Analyze stream data at scale
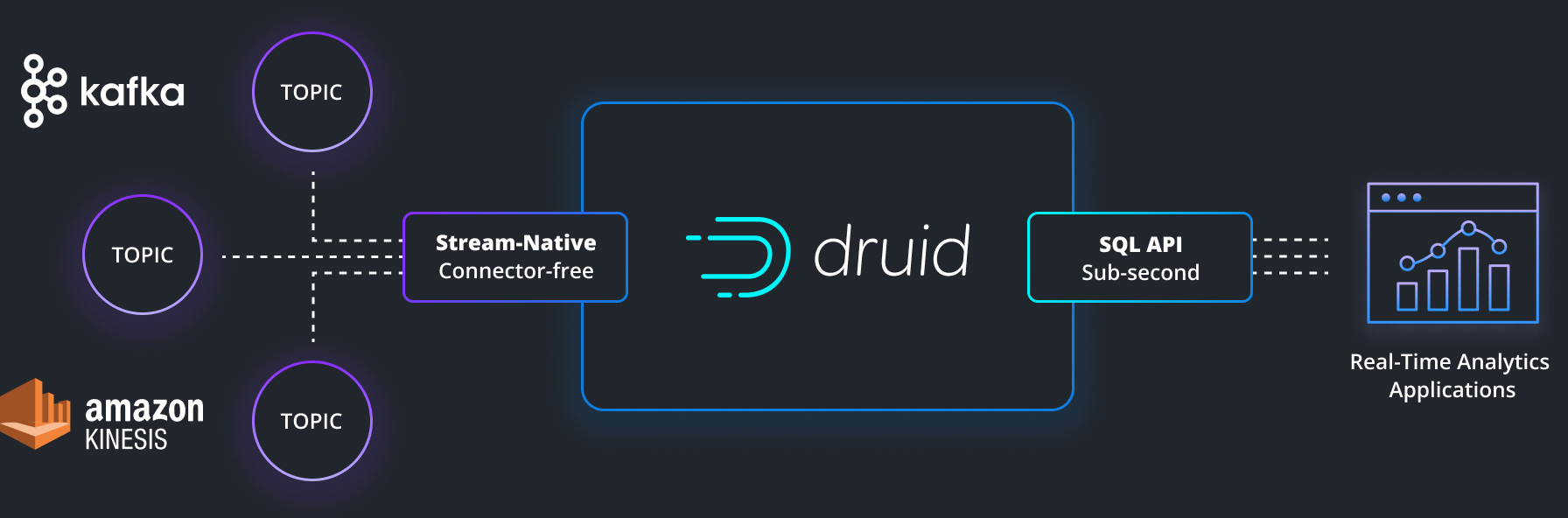
Druid was designed from the outset for rapid ingestion and immediate querying of stream data. No connectors are needed, as Druid includes inherent exactly-once ingestion for data streams using Apache Kafka® and Amazon Kinesis APIs.
Streaming analytics with Druid
Apache Druid is purpose built for stream ingestion. It ingests event-by-event, not a series of batched data files sent sequentially to mimic a stream. This means that Druid supports query-on-arrival. It’s true real-time analytics with no wait for data to be batched then delivered.
-

Massive scalability
Druid handles data streams up to millions of events per second with ease, ideal for highly dynamic data.
-

Exactly-once semantics
Druid guarantees data consistency - preventing duplicates or data loss - through its native indexing service.
-

Continuous backup
Druid ensure no data loss of streaming data as it persists data segments to deep storage automatically.
Apache Kafka
Kafka is natively integrated with Druid so there is no need for a connector. The data is loaded into Druid from a Kafka stream using Druid’s Kafka indexing service. The connection to Kafka topics is part of Druid. Define an ingestion spec with “type”: “kafka” that defines the the topic and parameters you want.
Whenever an event is added to the topic, it will immediately become available for your queries in Druid. After an interval, the events will be indexed and added to a segment, committed to both data nodes and durable deep storage. Once the event is fully committed, it is removed from the topic, so every event is written to Druid once and only once.

Apache Kafka APIs
Any data stream that supports Kafka APIs can be used for Druid stream ingestion the same as open source Kafka.
This includes:
- Confluent Enterprise
- Confluent Cloud
- Amazon Managed Services for Kafka
- Azure Event Hub
- Red Panda
- Aiven Managed Kafka
- Alibaba
- Instaclustr

Amazon Kinesis
Inherent connection to Kinesis data streams is part of Druid. Define an ingestion spec with “type”: “kinesis” that defines the the stream and parameters you want.
Whenever an event is added to the stream, it will immediately become available for your queries in Druid. After an interval, the events will be indexed and added to a segment, committed to both data nodes and durable deep storage. Once the event is fully committed, it is removed from the stream, so every event is written to Druid once and only once.

“Druid has native Kafka integration out of the box…we don't need anything to make Apache Kafka and Apache Druid work together. It just works.”