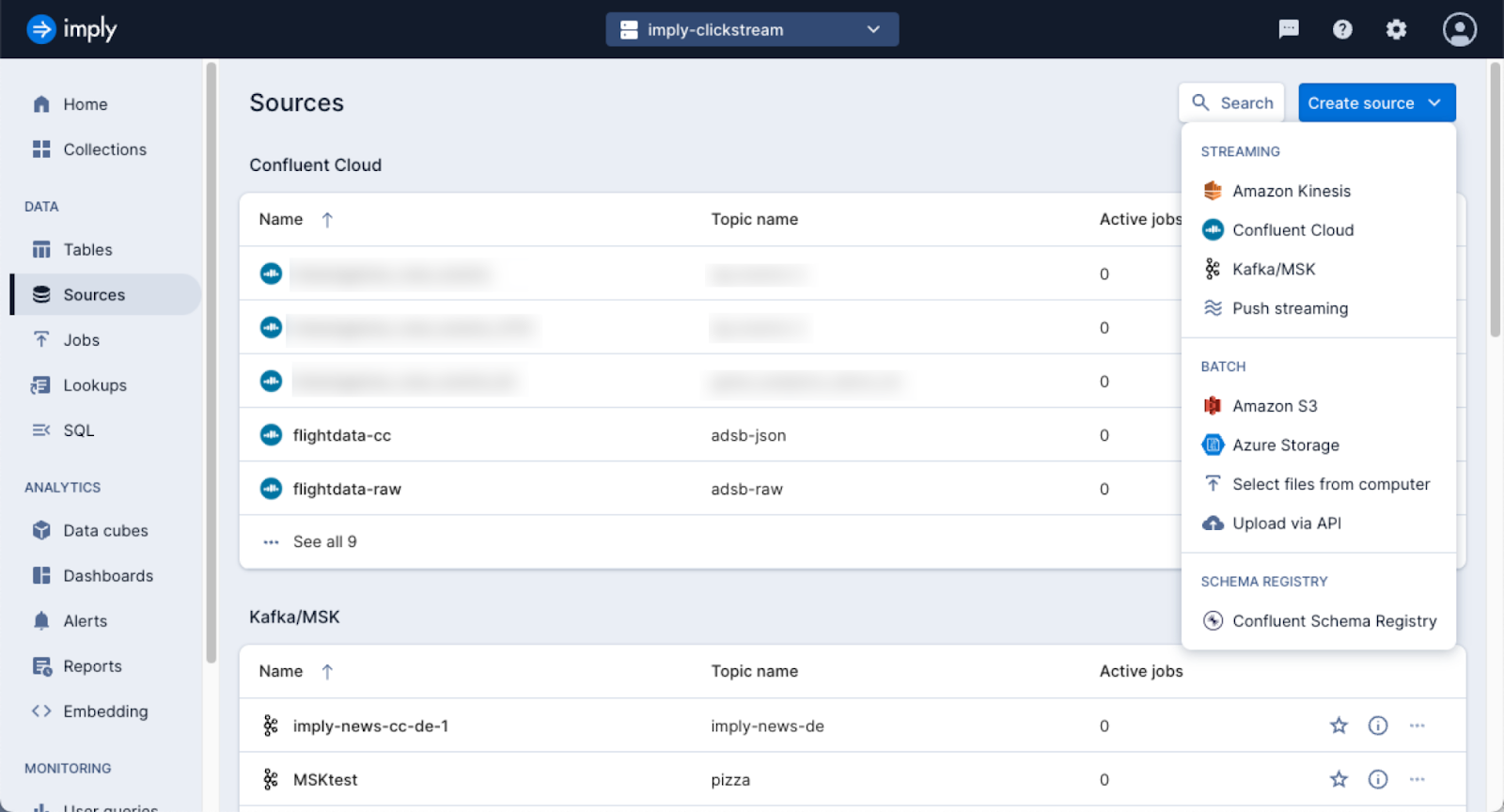
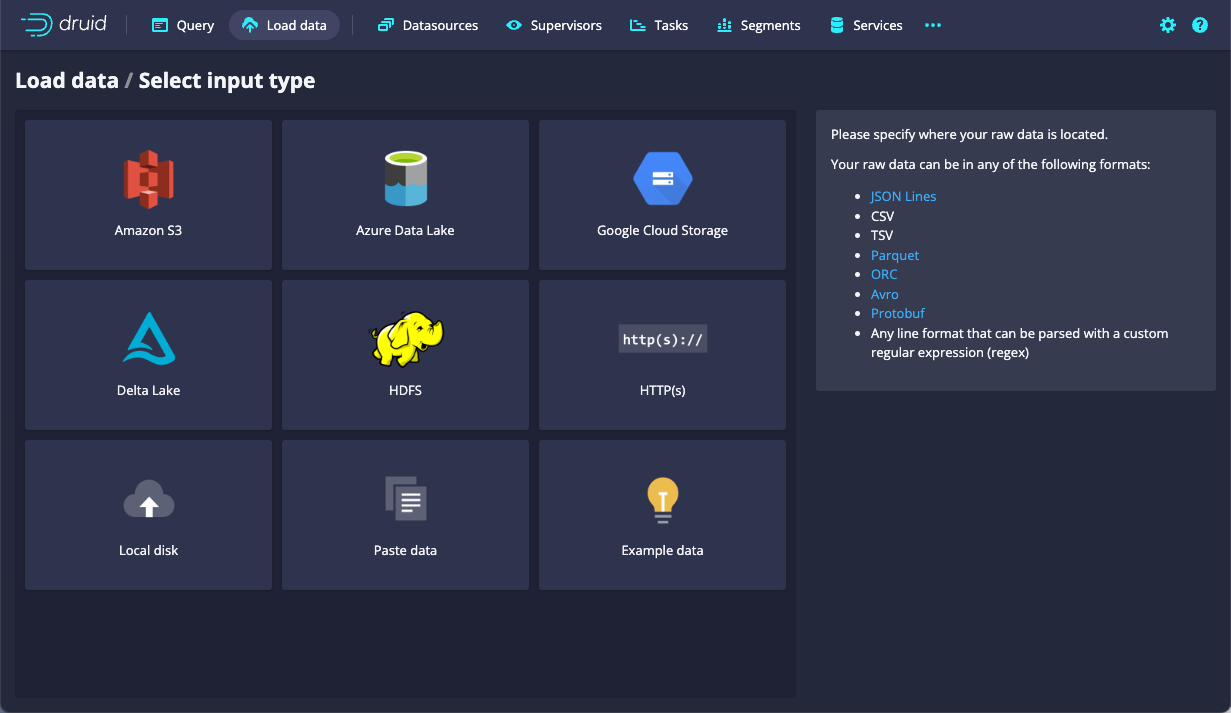
Left: Polaris sources management UI → Right: Druid load data wizard’s input type panel.
You can upload a file to Polaris directly within the sources UI and use it as a source for a table.
Jobs are an abstraction of Druid supervisors and task controllers. Streaming ingestion, for example, is handled by a “streaming”-type job.
To manage and monitor Polaris ingestion programmatically, rather than submit to Druid’s supervisor or tasks API, use the Polaris jobs API. An Imply customer success team member can help you translate Druid ingestion specifications to the Polaris API job format.
Only schemas of flexible Polaris tables can change. Consequently, for source data that might have a changeable schema, Polaris uses Druid’s schema auto-discovery.
While Druid uses native functions in native ingestion (and therefore supervisor) specification, Polaris allows you to use SQL functions. Behind the scenes, Polaris translates functions when necessary to create the right transformSpec. The same applies to ingestion-time filtering, where native filters are added to the transformSpec automatically from your Polaris design.
There is a Polaris API for push to Druid data sources, providing a stable, reliable version of the (deprecated) tranquility API. Under the covers, this uses a streaming ingestion supervisor running on your Druid cluster.
Query
Your teams explore Polaris tables using data cubes and dashboards. They can set up alerts and schedule reports, and you can expose Druid query API endpoints via a Polaris API endpoint. This applies to both large-scale asynchronous queries (powered via SELECTs to the Druid MSQ engine) and interactive queries (powered by the Druid SQL API).
Druid’s core Apache DataSketch functions and aggregations are available through Polaris.
Apache Druid’s query lanes and query prioritization are not available in Polaris.
Operations
Polaris configures metrics and logs collection, making these available to you for exploration through Polaris monitoring.
These are central to how Imply’s support and professional services teams work with you to get the right cluster size and table layout. Rather than a segment timeline, for example, our teams rely on data about query performance to inform implementations and to find opportunities to improve your Polaris implementation.
Ready to try Imply Polaris?
To get started with Imply Polaris, you can start a free trial (including $500 in free credits) or request a demo to speak with an expert. If you’re still considering whether a test is worthwhile, you may want to check out this comparison page, Polaris overview, or Polaris demo video in the meantime.
 Architecture
Architecture Deployment
Deployment Ingestion
Ingestion Modeling
Modeling Operations
Operations Development
Development


