Pivot is Imply’s GUI for building, sharing, and embedding real-time data visualizations. This facilitates data exploration, helps teams better understand their environment, performance, and user behavior, and informs strategy and decision making.
This guide will demonstrate how to connect Pivot to multiple Imply clusters in order to improve data analysis across various deployments, assist teams in gaining a broader perspective into data, and enable flexible, open-ended data exploration.
Please note that this capability isn’t available on open source Apache Druid clusters—only on paid Imply clusters.
Before we begin, you’ll need…
- Multiple Druid clusters: Each cluster should be fully operational and accessible.
- Pivot: Installed and configured with access to a single Druid cluster.
- A basic understanding of Druid and Pivot: Familiarity with Druid data models and Pivot functionalities is crucial.
Procedure
- Collect the connection details for any additional clusters you would like to add to Pivot. You will need:
- host: Query node hostname or IP
- username: Username for connection to Druid
- password: The password for username
- protocol: If the connection is not TLS protected, use plain. If TLS protected, use tls-loose
- Add the configuration for each Druid cluster in the Pivot section of Imply Manager Service Properties using the prefix fixedConnections. <cluster number>.<property>
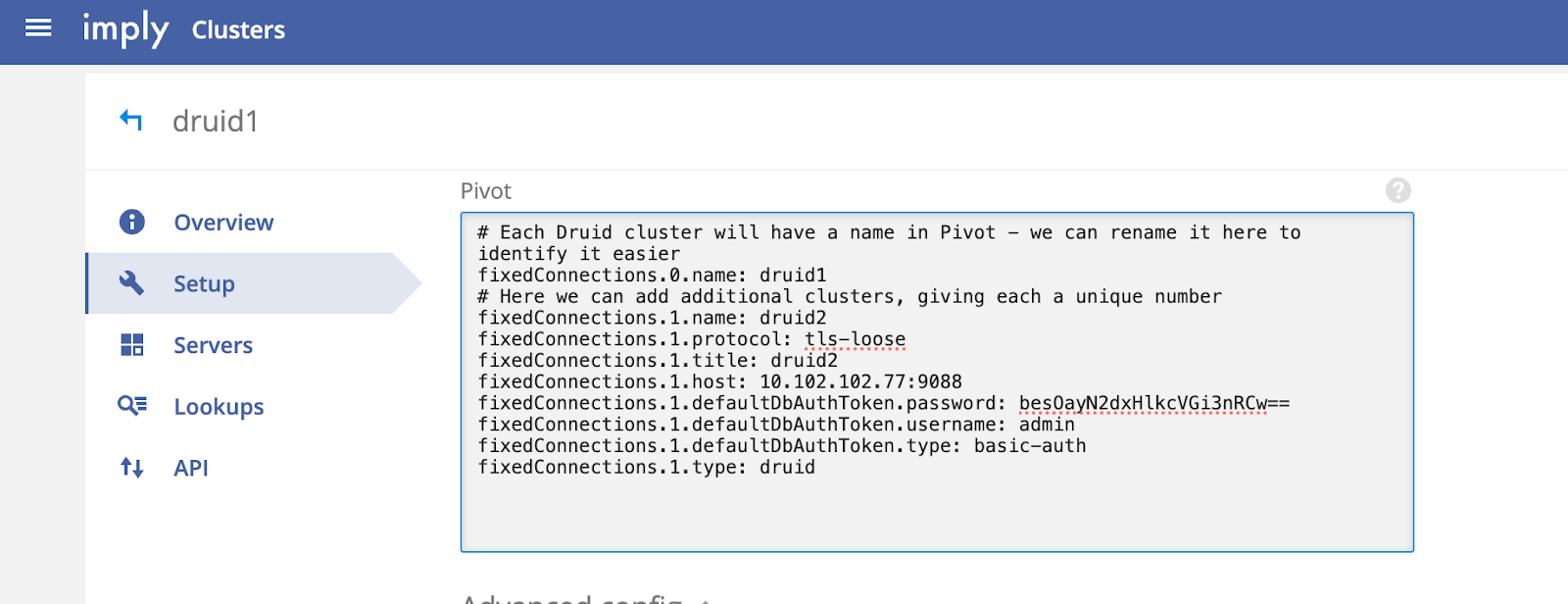
Example of Pivot Service Properties with two clusters:
# Each Druid cluster will have a name in Pivot - we can rename it here to identify it easier
fixedConnections.0.name: druid1
# Here we can add additional clusters, giving each a unique number
fixedConnections.1.name: druid2
fixedConnections.1.protocol: tls-loose
fixedConnections.1.title: druid2
fixedConnections.1.host: druid2broker:9088
fixedConnections.1.defaultDbAuthToken.password: secretPassword
fixedConnections.1.defaultDbAuthToken.username: admin
fixedConnections.1.defaultDbAuthToken.type: basic-auth
fixedConnections.1.type: druidAccessing different clusters in Pivot
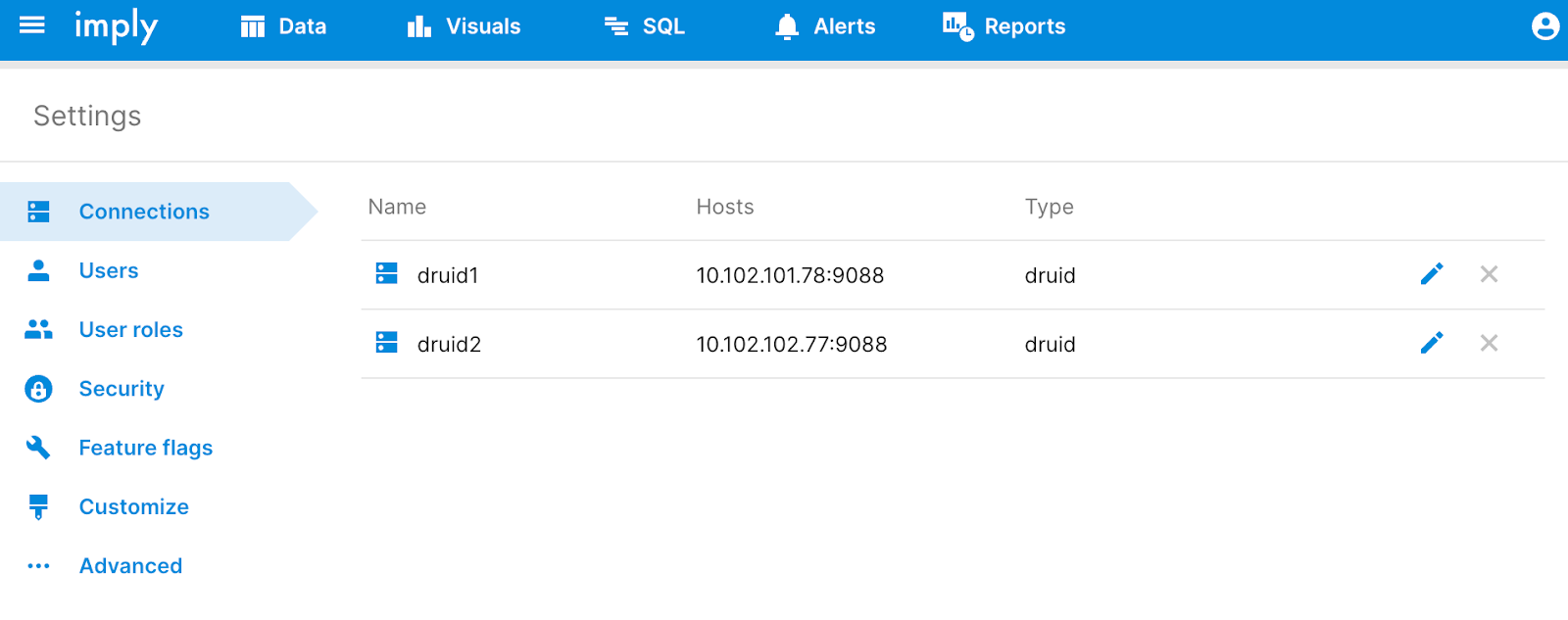
Once the changes have been implemented in Manager, we can access Pivot to see the newly configured Druid clusters. In Settings → Connections we can now see multiple Connections listed.
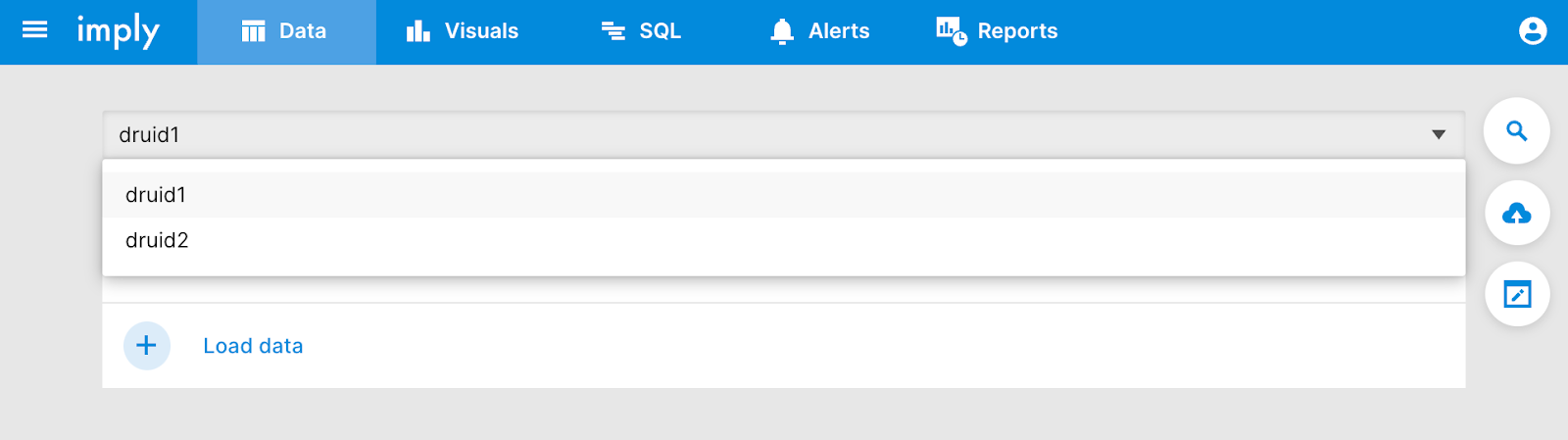
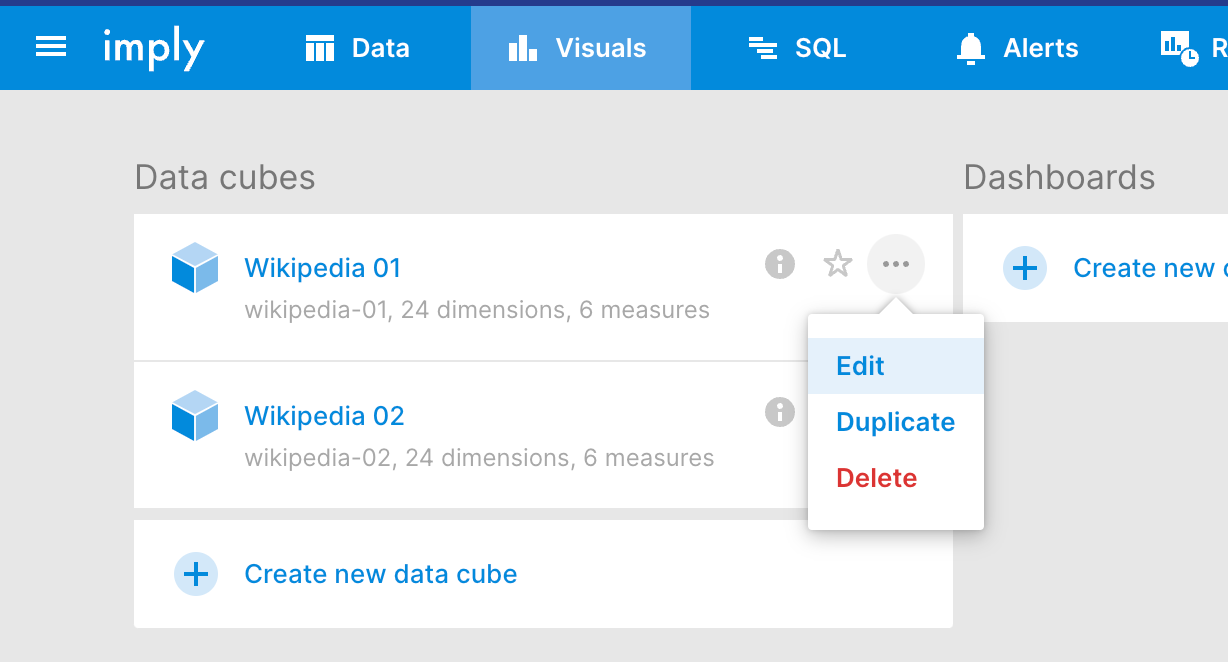
Configuring new data cubes
When configuring new data cubes, we are given a drop-down menu to select which cluster to create the data cubes from.
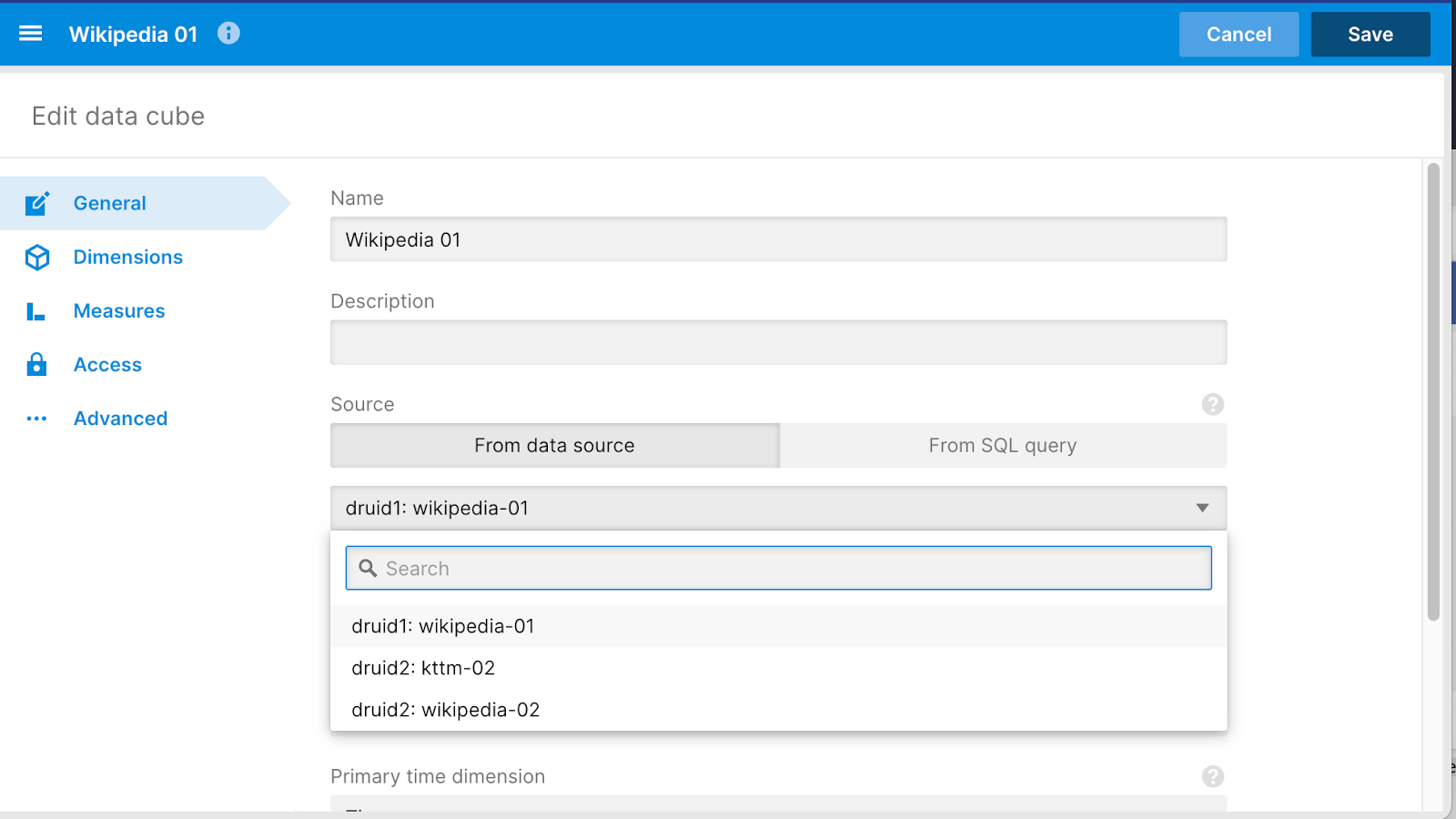
Editing existing data cubes
When editing existing data cubes, we are now shown which cluster the cube is associated with.
Additional tips
- Consider load balancing and fault tolerance when configuring your Pivot connection pool.
- Implement authentication and authorization if your Druid clusters require it.
- Use descriptive cluster names to easily navigate between them in Pivot.
Troubleshooting
- Ensure all Druid clusters are accessible and properly configured.
- Verify the entries in your /opt/imply/conf/pivot/config.yaml are correct after updating Manager.
- Check Pivot logs /mnt/var/sv/pivot/current for any connection errors or warnings.
By following these steps, you can connect Pivot to multiple Imply clusters and unlock the power of cross-cluster data analysis. Take advantage of better visibility into your data, more accurate analysis, more flexible data exploration, and ultimately, improved decision making.
 Architecture
Architecture Deployment
Deployment Ingestion
Ingestion Modeling
Modeling Operations
Operations Development
Development


