Technical comparisons to other databases
With many databases available, figuring out where and why to use Druid or others might not be so apparent. Let’s make it easy.
There’s a new use case where analytics meets applications
The database has to handle the scale needed for analytics with the performance needed for applications – and be built for streaming data.
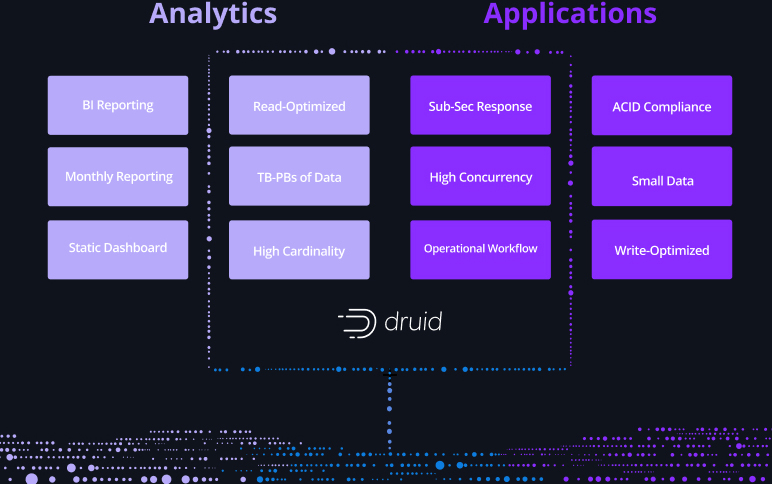
Other databases weren’t built for real-time analytics applications
-
Snowflake
If you need a general purpose analytics engine for business intelligence and reporting, Snowflake’s a great fit. But trying to use it for interactive slice and dice at scale means waiting and escalations.
Learn more about Druid or Snowflake -
Amazon Redshift
Like Snowflake, Redshift was built for traditional BI and infrequent reports. Not having multi-level indexing and time-based partitioning means inefficient compute with more data processed than necessary.
Learn more about Druid or Redshift -
Clickhouse
Like Druid, Clickhouse is fast. Where they differ is database management at scale and stream data ingestion. And without deep storage, high availability and durability are manual operations in Clickhouse.
Learn more about Druid or Clickhouse -
PostgreSQL and MySQL
These are fast and capable relational databases for general purpose workloads, predominantly transactional processing. But for analytics at scale, they can bottleneck user-facing queries.
Learn more about Druid or PostgreSQL -
Google BigQuery
Like other cloud data warehouses, BigQuery is a great analytics engine for infrequent data and batch ingestion. But it’s optimized for infrequent use, and therefore costly with high concurrency.
Learn more about Druid or Google BigQuery -
Elasticsearch
Fast for full-text search, Elasticsearch is often used with JSON data. However, when used for analytics at scale users cite ingestion, performance challenges, and stability issues.
Learn more about Druid or Elasticsearch